Correlations at Sea#
Correlation analysis, despite its simplicity and many shortcomings, remains a centerpiece of empirical analysis in many fields, particularly the paleosciences. Computing correlations is trivial enough; the difficulty lies in properly assessing their significance. Of particular importance are four considerations:
Persistence, which violates the standard assumption that the data are independent (which underlies the classical test of significance implemented, e.g. in Excel).
Time irregularities, for instance comparing two records with different time axes, possibly unevenly spaced (which standard software cannot deal with out of the box)
Age uncertainties, for example comparing two records, each with an ensemble of plausible chronologies (generated, for instance, by a Bayesian age model)
Test multiplicity aka the “Look Elsewhere effect”, which states that repeatedly performing the same test can result in unacceptably high type I error (accepting correlations as significant, when in fact they are not). This arises e.g. when correlating a paleoclimate record with an instrumental field, assessing significance at thounsands of grid points at once, or assessing significance within an age ensemble.
In this notebook we reproduce the study of Hu et al, 2017, particularly the example of their section 4, which illustrates several of these pitfalls at once. The example illuminates the issue of relying too strongly on correlations between a paleoclimate record and an instrumental field to interpret the record. Before we start, a disclaimer: the studies investigated in this paper are by no means isolated cases. They just happened to be cases that we knew about, and thought deserved a second look in light of more rigorous statistics. The same study could have been written by subsituting any number of other records interpreted, wholly or in part, on the basis of correlations. Accordingly, what follows should not be viewed as an indictment of a particularly study or group of authors, rather, at how easy it is by the best-intentioned scientists to get fooled by spurious correlations. Accordingly, Pyleoclim facilitates an assessment of correlations that deals with all these cases, makes the necessary data transformations transparent to the user, and allows for one-line plot commands to visualize the results.
Data#
The example uses the speleothem record of McCabe-Glynn et al. (2013) from Crystal Cave, California, in the Sequoia National Forest. Of interest to us is the \(\delta^{18}O\) record, which the authors interpret as reflecting sea-surface temperatures (SST) in the Kuroshio Extension region of the West Pacific. This is a strong claim, given that no mechanistic link is proposed, and relies entirely on an analysis of correlations between the record and instrumental SST.
Data Exploration#
We start by loading a few useful packages:
import matplotlib.pyplot as plt
import numpy as np
import xarray as xr
import warnings
warnings.filterwarnings('ignore')
import pyleoclim as pyleo
from pylipd import LiPD
pyleo.set_style('web') # set the visual style
We can use the PyliPD package to open the file and select the appropriate timeseries.
D = D = LiPD()
D.load('./data/Crystal.McCabe-Glynn.2013.lpd')
df = D.get_timeseries_essentials()
df.head()
Loading 1 LiPD files
100%|█████████████████████████████████████████████| 1/1 [00:00<00:00, 2.44it/s]
Loaded..
| dataSetName | archiveType | geo_meanLat | geo_meanLon | geo_meanElev | paleoData_variableName | paleoData_values | paleoData_units | paleoData_proxy | paleoData_proxyGeneral | time_variableName | time_values | time_units | depth_variableName | depth_values | depth_units | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Crystal.McCabe-Glynn.2013 | Speleothem | 36.59 | -118.82 | 1386.0 | d18o | [-8.01, -8.23, -8.61, -8.54, -8.6, -9.08, -8.9... | permil | None | None | age | [2007.7, 2007.0, 2006.3, 2005.6, 2004.9, 2004.... | yr AD | depth | [0.05, 0.1, 0.15, 0.2, 0.25, 0.3, 0.35, 0.4, 0... | mm |
Let’s create a GeoSeries object:
cc = pyleo.GeoSeries(time=df['time_values'][0], value = df['paleoData_values'][0], lat = df['geo_meanLat'][0],
lon = df['geo_meanLon'][0], elevation = df['geo_meanElev'][0], time_name= 'Age', time_unit = df['time_units'][0],
value_name = '$\delta^{18}O$', value_unit = u'\u2030', label = df['dataSetName'][0],
archiveType = df['archiveType'][0], depth = df['depth_values'][0],
depth_name = df['depth_variableName'][0], depth_unit = df['depth_units'],verbose = False)
Let’s do a quick plot to check that we have what we want:
fig, ax = cc.plot()
Let’s create a dashboard, which provides an overview of the timeseries, the location of the record and spectral peaks.
cc.dashboard()
Performing spectral analysis on individual series: 100%|█| 200/200 [00:15<00:00,
(<Figure size 1100x800 with 4 Axes>,
{'ts': <Axes: xlabel='Time [yr AD]', ylabel='$\\delta^{18}O$ [‰]'>,
'dts': <Axes: xlabel='Counts'>,
'map': {'map': <GeoAxes: xlabel='lon', ylabel='lat'>},
'spec': <Axes: xlabel='Period [yr]', ylabel='PSD'>})
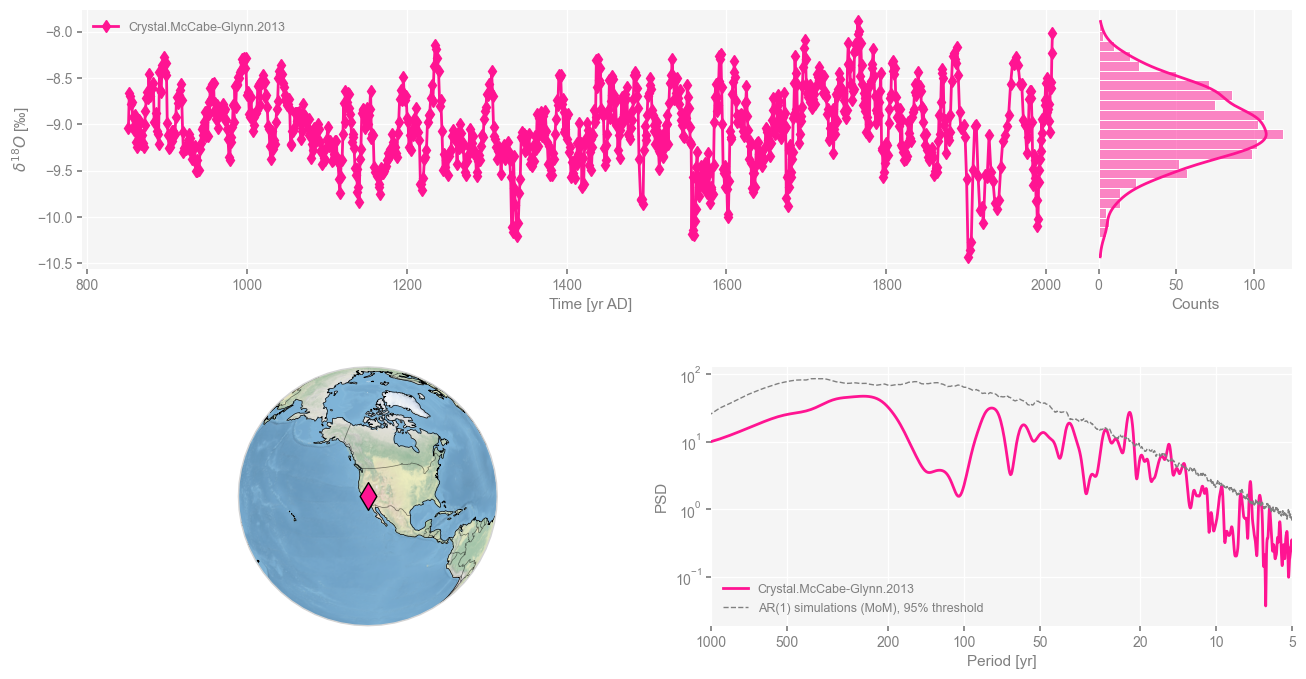
This is a very high resolution record, with near-annual spacing (check it), and a broadly red spectrum that exhibits a number of spectral peaks at interannual and decadal scales.
Sea-surface Temperature#
The original paper correlated the above record against the Kaplan SST dataset. In this notebook we instead use the HadSST4 dataset (Morice et al, 2012), which is more up to date, and which we first download via wget. (~8Mb)
!wget https://www.metoffice.gov.uk/hadobs/hadsst4/data/netcdf/HadSST.4.0.1.0_median.nc
!mv HadSST.4.0.1.0_median.nc ./data
--2024-07-22 09:29:37-- https://www.metoffice.gov.uk/hadobs/hadsst4/data/netcdf/HadSST.4.0.1.0_median.nc
Resolving www.metoffice.gov.uk (www.metoffice.gov.uk)... 23.42.200.119
Connecting to www.metoffice.gov.uk (www.metoffice.gov.uk)|23.42.200.119|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 8910040 (8.5M) [application/x-netcdf]
Saving to: ‘HadSST.4.0.1.0_median.nc’
HadSST.4.0.1.0_medi 100%[===================>] 8.50M 5.14MB/s in 1.7s
2024-07-22 09:29:39 (5.14 MB/s) - ‘HadSST.4.0.1.0_median.nc’ saved [8910040/8910040]
Next we load it via the excellent xarray package.
ds = xr.open_dataset('./data/HadSST.4.0.1.0_median.nc')
print(ds)
<xarray.Dataset> Size: 22MB
Dimensions: (time: 2093, latitude: 36, longitude: 72, bnds: 2)
Coordinates:
* time (time) datetime64[ns] 17kB 1850-01-16T12:00:00 ... 2024-0...
* latitude (latitude) float64 288B -87.5 -82.5 -77.5 ... 77.5 82.5 87.5
* longitude (longitude) float64 576B -177.5 -172.5 ... 172.5 177.5
Dimensions without coordinates: bnds
Data variables:
tos (time, latitude, longitude) float32 22MB ...
time_bnds (time, bnds) datetime64[ns] 33kB ...
latitude_bnds (latitude, bnds) float64 576B ...
longitude_bnds (longitude, bnds) float64 1kB ...
Attributes:
comment:
history: Converted to netcdf today
institution: Met Office
reference: Kennedy et al. (2019), https://www.metoffice.gov.uk/hadobs/...
source: surface observation
title: Ensemble-median sea-surface temperature anomalies from the ...
version: HadSST.4.0.1.0
Conventions: CF-1.7
As an example, let’s only consider the Northern Hemisphere Pacific Ocean. For practicality, let’s first adjust the coordinate system so that longitude is expressed from 0 to 360 degrees instead of 180W to 180E:
ds_rolled = ds.assign_coords(longitude=(ds.longitude % 360)).sortby(ds.longitude)
ds_rolled
<xarray.Dataset> Size: 22MB
Dimensions: (time: 2093, latitude: 36, longitude: 72, bnds: 2)
Coordinates:
* time (time) datetime64[ns] 17kB 1850-01-16T12:00:00 ... 2024-0...
* latitude (latitude) float64 288B -87.5 -82.5 -77.5 ... 77.5 82.5 87.5
* longitude (longitude) float64 576B 2.5 7.5 12.5 ... 347.5 352.5 357.5
Dimensions without coordinates: bnds
Data variables:
tos (time, latitude, longitude) float32 22MB ...
time_bnds (time, bnds) datetime64[ns] 33kB ...
latitude_bnds (latitude, bnds) float64 576B ...
longitude_bnds (longitude, bnds) float64 1kB ...
Attributes:
comment:
history: Converted to netcdf today
institution: Met Office
reference: Kennedy et al. (2019), https://www.metoffice.gov.uk/hadobs/...
source: surface observation
title: Ensemble-median sea-surface temperature anomalies from the ...
version: HadSST.4.0.1.0
Conventions: CF-1.7Now let’s select the needed data:
ds_sel = ds_rolled.sel(longitude=slice(120,280),latitude=slice(0,90))
ds_sel
<xarray.Dataset> Size: 5MB
Dimensions: (time: 2093, latitude: 18, longitude: 32, bnds: 2)
Coordinates:
* time (time) datetime64[ns] 17kB 1850-01-16T12:00:00 ... 2024-0...
* latitude (latitude) float64 144B 2.5 7.5 12.5 17.5 ... 77.5 82.5 87.5
* longitude (longitude) float64 256B 122.5 127.5 132.5 ... 272.5 277.5
Dimensions without coordinates: bnds
Data variables:
tos (time, latitude, longitude) float32 5MB ...
time_bnds (time, bnds) datetime64[ns] 33kB ...
latitude_bnds (latitude, bnds) float64 288B ...
longitude_bnds (longitude, bnds) float64 512B ...
Attributes:
comment:
history: Converted to netcdf today
institution: Met Office
reference: Kennedy et al. (2019), https://www.metoffice.gov.uk/hadobs/...
source: surface observation
title: Ensemble-median sea-surface temperature anomalies from the ...
version: HadSST.4.0.1.0
Conventions: CF-1.7Pitfall #1: Persistence#
Persistence is the tendency of many geophysical timeseries (particularly in paleoclimatology) to show some kind of memory: consecutive observations tend to resemble each other, resulting in timeseries that have fairly broad trends and low-frequency fluctuations, and comparatively little high-frequency fluctuations. This has an important consequence: the standard assumption of independence, which undergirds much of frequentist statistics, is violated in this case. In a timeseries with \(n\) fully independent observations (e.g. white noise), the degrees of freedom for the variance are \(DOF = n -1\) But if memory is present, this number can be drastically reduced.
Let us look at a random location and build some intuition. First, we need to compute monthly anomalies and annualize them. xarray makes that easy (four lines of code plus another line for plotting), so let’s look at the result:
st = ds['tos'].sel(latitude=32.5, longitude = 142.5, method='nearest') # 32.5N 142.5W near Kuroshio Extension
climatology = st.groupby("time.month").mean("time")
anomalies = st.groupby("time.month") - climatology
st_annual = anomalies.groupby("time.year").mean("time")
st_annual.plot(figsize=[12, 6])
[<matplotlib.lines.Line2D at 0x326513150>]
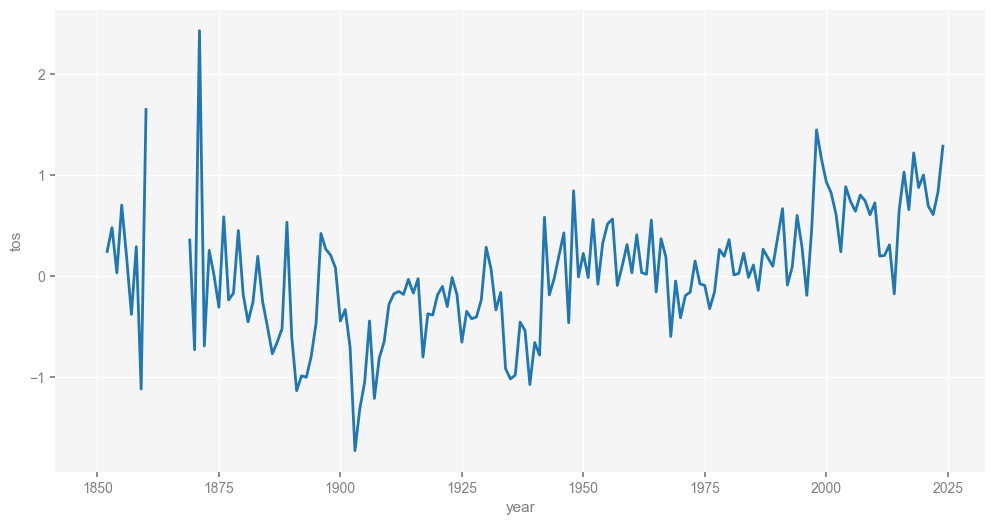
Notice the coverage gaps in the 1860s. This, and the fact that the Crystal Cave chronology is not uniformly spaced, would ordinarily make it challenging to compare the two series, requiring some form of interpolation or binning. Pyleoclim does all this under the hood, provided the temperature data are turned into a Series object, which is a quick operation:
stts = pyleo.Series(time=st_annual.coords['year'].values,
time_unit ='year CE',
value=st_annual.values, value_name='SST',
value_unit = 'C', label='HadCRUT4, 32.5N, 142.5E')
NaNs have been detected and dropped.
Time axis values sorted in ascending order
Now we can compute correlations with the Crystal Cave record.
corr_res = stts.correlation(cc, seed = 2333)
print(corr_res.r)
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2874.
0.3235963792817965
Quite a few things happened here. First, pyleoclim was smart enough to figure out a common timespan between the two records, and used linear interpolation to align the two timeseries on a common axis. Most users will be grateful not to have to do this explcitly, but the process can be customized (see Timeseries alignment).
The correlation is \(r=0.324\), and the natural question is: “Is this number significant (i.e. unusual)?” The standard way to assess this is with \(t\)-test using the test statistic: $\(T = \frac{r \sqrt{n-2}}{\sqrt{1-r^2}}\)\( (see e.g. Wilks, 2011) If we plug in the values of \)r\( and \)n$, we get:
ccs = cc.slice([1854,2020])
n = len(ccs.time)
nu = n-2
r = corr_res.r
T = r *np.sqrt(nu)/(np.sqrt(1-r**2))
print("The test statistic is "+ str(T))
The test statistic is 3.586899835725328
Under standard assumptions (the data are independent and identically distributed), \(T\) follows Student’s \(t\) distribution. If we make the same assumption and use the \(t\) distribution from SciPy, we can readily compute the p-value (i.e. the probability to observe a test statistic at least as large as this one, under the null distribution):
from scipy.stats import t
pval = 1-t.cdf(T,nu)
print("The p-value is {:10.2e}".format(pval)) # express in exponential notation
The p-value is 2.50e-04
In other words, using the classic test for the significance of correlations “out of the box”, one would conclude that SST at 42N, 164E shares so much similarity with the Crystal Cave record that there are about 2 chances in 10,000 that this could have happened randomly. In other words, it looks rather significant.
However, this test (which is the one that most computing packages, including Excel, implement by default) is not appropriate here, as the theory only applies to data that are independent and indentically distributed (“IID”). Independence means that consecutive observations have no predictive power over each other, which is true neither of the Crystal Cave nor the instrumental target. That is to say: because temperature in one year tends to resemble temperature in the previous or following year (same for \(\delta^{18}O\)), the data are anything but independent. We will quantify this dependence, and its consequences, below.
The full result of the Pyleoclim correlation() command looks like this:
print(corr_res)
correlation p-value signif. (α: 0.05)
------------- --------- -------------------
0.323596 0.14 False
That is, the correlation value ships with an estimate of the p-value and a boolean flag (True/False) stating whether or not it is below the test level \(\alpha\). However, the p-value here is estimated to be 14% ('p': 0.14), and therefore the correlation is not deemed significant ('signif': False) at the 5% level ('alpha': 0.05). How did pyleoclim arrive at such a different conclusion than the \(2.5 \times 10^{-4}\) seen just above?
Null Models#
There are in fact 3 ways to make this determination in Pyleoclim. While the standard null model for correlations in the statistical literature is the IID model, we have just seen that it is violated by the persistence of many timeseries, particularly the ones shown above. The package does implements the classical T-test, but it is adjusted for the loss of degrees of freedom due to persistence as per Dawdy & Matalas (1964):
corr_ttest = stts.correlation(cc,statistic='pearsonr',method='ttest')
print(corr_ttest)
correlation p-value signif. (α: 0.05)
------------- --------- -------------------
0.323596 0.16 False
As a result, the the p-value for the test is now 16%, far above the \(2.4 \times 10^{-4}\) it would be under the IID assumption.
The next option compares the observed correlation to the distribution of correlations with (by default) 1000 randomly-generated autoregressive (AR(1)) timeseries with the same persistence parameters as the original series, as measured by the lag-1 autocorrelation. This model is parametric and it preserves the persistence properties of each series:
corr_isopersist = stts.correlation(cc,statistic='pearsonr',method='ar1sim', seed = 2333)
print(corr_isopersist)
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2891.
correlation p-value signif. (α: 0.05)
------------- --------- -------------------
0.323596 0.11 False
Because this is a simulation-based method, the result will depent on the number of simulations, nsim. Upping nsim ensures more consistent results, though in this case the result does not change:
corr_isopersist = stts.correlation(cc,statistic='pearsonr',method='ar1sim', seed = 2333, number = 2000)
print(corr_isopersist)
Evaluating association on surrogate pairs: 100%|█| 2000/2000 [00:00<00:00, 2903.
correlation p-value signif. (α: 0.05)
------------- --------- -------------------
0.323596 0.12 False
We see that the p-value changes subtly between these two cases, but not enough to change the result (the correlation is non significant either way). However, to ensure that these sampling issues won’t affect the reproducibility of the results, we specify a random seed. Note that the difference between “significant” and “not significant” p-values is not itself statistically significant (Gelman & Stern, 2006).
The last null model method is phaseran, which phase-randomizes the original signals, thereby preserving the spectrum of each series but scrambling phase relations between the signals. This (non-paramettric) method was first proposed by Ebisuzaki (1997), and is called phaseran because it leaves the spectrum (and therefore the autocorrelation function) intact. Since, this is also a simulation method, one can also play with the number of simulations, as done here:
corr_isospec = stts.correlation(cc,statistic='pearsonr',method='phaseran', seed = 4343, number = 2000)
print(corr_isospec)
Evaluating association on surrogate pairs: 100%|█| 2000/2000 [00:00<00:00, 2830.
correlation p-value signif. (α: 0.05)
------------- --------- -------------------
0.323596 0.14 False
We see that this resulted is a modestly different p-value, but again one above 5%, which leads to rejection of the null.
In this case, the three methods concur that the correlation is insignificant, though we encourage users to play with these methods in case they obtain results close to the test-level, to discourage p-hacking temptations.
Timeseries Alignment#
As mentioned earlier, the SST and Crystal Cave series are on different time axes, and Pyleoclim automated the process of aligning them, doing so under the hood so users can focus on doing science. However, it is useful to understand what is happening and how it can be customized, in case this makes a difference to the analysis. Like other Pyleoclim methods designed to compare timeseries, correlation() relies on the MultipleSeries.common_time() method for alignment. The method implements three strategies for timeseries alignment:
interpolation
binning
Gaussian kernel smoothing
To explore it, let us first create a MultipleSeries object gathering those two series:
ms = pyleo.MultipleSeries([cc,stts])
ms.stackplot()
(<Figure size 640x480 with 3 Axes>,
{0: <Axes: ylabel='$\\delta^{18}O$ [‰]'>,
1: <Axes: ylabel='SST [C]'>,
'x_axis': <Axes: xlabel='Time [year CE]'>})
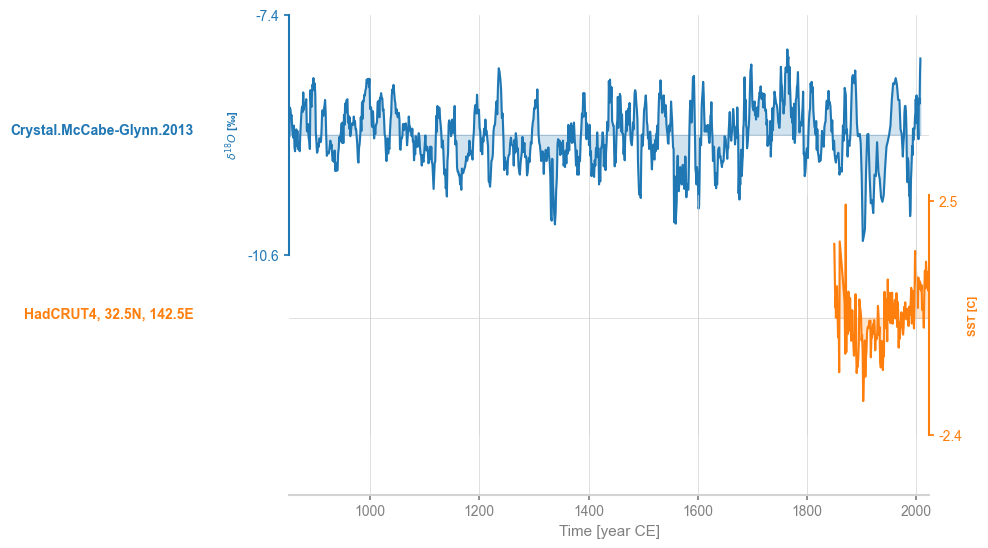
By default, common_time() will implement linear interpolation.
msi = ms.common_time()
fig, ax = msi.stackplot()
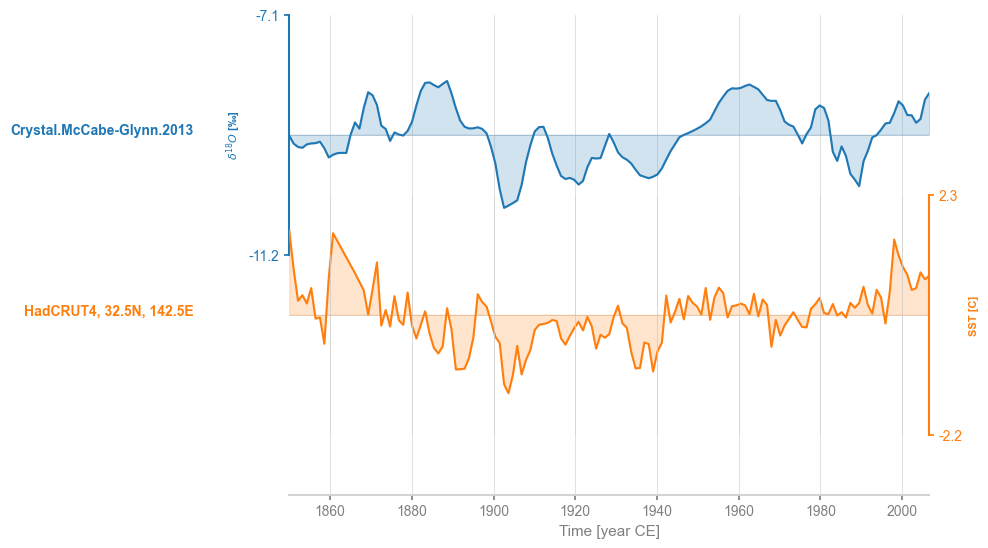
It is easy to verify that the two series are indeed on the same axis:
msi.series_list[0].time == msi.series_list[1].time
array([ True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True])
To see how the interpolation changed the original series, we can superimpose the original series as dots on top of this stackplot:
fig, ax = msi.stackplot(labels=None, fill_between_alpha=0.1)
cc.plot(ax=ax[0],marker='o',linestyle='',xlabel='',alpha=0.6)
stts.plot(ax=ax[1],marker='o',linestyle='',color='C1',xlabel='', alpha=0.6)
<Axes: ylabel='SST [C]'>
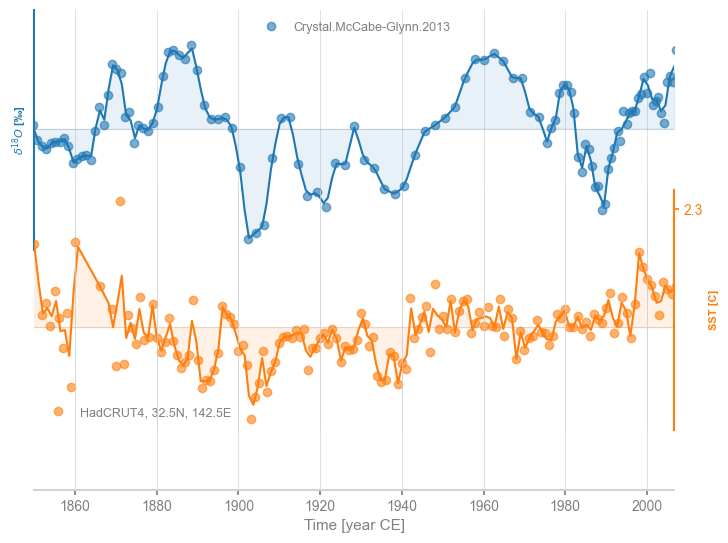
We see that interpolation left the Crystal Cave record relatively unchanged, except near the end where resolution is very high. For the HadCRUT4 data, the effect is most noticeable in the 1870s, where there is a gap in data coverage. This could be customized: both the type of interpolation (e.g. linear, quadratic) and the grid step, are customizable (see the documentation.
As an example, we could use cubic spline interpoliation, which carries the well-known risk of overfitting, thereby creating unrealistic excursions away from observations:
msi = ms.common_time(method='interp',interp_type = 'cubic')
fig, ax = msi.stackplot(labels=None, fill_between_alpha=0.1)
cc.plot(ax=ax[0],marker='o',linestyle='',xlabel='',alpha=0.6)
stts.plot(ax=ax[1],marker='o',linestyle='',color='C1',xlabel='', alpha=0.6)
<Axes: ylabel='SST [C]'>
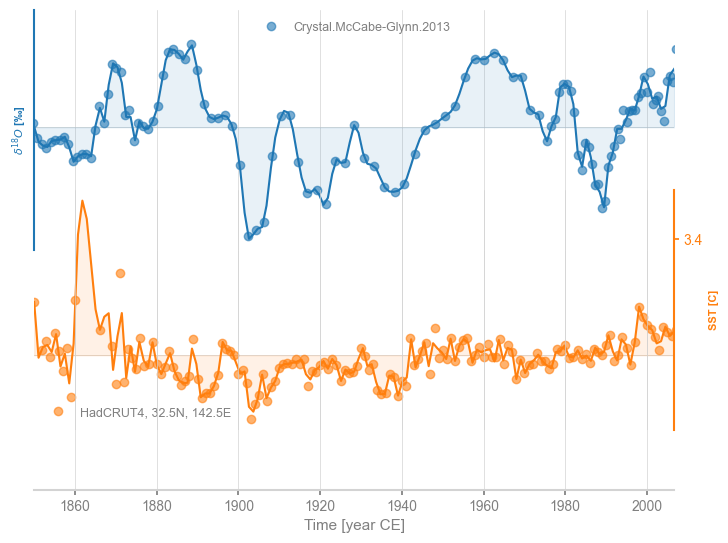
Another option is binning, which tends to coarse-grain more, as it will default to the largest time spacing observed in either series to avoid empty bins:
msb = ms.common_time(method='bin')
fig, ax = msb.stackplot(labels=None, fill_between_alpha=0.1)
cc.plot(ax=ax[0],marker='o',linestyle='',xlabel='',alpha=0.6)
stts.plot(ax=ax[1],marker='o',linestyle='',color='C1',xlabel='', alpha=0.6)
<Axes: ylabel='SST [C]'>
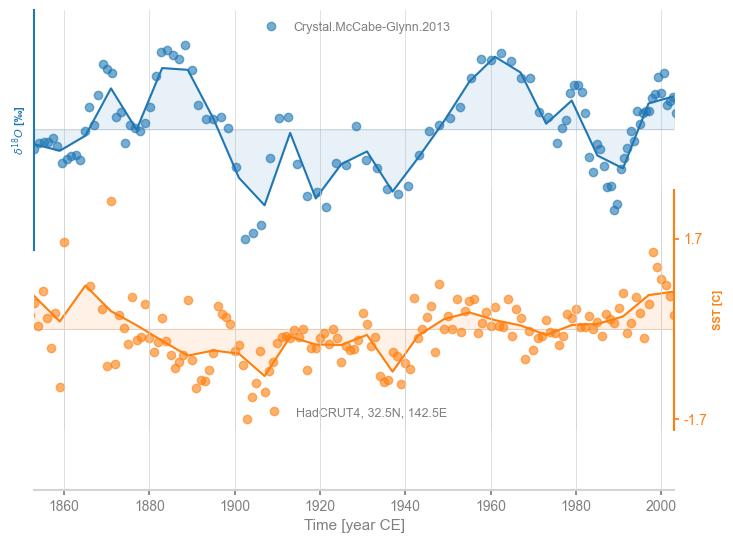
Lastly, one may request a gaussian kernel (Rehfeld & Kurths, 2014), which by default uses a bandwidth of 3:
msg = ms.common_time(method='gkernel')
fig, ax = msg.stackplot(labels=None, fill_between_alpha=0.1)
cc.plot(ax=ax[0],marker='o',linestyle='',xlabel='',alpha=0.6)
stts.plot(ax=ax[1],marker='o',linestyle='',color='C1',xlabel='', alpha=0.6)
<Axes: ylabel='SST [C]'>
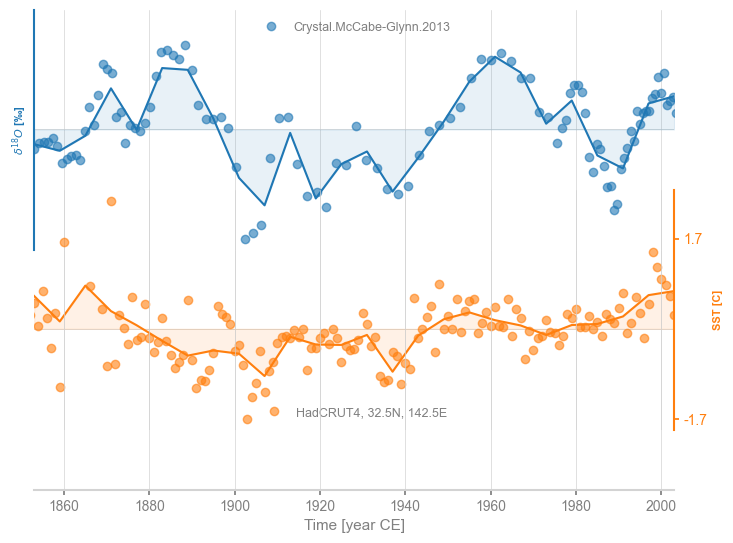
It is easy to change the bandwidth \(h\):
msg = ms.common_time(method='gkernel', h = 0.5)
fig, ax = msg.stackplot(labels=None, fill_between_alpha=0.1)
cc.plot(ax=ax[0],marker='o',linestyle='',xlabel='',alpha=0.6)
stts.plot(ax=ax[1],marker='o',linestyle='',color='C1',xlabel='', alpha=0.6)
<Axes: ylabel='SST [C]'>
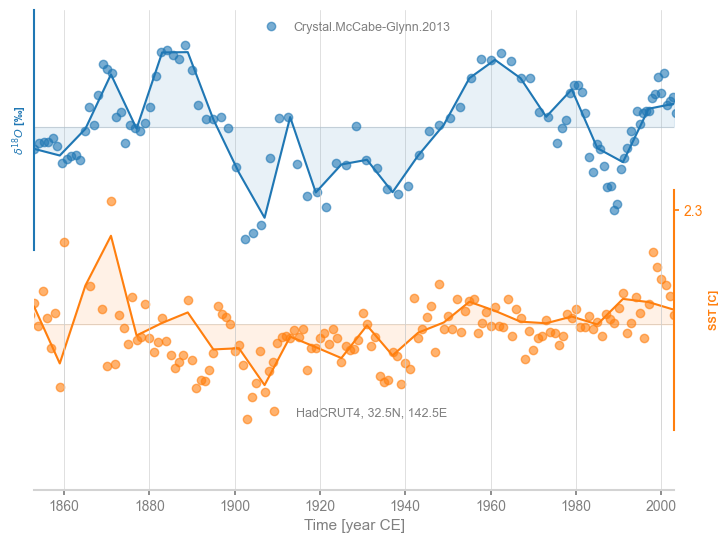
The Gaussian kernel method is quite conservative, and typically uses the coarsest possible resolution.
At the level of correlations, users may specify how they wish to perform this time alignment via the common_time_kwargs dictionary, like so:
corr_isospec = stts.correlation(cc,statistic='pearsonr',method='phaseran', number = 2000,
common_time_kwargs = {'method':'interp','interp_type':'cubic'}, seed = 4343)
print(corr_isospec)
Evaluating association on surrogate pairs: 100%|█| 2000/2000 [00:00<00:00, 2785.
correlation p-value signif. (α: 0.05)
------------- --------- -------------------
0.187768 0.36 False
We see that the type of interpolation was somewhat consequential here, lowering the original correlation quite a bit, but this does not change the result. If this low-level task turns out to affect the analysis, it is prudent to take a peak “under the hood” as we did here, and visualize how time series alignment affects the original series. In most instances, however, this should not greatly affect the outcome.
Note: in the case of the T-test, it would be sufficient to put the timeseries on the same time axis, but that this axis need not be evenly spaced. This is not implemented here.
Pitfall #2: Multiple Hypothesis Testing#
The previous section shows how to properly assess significance at a single location. The situation becomes more complex as one conducts a similar test for an entire field. To see why, let us recursively carry out the same test as above at all grid points. For this, we need not only to loop over grid points, but also store the p-values for later analysis. To save time, we’ll use the ttest option for correlation(), knowing that it is rather approximate. Also, we need to exclude points that have too few observations. The loop below achieves that.
nlon = len(ds_sel['longitude'])
nlat = len(ds_sel['latitude'])
pval = np.empty((nlon,nlat)) # declare array to store pvalues
corr = np.empty_like(pval) # declare empty array of identical shape
alpha = 0.05
slon, slat = [], [];
for ji in range(nlon):
print("Computing correlations at " + str(ds_sel.longitude[ji].values) + 'E')
for jj in range(nlat):
st = ds_sel['tos'][:,jj,ji]
climatology = st.groupby("time.month").mean("time")
anomalies = st.groupby("time.month") - climatology
st_annual = anomalies.groupby("time.year").mean("time")
# test if at least 100 non-NaNs
noNaNs = len(np.where(np.isnan(st_annual) == False)[0]) # number of valid years
sstvar = st_annual.var()
if noNaNs >= 100 and sstvar >= 0.01:
sttb = pyleo.Series(time=st_annual.coords['year'].values,
time_unit ='year CE',
value=st_annual.values,
value_unit = 'C', verbose=False)
corr_res = sttb.correlation(cc, method='ttest')
pval[ji,jj] = corr_res.p
corr[ji,jj] = corr_res.r
if pval[ji,jj] < alpha:
slon.append(ds_sel.longitude[ji])
slat.append(ds_sel.latitude[jj])
else:
pval[ji,jj] = np.nan; corr[ji,jj] = np.nan
Computing correlations at 122.5E
Computing correlations at 127.5E
Computing correlations at 132.5E
Computing correlations at 137.5E
Computing correlations at 142.5E
Computing correlations at 147.5E
Computing correlations at 152.5E
Computing correlations at 157.5E
Computing correlations at 162.5E
Computing correlations at 167.5E
Computing correlations at 172.5E
Computing correlations at 177.5E
Computing correlations at 182.5E
Computing correlations at 187.5E
Computing correlations at 192.5E
Computing correlations at 197.5E
Computing correlations at 202.5E
Computing correlations at 207.5E
Computing correlations at 212.5E
Computing correlations at 217.5E
Computing correlations at 222.5E
Computing correlations at 227.5E
Computing correlations at 232.5E
Computing correlations at 237.5E
Computing correlations at 242.5E
Computing correlations at 247.5E
Computing correlations at 252.5E
Computing correlations at 257.5E
Computing correlations at 262.5E
Computing correlations at 267.5E
Computing correlations at 272.5E
Computing correlations at 277.5E
pvals = pval.flatten() # make the p-value array a 1D one
pvec = pvals[pvals<1] # restrict to valid probabilities as there are a few weird values.
nt = len(pvec)
print(str(nt)) # check on the final number
328
We found 328 with enough data for a meaningful comparison, and 23 locations that pass the test. Where are they? To gain insight, let us plot the correlations and indicate (by shading) which are deemed significant:
import cartopy.crs as ccrs
import cartopy.feature as cfeature
from cartopy.mpl.ticker import LongitudeFormatter, LatitudeFormatter
import seaborn as sns
land_color=sns.xkcd_rgb['light grey']
ocean_color=sns.xkcd_rgb['light grey']
fig = plt.figure(figsize=[12, 8])
ax = plt.subplot(projection=ccrs.PlateCarree(central_longitude=180))
# map
ax.add_feature(cfeature.LAND, facecolor=land_color, edgecolor=land_color)
ax.add_feature(cfeature.OCEAN, facecolor=ocean_color, edgecolor=ocean_color)
ax.coastlines()
transform = ccrs.PlateCarree()
latlon_range = (120, 280, 0, 70)
lon_min, lon_max, lat_min, lat_max = latlon_range
lon_ticks = [60, 120, 180, 240, 300]
lat_ticks = [-90, -45, 0, 45, 90]
ax.set_extent(latlon_range, crs=transform)
lon_formatter = LongitudeFormatter(zero_direction_label=False)
lat_formatter = LatitudeFormatter()
ax.xaxis.set_major_formatter(lon_formatter)
ax.yaxis.set_major_formatter(lat_formatter)
lon_ticks = np.array(lon_ticks)
lat_ticks = np.array(lat_ticks)
mask_lon = (lon_ticks >= lon_min) & (lon_ticks <= lon_max)
mask_lat = (lat_ticks >= lat_min) & (lat_ticks <= lat_max)
ax.set_xticks(lon_ticks[mask_lon], crs=transform)
ax.set_yticks(lat_ticks[mask_lat], crs=transform)
# contour
clevs = np.linspace(-0.9, 0.9, 19)
#corr_r, lon_r = rotate_lon(corr.T, lon) # rotate the field to make longitude in increasing order and convert to range (0, 360)
im = ax.contourf(ds_sel.longitude, ds_sel.latitude, corr.T, clevs, transform=transform, cmap='RdBu_r', extend='both')
# significant points
plt.scatter(x=slon, y=slat, color="purple", s=3,
alpha=1,
transform=transform)
# colorbar
cbar_pad = 0.05
cbar_orientation = 'vertical'
cbar_aspect = 10
cbar_fraction = 0.15
cbar_shrink = 0.5
cbar_title = 'R'
cbar = fig.colorbar(im, ax=ax, orientation=cbar_orientation, pad=cbar_pad, aspect=cbar_aspect,
fraction=cbar_fraction, shrink=cbar_shrink)
cbar.ax.set_title(cbar_title)
Text(0.5, 1.0, 'R')
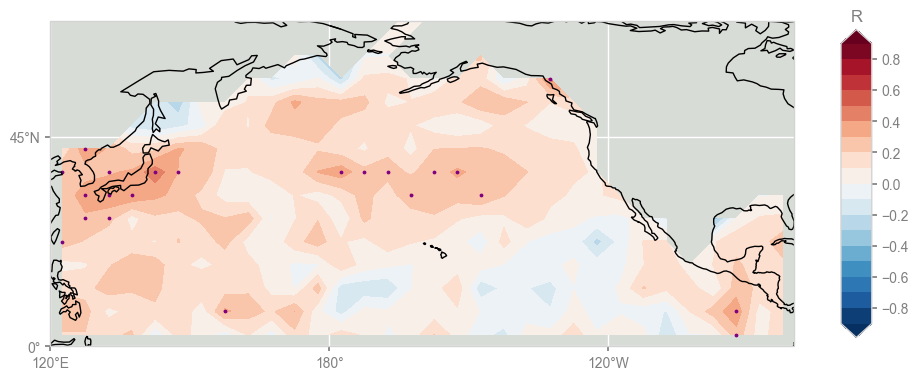
The purple dots on the map are the locations of the gridpoints where the p-values fall under 5%, and they naturally correspond to the regions of highest correlations, though (and this is suspicious) they are rather randomly scattered across the domain.
We might be tempted to declare victory and hail them as “significant”, but this is a well-known problem: the Multiple Hypothesis problem, otherwise known as the “look elsewhere” effect.
Conducting tests at the 5% level (what most people would call “the 95% confidence level”) specifically means that we expect 5% of our tests to return spurious results, just from chance alone (the so-called “type I error”). We just carried out 327 tests, so we expect \(0.05*327 \approx 16 \) of those results to be false positives, right out of the gate. So which of the 23 tests labeled as significant can we trust? One way to approach this is to rank order the p-values of all 327 tests and plot them as in Hu et al (2017), Fig 2.
#check i/m vs. p-values
indexm = np.arange(1,nt+1,1)
im = 1.0*indexm / nt
thres = 0.05*im
pvec_s = sorted(pvec)
smaller=[]
small_index=[]
larger=[]
large_index=[]
n=0
for pp in pvec_s:
if pp <=0.05:
smaller.append(pp)
small_index.append(im[n])
else:
larger.append(pp)
large_index.append(im[n])
n=n+1
f, ax = plt.subplots(figsize=(12,8))
plt.plot(im,thres,label='FDR threshold')
plt.plot(small_index,smaller,'ro',markersize=1.5,label='p-values below threshold')
plt.plot(large_index,larger,'ko',markersize=1.5,label='p-values above threshold',alpha=0.3)
plt.axhline(y=0.05,linestyle='dashed',color='silver',label='5% threshold')
plt.xlabel(r'$i/n_t$',fontsize=14)
plt.ylabel(r'$p_i$',fontsize=14)
plt.title('Correlation p-values',fontsize=14, fontweight='bold')
plt.legend()
<matplotlib.legend.Legend at 0x32b616590>
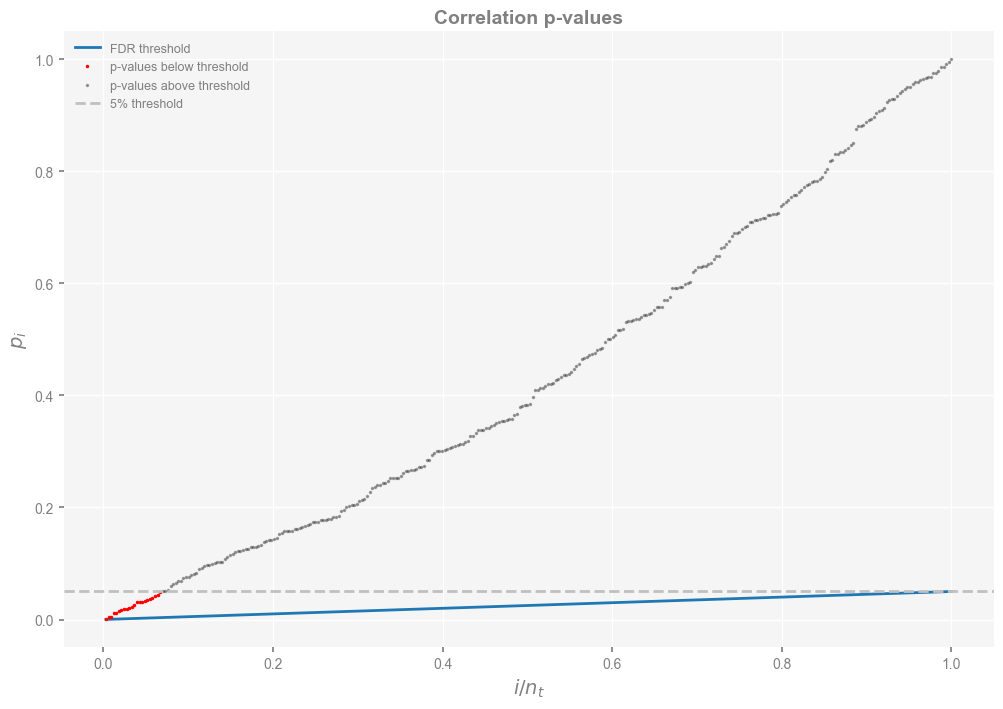
One solution to this is the False Discovery Rate (aka FDR), which was devised in a celebrated 1995 paper (Benjamini & Hochberg, 1995). The idea is to look not just for the p-values under 5% (red dots in the figure above), but for the fraction of those under the blue line, which guards against the false discoveries one expects out of repeatedly testing the same hypothesis over and over again. To access this functionality in pyleoclim , one may do:
fdr_res = pyleo.utils.correlation.fdr(pvec_s)
print(fdr_res)
None
And with this treatment, exactly 0 gridpoints pass the test.
Does this depend on our method for evaluating significance? That is easy to check:
pval2 = np.empty((nlon,nlat)) # declare array to store pvalues
corr2 = np.empty_like(pval) # declare empty array of identical shape
slon, slat = [], [];
sst_list = [] # initialize empty list
for ji in range(nlon):
print("Computing correlations at " + str(ds_sel.longitude[ji].values) + 'E')
for jj in range(nlat):
st = ds_sel['tos'][:,jj,ji]
climatology = st.groupby("time.month").mean("time")
anomalies = st.groupby("time.month") - climatology
st_annual = anomalies.groupby("time.year").mean("time")
# test if at least 100 non-NaNs
noNaNs = len(np.where(np.isnan(st_annual) == False)[0]) # number of valid years
sstvar = st_annual.var()
if noNaNs >= 100 and sstvar >= 0.01:
sttb = pyleo.Series(time=st_annual.coords['year'].values,
time_unit ='year CE',
value=st_annual.values,
value_unit = 'C', verbose=False)
sst_list.append(sttb)
corr_res = sttb.correlation(cc, method='phaseran',number =1000,seed=333, mute_pbar=True)
pval2[ji,jj] = corr_res.p
corr2[ji,jj] = corr_res.r
if pval2[ji,jj] < alpha:
slon.append(ds_sel.longitude[ji])
slat.append(ds_sel.latitude[jj])
else:
pval2[ji,jj] = np.nan; corr2[ji,jj] = np.nan
Computing correlations at 122.5E
Computing correlations at 127.5E
Computing correlations at 132.5E
Computing correlations at 137.5E
Computing correlations at 142.5E
Computing correlations at 147.5E
Computing correlations at 152.5E
Computing correlations at 157.5E
Computing correlations at 162.5E
Computing correlations at 167.5E
Computing correlations at 172.5E
Computing correlations at 177.5E
Computing correlations at 182.5E
Computing correlations at 187.5E
Computing correlations at 192.5E
Computing correlations at 197.5E
Computing correlations at 202.5E
Computing correlations at 207.5E
Computing correlations at 212.5E
Computing correlations at 217.5E
Computing correlations at 222.5E
Computing correlations at 227.5E
Computing correlations at 232.5E
Computing correlations at 237.5E
Computing correlations at 242.5E
Computing correlations at 247.5E
Computing correlations at 252.5E
Computing correlations at 257.5E
Computing correlations at 262.5E
Computing correlations at 267.5E
Computing correlations at 272.5E
Computing correlations at 277.5E
pvals2 = pval2.flatten() # make the p-value array a 1D one
pvec2 = pvals2[pvals2<1] # restrict to valid probabilities as there are a few weird values.
fdr_res2 = pyleo.utils.correlation.fdr(sorted(pvec2))
print(fdr_res2)
None
Here 1 grid point emerges as significant with this method. Now, another way we could have done this is to bundle all SST series from each grid point as a MultipleSeries object, and let the CorrEns class do its magic. This allows to directly compute the correlation between objects, and leverage the CorrEns class and its plotting method:
sstMS = pyleo.MultipleSeries(sst_list)
corr_ens = sstMS.correlation(cc,method='phaseran',number=1000,seed=333,mute_pbar=True)
Looping over 328 Series in collection
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2807.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2845.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2831.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2831.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2868.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2883.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2884.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2883.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2887.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2881.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2877.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2845.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2893.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2882.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2872.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2894.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2859.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2862.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2136.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2890.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2874.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2871.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2883.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2877.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2860.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2864.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2870.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2887.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2867.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2882.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2876.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2876.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2867.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2853.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2853.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2868.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2892.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2878.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2892.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2865.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2871.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2878.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2884.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2880.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2854.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2867.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2863.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2847.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2877.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2860.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2853.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2861.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2872.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2852.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2870.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2891.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2877.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2887.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2895.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2869.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2879.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2876.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2859.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2851.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2858.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2876.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2880.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2868.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2866.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2877.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2832.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2098.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2833.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2837.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2850.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2863.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2838.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2872.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2865.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2853.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2874.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2878.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2867.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2881.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2842.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2840.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2204.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2863.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2853.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2842.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2876.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2851.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2831.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2852.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2887.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2878.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2866.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2866.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2881.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2867.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2832.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2844.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2873.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2877.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2825.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2873.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2853.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2838.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2861.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2892.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2879.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2863.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2842.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2844.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2866.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2840.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2851.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2866.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2864.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2859.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2859.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2861.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2840.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2870.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2881.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2880.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2849.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2864.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2868.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2868.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2872.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2853.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2853.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2866.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2844.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2833.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2865.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2852.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2871.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2140.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2882.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2851.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2834.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2825.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2843.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2844.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2827.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2890.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2891.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2824.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2882.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2867.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2884.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2862.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2212.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2897.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2864.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2838.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2837.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2872.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2821.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2806.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2648.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2823.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2731.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2620.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2826.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2581.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2840.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2800.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2872.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2852.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2789.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2794.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2396.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2746.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2829.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2872.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2859.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2866.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2849.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2861.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2847.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2793.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2848.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2849.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2823.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2842.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2846.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2851.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2831.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2808.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2663.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2863.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2634.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2828.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2830.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2826.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2863.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2809.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2865.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2836.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2846.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2845.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2847.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2846.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2821.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2134.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2865.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2649.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2844.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2826.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2844.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2812.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2817.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2861.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2841.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2842.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2820.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2854.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2852.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2830.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2121.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2844.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2833.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2855.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2830.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2818.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2852.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2654.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2869.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2800.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2824.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2820.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2831.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2861.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2564.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2812.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2811.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2858.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2842.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2530.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2869.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2799.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2844.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2877.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2860.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2870.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2862.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2834.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2856.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2855.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2850.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2878.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2868.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2841.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2809.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2835.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2864.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2852.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2852.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2717.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2880.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2856.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2854.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2847.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2848.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2853.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2804.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2836.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2850.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2840.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2863.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2830.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2786.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 1895.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2404.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2504.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2833.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2873.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2847.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2801.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2774.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2861.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2840.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2853.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2858.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2856.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2858.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2865.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2854.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2867.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2843.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2864.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2702.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2478.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2829.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2674.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2869.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2869.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2839.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2873.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2883.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2870.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2820.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2880.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2908.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2890.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2919.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2926.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2912.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2902.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2889.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2907.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2865.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2841.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2905.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2916.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2945.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2957.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2947.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2967.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2926.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2906.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2934.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2839.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2836.
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2656.
corr_ens.plot()
(<Figure size 400x400 with 1 Axes>, <Axes: xlabel='$r$', ylabel='Count'>)
To save this figure, there are several ways. The standard matplotlib way would look like this:
fig.savefig('CrystalCave_field_corr_hist.pdf')
The file format is inferred form the filename, but the default resolution may be too low for publication. In addition, setting the legend to the right has expanded the figure’s bounding box, but savefig doesn’t know about that, and will crop the result, wasting our effort. These two problems may be remedied thus:
fig.savefig('CrystalCave_field_corr_hist.pdf', dpi=300, bbox_inches='tight')
Alternatively, users may pass a dictionary called savefig_settings:
corr_ens.plot(savefig_settings={'path':'CrystalCave_field_corr_hist.pdf'})
Figure saved at: "CrystalCave_field_corr_hist.pdf"
(<Figure size 400x400 with 1 Axes>, <Axes: xlabel='$r$', ylabel='Count'>)
By default, it sets the dpi to 300 and bbox_inches='tight', so the path is the only thing that need be specified. Note that in this case the
corr_ens.signif_fdr.count(True)
0
We find the same result as before, though in a much more compact form. Note, however, that this method does not keep track of where the significant points are (it does not have a notion of what “where” means), so if you wanted to draw a map like the one above, you would be better off with the loop previously shown.
Pitfall #3: Age uncertainties#
The first two pitfalls notwithstanding, there is a third difficulty in this comparison: beautiful though U/Th chronologies may be, they harbor uncertainties too, and such chronological uncertainties must be taken into account. The LiPD file provided with this notebook contains not only the raw U/Th dates and the published ages, but also an ensemble of age-depth relationships derived from those dates, via the Bayesian age model BChron (Haslett & Parnell, 2008). Let us load those 1000 draws from the posterior distribution of ages and put them in an object where Pyleoclim will be able to work with them. To do so, we will call upon the PyLiPD package to manipulate the LiPD file.
ensemble_df = D.get_ensemble_tables()
ensemble_df.head()
| datasetName | ensembleTable | ensembleVariableName | ensembleVariableValues | ensembleVariableUnits | ensembleDepthName | ensembleDepthValues | ensembleDepthUnits | notes | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | Crystal.McCabe-Glynn.2013 | http://linked.earth/lipd/Crystal.McCabe-Glynn.... | Year | [[2007.0, 2007.0, 2008.0, 2007.0, 2007.0, 2007... | yr AD | depth | [0.1, 0.15, 0.2, 0.25, 0.3, 0.35, 0.4, 0.45, 0... | mm | None |
cc_ens = pyleo.EnsembleGeoSeries.from_AgeEnsembleArray(geo_series=cc, age_array= ensemble_df.iloc[0]['ensembleVariableValues'],
age_depth = ensemble_df.iloc[0]['ensembleDepthValues'],
value_depth = cc.depth, verbose=False)
The resulting object is an EnsembleGeoSeries, a special case of MultipleGeoSeries where all constituent series have the same units There are two ways to plot this ensemble. First, as a series of traces:
fig, ax = cc_ens.plot_traces()
cc.plot(color='black', ax = ax)
<Axes: xlabel='Time [yr AD]', ylabel='$\\delta^{18}O$ [‰]'>
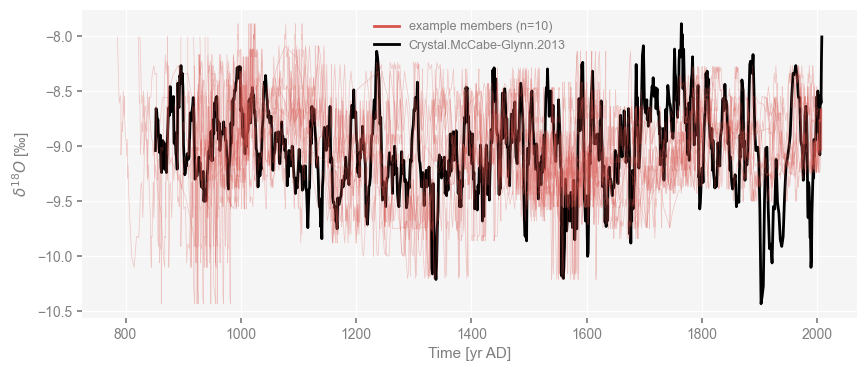
It is quite plain that any of the record’s main swings can be swung back and forth by up to decades. Another way to see this is to plot various quantiles as an envelope:
fig, ax = cc_ens.common_time(method='interp').plot_envelope(ylabel = cc.value_name)
cc.plot(color='black', ax = ax, linewidth=1)
<Axes: xlabel='Time [yr AD]', ylabel='$\\delta^{18}O$ [‰]'>
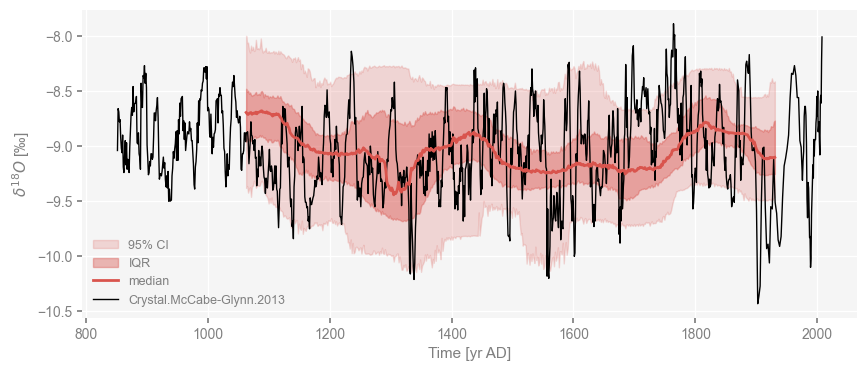
Notice how the quantiles are computed over only part of the interval covered by the original series; that is because some age models end up being more compressed or stretched out than the original, and we need a common interval to compute quantiles. In particular, notice how the base of the record could really be anywhere between 850 and 1100 AD.
cc_ens.dashboard()
Performing spectral analysis on individual series: 100%|█| 1000/1000 [00:17<00:0
(<Figure size 1100x800 with 4 Axes>,
{'ts': <Axes: xlabel='Time [yr AD]', ylabel='$\\delta^{18}O$ [‰]'>,
'dts': <Axes: xlabel='Counts'>,
'map': {'map': <GeoAxes: xlabel='lon', ylabel='lat'>},
'spec': <Axes: xlabel='Period [yr AD]', ylabel='PSD'>})
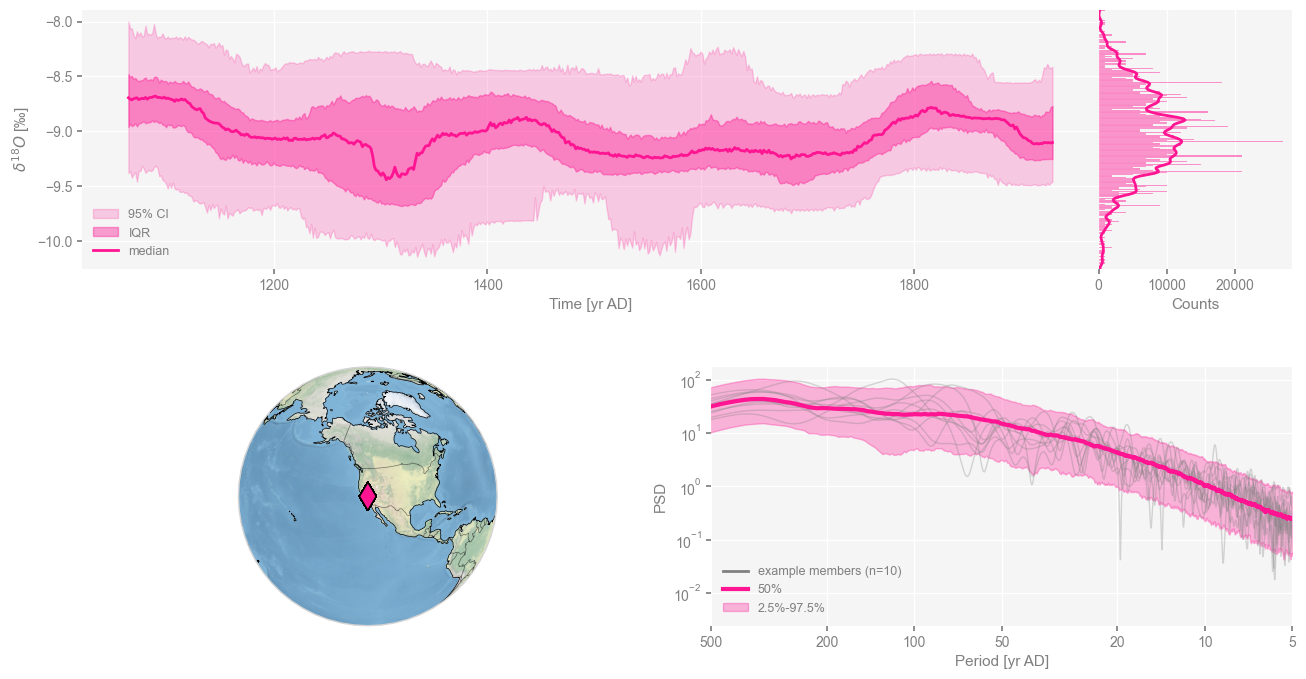
Now, what we’d like to do is repeat the exercise of Part 1, correlating the same SST timeseries from 32.5N 142.5W (near the Kuroshio Extension), not just with the published chronology, but this whole ensemble. Remember how we had computed things:
corr_res = stts.correlation(cc, seed = 22)
print(corr_res)
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2857.
correlation p-value signif. (α: 0.05)
------------- --------- -------------------
0.323596 0.12 False
Though of course, we could have done just the reverse, as correlation is a symmetric operator:
corr_res = cc.correlation(stts, seed = 22)
print(corr_res)
Evaluating association on surrogate pairs: 100%|█| 1000/1000 [00:00<00:00, 2201.
correlation p-value signif. (α: 0.05)
------------- --------- -------------------
0.323596 0.12 False
Now, consider the task ahead: a user must iterate over all ensemble members, taking care of aligning their time axis to that of HadSST4; you must compute the correlation and establish its significance with a sensible test (Pitfall #1), watching out for test multiplicity (see Pitfall #2) and visualizing the results in an intuitive way. pyleoclim simplifies this process, which illustrate here for the Kuroshio Extension location as above. To keep computing time manageable, we reduce the number of isospectral simulations to 500, and correlate the ensemble and the SST series we started with:
corr_Kuroshio = cc_ens.correlation(stts,number = 500,seed = 453)
Looping over 1000 Series in the ensemble
0%| | 2/1000 [00:00<01:13, 13.59it/s]
Time axis values sorted in ascending order
100%|███████████████████████████████████████| 1000/1000 [01:06<00:00, 15.10it/s]
Again corr_Kuroshio is a CorrEns object, which contains everything you want: the vector of correlations, the p-values, and a method to plot them all:
corr_Kuroshio.plot()
(<Figure size 400x400 with 1 Axes>, <Axes: xlabel='$r$', ylabel='Count'>)
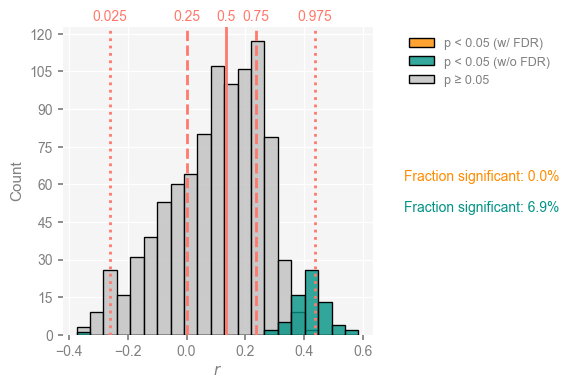
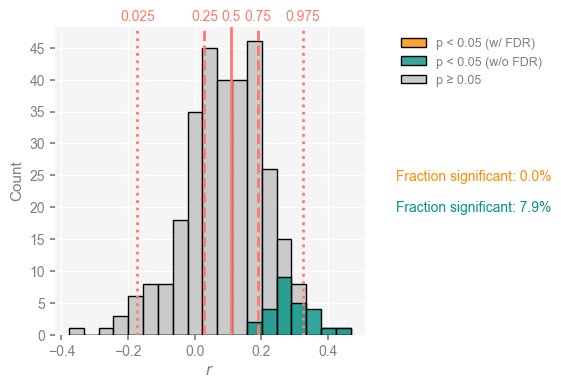
Several things jump out at once:
the correlation histogram is relatively symmetric, meaning that age uncertainties are able to completely overturn the original correlation of about 0.32 : nearly half of the ensemble exhibits negative correlations with SST).
As shown in teal, only ~4% of the 500*100 correlations just computed are judged significant.
Once we take test multiplicity into account via the False Discovery Rate (orange bar), only a fraction of a % is deemed significant.
To save the figure:
corr_Kuroshio.plot(savefig_settings={'path':'CrystalCave_ageens_corr_hist.pdf'})
Figure saved at: "CrystalCave_ageens_corr_hist.pdf"
(<Figure size 400x400 with 1 Axes>, <Axes: xlabel='$r$', ylabel='Count'>)
Conclusion#
We see, as in Hu et al (2017), that all of these pitfalls matter. Any single one of them can turn a correlation initially reported as significant into an insignificant one, and the picture worsens if these pitfalls compound one another. The conjunction of all 3 pitfalls (persistence, test multiplicity, and age uncertainties) is particularly damaging in this example, invalidating the published interpretation of Crystal Cave \(\delta^{18}O\) as a proxy for Kuroshio Extension SST.
Pyleoclim makes it easy to deal with those pitfalls, which we hoped will help avoid spurious correlations in paleoclimatology and paleoceanography. It bears emphasizing, as Hu et al (2017) did, that a significant linear correlation is neither necessary nor sufficient a condition to establish the interpretation of a proxy series, and that mechanistic models or in situ monitoring are generally needed.
References#
Benjamini, Y., and Y. Hochberg (1995), Controlling the false discovery rate: A practical and powerful approach to multiple testing, Journal of the Royal Statistical Society. Series B (Methodological), 57(1), 289–300, doi:10.2307/2346101.
Dawdy, D., and N. Matalas (1964), Statistical and probability analysis of hydro- logic data, part III: Analysis of variance, covariance and time series, McGraw-Hill.
Ebisuzaki, W. (1997), A method to estimate the statistical significance of a correlation when the data are serially correlated, Journal of Climate, 10(9), 2147–2153, doi:10.1175/1520- 0442(1997)010¡2147:AMTETS¿2.0.CO;2
Gelman, A., and H. Stern (2006), The difference between “significant” and “not significant” is not itself statistically significant, The American Statistician, 60(4), 328–331, doi: 10.1198/000313006X152649.
Haslett, J., and A. Parnell (2008), A simple monotone process with application to radiocarbon-dated depth chronologies, Journal of the Royal Statistical Society: Series C (Applied Statistics), 57(4), 399–418, doi:10.1111/j.1467-9876.2008.00623.x.
Hu, J., J. Emile-Geay, and J. Partin (2017), Correlation-based interpretations of paleoclimate data – where statistics meet past climates, Earth and Planetary Science Letters, 459, 362–371, doi:10.1016/j.epsl.2016.11.048
McCabe-Glynn, S., K. R. Johnson, C. Strong, M. Berkelhammer, A. Sinha, H. Cheng, and R. L. Edwards (2013), Variable North Pacific influence on drought in southwestern North America since AD 854, Nat. Geosci., 6(8), 617–621, doi:10.1038/NGEO1862.
Morice, C. P., J. J. Kennedy, N. A. Rayner, and P. D. Jones (2012), Quantifying uncertainties in global and regional temperature change using an ensemble of observational estimates: The HadCRUT4 data set, Journal of Geophysical Research: Atmospheres, 117(D8), n/a–n/a, doi:10.1029/2011JD017187.
Rehfeld, K., and J. Kurths (2014), Similarity estimators for irregular and age-uncertain time series, Climate of the Past, 10(1), 107–122, doi:10.5194/cp-10-107-2014
Wilks, D. S. (2011), Statistical Methods in the Atmospheric Sciences: an Introduction, 676 pp., Academic Press, San Diego