Paleoclimate Model Data-Comparison: CMIP6 vs LMR#
Overview#
This notebook compares the output of physics-based models of the climate of the past millennium to reconstructions from the Last Millennium Reanalysis project and allows a quick glance at the simulated and reconstructed climate response to major volcanic events of the Common Era. In the process, it illustrates how to:
Pull and process CMIP6 output from Google Cloud
Plot an envelope of LMR simulations with CMIP6 output
Plot spatial variations of reconstructed and simulated snapshots
Time to learn: 25 minutes
Prerequisites#
Concepts |
Importance |
Notes |
|---|---|---|
Necessary |
||
Helpful |
Familiarity with metadata structure |
|
Helpful |
Background about the structure of the data catalog |
Imports#
%load_ext autoreload
%autoreload 2
import os
from pathlib import Path
from collections import defaultdict
import pandas as pd
import numpy as np
import xarray as xr
import cftime
import matplotlib.pyplot as plt
import matplotlib as mpl
from matplotlib import cm
import matplotlib.gridspec as gridspec
import pyleoclim as pyleo
import cartopy.crs as ccrs
import cartopy.feature as cfeature
import cartopy.util as cutil
import intake
Data-model comparison of global-mean surface temperature#
Last Millennium Reanalysis Project (LMR)#
Many methods have been proposed to reconstruct past climates. An increasingly mature and popular framework is that of paleoclimate data assimilation, which has been applied to many time intervals. In particular, the Last Millennium Reanalysis provides estimates of gridded climate fields like surface air temperature, sea-level pressure, precipitation, and others, together with estimates of their uncertainties (which are often at least as important as the central estimates). (Hakim et al, 2016 and Tardif et al, 2019)
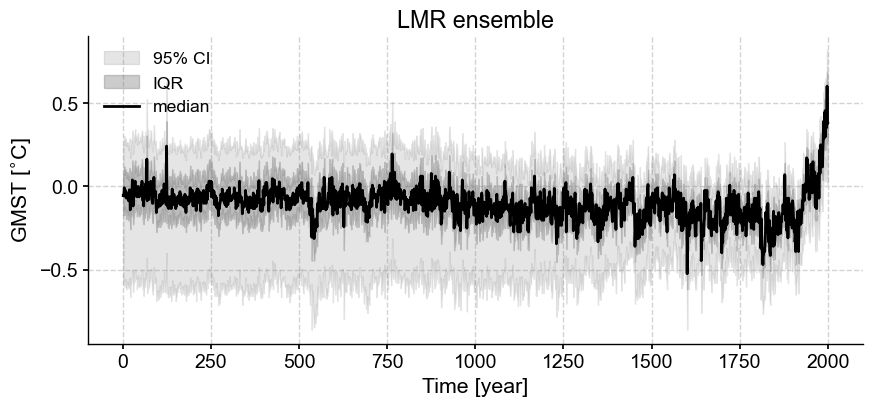
In a nutshell, LMR blends information from paleoclimate proxies and climate models, with models providing estimates of relationships over space and between variables, while proxies give the timing and amplitude of events. To explore the full distribution of possible trajectories, LMR uses an ensemble Kalman filter, which employs a Monte Carlo approach to this exploration: each reconstruction starts with a sample of 100 randomly-drawn climate snapshots from a model simulation (each such snapshot - a year - is called a member). Proxy measurements for each year are used to establish the likelihood of each climate snapshot. In addition, the algorithm conducts 20-50 “iterations”, where it selects 75% of the catalog of proxies and reserves the other 25% for validation. By doing this many times (50 iterations each with different 100 snapshots) we can build a 5000-strong picture of how the climate of the Common Era may have unfolded, capturing uncertainties about this history.
We’ll load datasets using Xarray. Xarray is specifically designed to accommodate multidimensional data, like that from a NetCDF file. Let’s load 1000 traces of GMST reconstructed using LMR, as presened in Neukom et al. (2019).
file_path = Path(os.getcwd()).parent.parent/'data/p2k_ngeo19_recons.nc'
p2k_nc = xr.open_dataset(file_path)
p2k_nc
<xarray.Dataset>
Dimensions: (year: 2000, ens: 1000)
Coordinates:
* year (year) int64 1 2 3 4 5 6 7 8 ... 1994 1995 1996 1997 1998 1999 2000
* ens (ens) int64 1 2 3 4 5 6 7 8 9 ... 993 994 995 996 997 998 999 1000
Data variables:
LMRv2.1 (year, ens) float32 ...
BHM (year, ens) float64 ...
DA (year, ens) float64 ...
CPS_new (year, ens) float64 ...
CPS (year, ens) float64 ...
OIE (year, ens) float64 ...
PAI (year, ens) float64 ...
PCR (year, ens) float64 ...
M08 (year, ens) float64 ...%%time
variable_name = 'LMRv2.1'
ens_grps = p2k_nc.groupby('ens')
traces = []
for im in range(len(p2k_nc.ens)):
ens_run = ens_grps[im+1].data_vars[variable_name]
traces.append(pyleo.Series(time=p2k_nc.year, value=ens_run,
time_name='Time', time_unit='year',
value_name='GMST', value_unit='$^{\circ}$C', verbose=False))
lmr_ens = pyleo.EnsembleSeries(traces);
CPU times: user 1.88 s, sys: 60.2 ms, total: 1.94 s
Wall time: 2.14 s
lmr_ens.plot_envelope(title='LMR ensemble', shade_clr='gray', curve_clr='k');
CMIP6 & PMIP4#
The Climate Model Intercomparison Project Phase 6 (CMIP6) is a major international effort to organize climate simulations by specifying a standardized menu of experiments, providing data-sharing infrastructure (which guides output toward a homogeneous structure and nomenclature), and requiring each participating model to submit the following entry card simulations as a baseline:
Pre-industrial control (piControl)
Abrupt-4xCO2
1% per year increase in CO2 (1pctCO2)
Atmospheric Model Intercomparison Project (AMIP)
Simulations of the period 1850-2014 (historical)
The Paleoclimate Modeling Intercomparison Project (PMIP) component of CMIP6 focused on simulating climate prior to the industrial era. The PMIP community develops forcing files for each experiment based on proxy and other climate data so that each model uses a common set of boundary conditions for factors such as greenhouse gas concentrations, solar radiation, land cover, and ice sheet extent. While submitting PMIP simulations is not a requirement for participating in CMIP6, simulating climate beginning with conditions notably different from those specified for the historical benchmark provides important information about the robustness of a model’s physics. All PMIP participants were required to submit output for three entry-card experiments plus any of the optional experiments. As of spring 2023, output is still coming in from the 19 institutions signed up to participate in PMIP4, but so far, data is available via the Earth System Grid Federation for:
[entry-card] Mid-Holocene (MH): 16
[entry-card] Last Glacial Maximum (LGM): 6
[entry-card] Last Interglacial (LIG): 15
Last Millennium (past1000): 4
Past2k (past2k): 1
Cloud-ready data#
Data is readily available for download via the ESGF website, and additional files may be available by request. However, it isn’t always convenient to maintain a mini CMIP6 catalog locally. In order to encourage analysis of CMIP6 output, Amazon Web Services and Google Cloud have stepped up to make a few petabytes available in a cloud-ready format as part of the AWS Open Data Sponsorship Program and Google Cloud Public Datasets, respectively. Cloud-ready data can be queried and subsetted remotely, allowing a user to minimize the amount of data that is loaded into memory by only loading on request (for example, to make a plot).
Most data are not published under the unifying hand of an effort like CMIP6, but still yearn to see the light of day. The folks at Pangeo-Forge have made it their mission to provide infrastructure help community members do the custom configuration needed to make large datasets–often stored in multiple parts–available in a clean, consolidated form via a simple URL.
Voila! Loading large data files (e.g., compilations, model output), goes from being somewhere between challenging and impossible on the average personal computer, to well within reach.
Pulling Data#
In order to look at the interval 850 to present (ish), we’ll need output from both the “historical” CMIP6 entry card runs and the PMIP “past1000k” experiment.
While the CMIP6 historical output is available for all three via Google Cloud (the Google Cloud and Google Cloud offerings were the same at this writing), the same cannot be said of PMIP output. Happily, a select set of PMIP experimental output is available via Pangeo-Forge.
PMIP output for tas available via cloud pointer:
MIROC-ES2L.past1000.r1i1p1f2.Amon.tas(Pangeo-Forge)MRI-ESM2-0.past1000.r1i1p1f1.Amon.tas(Pangeo-Forge, Google Cloud)MPI-ESM1-2-LR.past2k.r1i1p1f1.Amon.tas(Pangeo-Forge)
Let’s tap Pangeo-Forge for PMIP, and Google Cloud for CMIP.
Google Cloud#
To get data from Google Cloud, we will use intake to load a json file with information about the Google Cloud holdings, query it, and then pull the output of interest. For a deeper dive into using intake to query CMIP6 holdings, check out this lifehack
# for AWS S3
# cat_url = "https://cmip6-pds.s3.amazonaws.com/pangeo-cmip6.json"
# for google:
cat_url = "https://storage.googleapis.com/cmip6/pangeo-cmip6.json"
col = intake.open_esm_datastore(cat_url)
experiments = ['historical', 'past1000']
sources = ['MIROC-ES2L', 'MRI-ESM2-0', 'MPI-ESM1-2-LR']
variables = ['tas']
members = ['r1i1p1f1', 'r1i1p1f2']
query_d = dict(source_id=sources,
experiment_id=experiments,
grid_label='gn',
variable_id=variables,
member_id = members,
table_id='Amon'
)
search_res = col.search(**query_d)
search_res.df
| activity_id | institution_id | source_id | experiment_id | member_id | table_id | variable_id | grid_label | zstore | dcpp_init_year | version | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | CMIP | MRI | MRI-ESM2-0 | historical | r1i1p1f1 | Amon | tas | gn | gs://cmip6/CMIP6/CMIP/MRI/MRI-ESM2-0/historica... | NaN | 20190222 |
| 1 | CMIP | MPI-M | MPI-ESM1-2-LR | historical | r1i1p1f1 | Amon | tas | gn | gs://cmip6/CMIP6/CMIP/MPI-M/MPI-ESM1-2-LR/hist... | NaN | 20190710 |
| 2 | CMIP | MIROC | MIROC-ES2L | historical | r1i1p1f2 | Amon | tas | gn | gs://cmip6/CMIP6/CMIP/MIROC/MIROC-ES2L/histori... | NaN | 20190823 |
| 3 | PMIP | MRI | MRI-ESM2-0 | past1000 | r1i1p1f1 | Amon | tas | gn | gs://cmip6/CMIP6/PMIP/MRI/MRI-ESM2-0/past1000/... | NaN | 20200120 |
%time
_esm_data_d = search_res.to_dataset_dict(require_all_on=['source_id', 'grid_label', 'table_id', 'variant_label'],#['source_id', 'experiment_id'],
xarray_open_kwargs={'consolidated': True,'use_cftime':True, 'chunks':{}},
storage_options={'token': 'anon'}
)
_esm_data_d.keys()
CPU times: user 2 µs, sys: 1e+03 ns, total: 3 µs
Wall time: 5.72 µs
--> The keys in the returned dictionary of datasets are constructed as follows:
'activity_id.institution_id.source_id.experiment_id.table_id.grid_label'
dict_keys(['PMIP.MRI.MRI-ESM2-0.past1000.Amon.gn', 'CMIP.MRI.MRI-ESM2-0.historical.Amon.gn', 'CMIP.MPI-M.MPI-ESM1-2-LR.historical.Amon.gn', 'CMIP.MIROC.MIROC-ES2L.historical.Amon.gn'])
esm_data_d = {}
for key in _esm_data_d.keys():
parts = key.split('.', 4)
if parts[1] not in esm_data_d.keys():
esm_data_d[parts[1]]= defaultdict(dict)
esm_data_d[parts[1]][parts[2]][parts[3]] = _esm_data_d[key]
Pangeo-Forge#
PF_cloud_pointers = {'MIROC': 'https://ncsa.osn.xsede.org/Pangeo/pangeo-forge/pangeo-forge/CMIP6-PMIP-feedstock/CMIP6.PMIP.MIROC.MIROC-ES2L.past1000.r1i1p1f2.Amon.tas.gn.v20200318.zarr',
'MRI': 'https://ncsa.osn.xsede.org/Pangeo/pangeo-forge/pangeo-forge/CMIP6-PMIP-feedstock/CMIP6.PMIP.MRI.MRI-ESM2-0.past1000.r1i1p1f1.Amon.tas.gn.v20200120.zarr',
'MPI': 'https://ncsa.osn.xsede.org/Pangeo/pangeo-forge/pangeo-forge/CMIP6-PMIP-feedstock/CMIP6.PMIP.MPI-M.MPI-ESM1-2-LR.past2k.r1i1p1f1.Amon.tas.gn.v20210714.zarr'}
PF_data_d = {key: xr.open_dataset(PF_cloud_pointers[key], engine='zarr', chunks={}, use_cftime=True) for key in PF_cloud_pointers.keys()}
Processing data#
Data in hand, we need to check that they follow the structure we are expecting, and tune that structure where appropriate. Groups participating in PMIP do their best to standardize output according to CMIP6 guidelines, but idiosyncrasies remain. For each output, we will iron them out, and then continue with our calculations.
Once we know the data are orderly, we will calculate the global mean annual surface air temperature anomaly relative to the interval 1900-1980, per the approach used for the LMR 2.1 data loaded above.
def calc_climatology(ds, time_unit='time.month', interval=None):
if type(interval) not in [list, set, tuple]:
interval_ds = ds
else:
interval_ds = ds.sel(time=(ds.time.dt.year < max(interval)) | (ds.time.dt.year >= min(interval)))
climatology = interval_ds.groupby(time_unit).mean("time")
return climatology
def remove_seasonality(ds, climatology, time_unit='time.month'):
anomalies = ds.groupby(time_unit) - climatology
return anomalies
def global_mean(ds, lat_weighted=False):
if lat_weighted is True:
lat_weights = np.cos(np.deg2rad(ds.lat))
lat_weights.name = "lat_weights"
ds_lat_weighted = ds.weighted(lat_weights)
ds_global_mean = ds_lat_weighted.mean(("lon", "lat"))
else:
ds_global_mean = ds.mean(("lon", "lat"))
return ds_global_mean
def annualize(ds):
ds_annualized = ds.groupby('time.year').mean('time')
return ds_annualized
def calc_da_ps(da):
ps = pyleo.Series(da.year, da.squeeze(), time_unit='year',
clean_ts=False, value_name='Temp anomaly ($^{\circ}$C)',
verbose=False)#atm temp @2m')
return {'da': da.squeeze(), 'ps':ps}
annualized_anomaly_gwm = {}
annualized_anomaly_spatial = {}
MIROC#
miroc_model = 'MIROC-ES2L'
_miroc_past1000 = PF_data_d['MIROC']
_miroc_past1000.dims
Frozen({'lat': 64, 'bnds': 2, 'lon': 128, 'time': 12011})
The time: 12011 is a bit suspicious. Checking for a hiccough never hurts.
xr.CFTimeIndex(_miroc_past1000.time.data, name=None).is_monotonic_increasing
False
Ah. Finding these wrinkles can be tricky. A simple strategy is to group the data by year and check to see if any years have more than 12 entries.
# group by year
miroc_yeargrps = _miroc_past1000.groupby('time.year').groups
# years with more than 12 entries
miroc_years = [key for key in miroc_yeargrps.keys() if len(miroc_yeargrps[key])>12]
miroc_years
[850]
_miroc_past1000.time[:13].data
array([cftime.Datetime360Day(850, 1, 16, 0, 0, 0, 0, has_year_zero=True),
cftime.Datetime360Day(850, 2, 16, 0, 0, 0, 0, has_year_zero=True),
cftime.Datetime360Day(850, 3, 16, 0, 0, 0, 0, has_year_zero=True),
cftime.Datetime360Day(850, 4, 16, 0, 0, 0, 0, has_year_zero=True),
cftime.Datetime360Day(850, 5, 16, 0, 0, 0, 0, has_year_zero=True),
cftime.Datetime360Day(850, 6, 16, 0, 0, 0, 0, has_year_zero=True),
cftime.Datetime360Day(850, 7, 16, 0, 0, 0, 0, has_year_zero=True),
cftime.Datetime360Day(850, 8, 16, 0, 0, 0, 0, has_year_zero=True),
cftime.Datetime360Day(850, 9, 16, 0, 0, 0, 0, has_year_zero=True),
cftime.Datetime360Day(850, 10, 16, 0, 0, 0, 0, has_year_zero=True),
cftime.Datetime360Day(850, 11, 16, 0, 0, 0, 0, has_year_zero=True),
cftime.Datetime360Day(850, 1, 16, 0, 0, 0, 0, has_year_zero=True),
cftime.Datetime360Day(850, 2, 15, 0, 0, 0, 0, has_year_zero=True)],
dtype=object)
_miroc_past1000.time.encoding
{'chunks': (12011,),
'preferred_chunks': {'time': 12011},
'compressor': Blosc(cname='lz4', clevel=5, shuffle=SHUFFLE, blocksize=0),
'filters': None,
'units': 'days since 0850-01-16 00:00:00.000000',
'calendar': '360_day',
'dtype': dtype('int64')}
Now we can slice off the initial 11 months and convert the calendar to ‘proleptic_gregorian’.
miroc_past1000 = _miroc_past1000.isel({'time':slice(11,len(_miroc_past1000.time))})#time[:74]
miroc_past1000 = miroc_past1000.convert_calendar('proleptic_gregorian', use_cftime=True, align_on='date')
Now let’s convert the calendar of the historical output
miroc_hist = esm_data_d['MIROC']['MIROC-ES2L']['historical'].convert_calendar('proleptic_gregorian', use_cftime=True).squeeze()
miroc_exp = {'past1000': miroc_past1000['tas'], 'historical': miroc_hist['tas']}
miroc_climatology = calc_climatology(miroc_hist['tas'])
miroc_annualized_anomaly_spatial = {key: annualize(remove_seasonality(miroc_exp[key], miroc_climatology)) for key in miroc_exp.keys()}
annualized_anomaly_spatial['MIROC']=miroc_annualized_anomaly_spatial
/Users/jlanders/opt/miniconda3/envs/paleobook-dev/lib/python3.10/site-packages/xarray/core/indexing.py:1440: PerformanceWarning: Slicing with an out-of-order index is generating 1000 times more chunks
return self.array[key]
/Users/jlanders/opt/miniconda3/envs/paleobook-dev/lib/python3.10/site-packages/xarray/core/indexing.py:1440: PerformanceWarning: Slicing with an out-of-order index is generating 165 times more chunks
return self.array[key]
%%time
miroc_yr_gmt_anom = {key: calc_da_ps(annualize(global_mean(remove_seasonality(miroc_exp[key], miroc_climatology),
lat_weighted=True).compute())) for key in miroc_exp.keys()}
for key in miroc_yr_gmt_anom.keys():
miroc_yr_gmt_anom[key]['ps'].label = '_'.join([miroc_model, key])
annualized_anomaly_gwm['MIROC'] = miroc_yr_gmt_anom
/Users/jlanders/opt/miniconda3/envs/paleobook-dev/lib/python3.10/site-packages/xarray/core/indexing.py:1440: PerformanceWarning: Slicing with an out-of-order index is generating 1000 times more chunks
return self.array[key]
/Users/jlanders/opt/miniconda3/envs/paleobook-dev/lib/python3.10/site-packages/xarray/core/indexing.py:1440: PerformanceWarning: Slicing with an out-of-order index is generating 165 times more chunks
return self.array[key]
CPU times: user 1min 35s, sys: 15.7 s, total: 1min 50s
Wall time: 7min 24s
MRI#
mri_model = 'MRI-ESM2-0'
mri_past1000 = PF_data_d['MRI']
mri_past1000.time.encoding
{'chunks': (12000,),
'preferred_chunks': {'time': 12000},
'compressor': Blosc(cname='lz4', clevel=5, shuffle=SHUFFLE, blocksize=0),
'filters': None,
'units': 'hours since 0850-01-16 12:00:00.000000',
'calendar': 'proleptic_gregorian',
'dtype': dtype('int64')}
mri_hist = esm_data_d['MRI']['MRI-ESM2-0']['historical']
mri_hist.time.encoding
{'chunks': (1980,),
'preferred_chunks': {'time': 1980},
'compressor': Blosc(cname='lz4', clevel=5, shuffle=SHUFFLE, blocksize=0),
'filters': None,
'_FillValue': nan,
'units': 'days since 1850-01-01',
'calendar': 'proleptic_gregorian',
'dtype': dtype('float64')}
mri_climatology = calc_climatology(mri_hist['tas'])
mri_exp = {'past1000': mri_past1000['tas'], 'historical': mri_hist['tas']}
%%time
mri_annualized_anomaly_spatial = {key: annualize(remove_seasonality(mri_exp[key], mri_climatology)) for key in mri_exp.keys()}
annualized_anomaly_spatial['MRI']=mri_annualized_anomaly_spatial
/Users/jlanders/opt/miniconda3/envs/paleobook-dev/lib/python3.10/site-packages/xarray/core/indexing.py:1440: PerformanceWarning: Slicing with an out-of-order index is generating 1000 times more chunks
return self.array[key]
/Users/jlanders/opt/miniconda3/envs/paleobook-dev/lib/python3.10/site-packages/xarray/core/indexing.py:1440: PerformanceWarning: Slicing with an out-of-order index is generating 165 times more chunks
return self.array[key]
CPU times: user 8.07 s, sys: 244 ms, total: 8.31 s
Wall time: 14.8 s
%%time
mri_yr_gmt_anom = {key: calc_da_ps(annualize(global_mean(remove_seasonality(mri_exp[key], mri_climatology), lat_weighted=True).compute())) for key in mri_exp.keys()}
for key in mri_yr_gmt_anom.keys():
mri_yr_gmt_anom[key]['ps'].label = '_'.join([mri_model, key])
annualized_anomaly_gwm['MRI'] = mri_yr_gmt_anom
/Users/jlanders/opt/miniconda3/envs/paleobook-dev/lib/python3.10/site-packages/xarray/core/indexing.py:1440: PerformanceWarning: Slicing with an out-of-order index is generating 1000 times more chunks
return self.array[key]
/Users/jlanders/opt/miniconda3/envs/paleobook-dev/lib/python3.10/site-packages/xarray/core/indexing.py:1440: PerformanceWarning: Slicing with an out-of-order index is generating 165 times more chunks
return self.array[key]
CPU times: user 1min, sys: 18.9 s, total: 1min 19s
Wall time: 1min 27s
MPI#
mpi_model = 'MPI-ESM1-2-LR'
mpi_past2k = PF_data_d['MPI']
mpi_past2k.time.encoding
{'chunks': (22200,),
'preferred_chunks': {'time': 22200},
'compressor': Blosc(cname='lz4', clevel=5, shuffle=SHUFFLE, blocksize=0),
'filters': None,
'units': 'hours since 7001-01-16 12:00:00.000000',
'calendar': 'proleptic_gregorian',
'dtype': dtype('int64')}
Wow… 'hours since 7001-01-16 12:00:00.000000'
If we shift time back 7001 years, the start year becomes 0 and the end year is 1850, consistent with the fact that the MPI-M output is for the past2k, not past1000.
mpi_past2k = mpi_past2k.assign_coords(time=xr.CFTimeIndex(mpi_past2k['time'].values).shift(-7001*12, 'M'))
mpi_past1000 = mpi_past2k.sel(time=(mpi_past2k.time.dt.year >= 850))
mpi_hist = esm_data_d['MPI-M'][mpi_model]['historical']
mpi_hist.time.encoding
{'chunks': (1980,),
'preferred_chunks': {'time': 1980},
'compressor': Blosc(cname='lz4', clevel=5, shuffle=SHUFFLE, blocksize=0),
'filters': None,
'units': 'hours since 1850-01-16 12:00:00.000000',
'calendar': 'proleptic_gregorian',
'dtype': dtype('int64')}
mpi_climatology = calc_climatology(mpi_hist['tas'])
mpi_exp = {'past1000': mpi_past1000['tas'], 'historical': mpi_hist['tas']}
%%time
mpi_yr_gmt_anom = {key: calc_da_ps(annualize(global_mean(remove_seasonality(mpi_exp[key], mpi_climatology), lat_weighted=True).compute())) for key in mpi_exp.keys()}
for key in mpi_yr_gmt_anom.keys():
mpi_yr_gmt_anom[key]['ps'].label = '_'.join([mpi_model, key])
annualized_anomaly_gwm['MPI'] = mpi_yr_gmt_anom
/Users/jlanders/opt/miniconda3/envs/paleobook-dev/lib/python3.10/site-packages/xarray/core/indexing.py:1440: PerformanceWarning: Slicing with an out-of-order index is generating 1000 times more chunks
return self.array[key]
/Users/jlanders/opt/miniconda3/envs/paleobook-dev/lib/python3.10/site-packages/xarray/core/indexing.py:1440: PerformanceWarning: Slicing with an out-of-order index is generating 165 times more chunks
return self.array[key]
CPU times: user 44.1 s, sys: 9.57 s, total: 53.6 s
Wall time: 1min
%%time
mpi_annualized_anomaly_spatial = {key: annualize(remove_seasonality(mpi_exp[key], mpi_climatology)) for key in mpi_exp.keys()}
annualized_anomaly_spatial['MPI']=mpi_annualized_anomaly_spatial
/Users/jlanders/opt/miniconda3/envs/paleobook-dev/lib/python3.10/site-packages/xarray/core/indexing.py:1440: PerformanceWarning: Slicing with an out-of-order index is generating 1000 times more chunks
return self.array[key]
/Users/jlanders/opt/miniconda3/envs/paleobook-dev/lib/python3.10/site-packages/xarray/core/indexing.py:1440: PerformanceWarning: Slicing with an out-of-order index is generating 165 times more chunks
return self.array[key]
CPU times: user 5.08 s, sys: 92.8 ms, total: 5.18 s
Wall time: 5.31 s
Comparing simulations to reconstructions#
We now have all the pieces in hand to compare simulations to reconstructions! Let’s plot the processed model output on top of ensemble plot we made earlier to see whether the model output agrees with the envelope characterized by the LMR reconstructions.
fig = plt.figure(figsize=(9, 4), layout="constrained")
ax2 = fig.add_subplot()
# Same EnsembleSeries envelope from above, this time with lines that correspond to volcanic events
lmr_ens.plot_envelope( shade_alpha = .1, ylabel='GMST [$^{\circ}$C]',
curve_lw=.5, shade_clr='k', curve_clr='k', ax=ax2)
for key in annualized_anomaly_gwm.keys():
for exp in annualized_anomaly_gwm[key].keys():
annualized_anomaly_gwm[key][exp]['ps'].plot(ax=ax2, linewidth=.5)
ax2.xaxis.set_ticks_position('bottom')
ax2.grid(False)
ax2.legend(bbox_to_anchor = (1,1))
xlims = [850, 2014]
ax2.set_xlim(xlims);
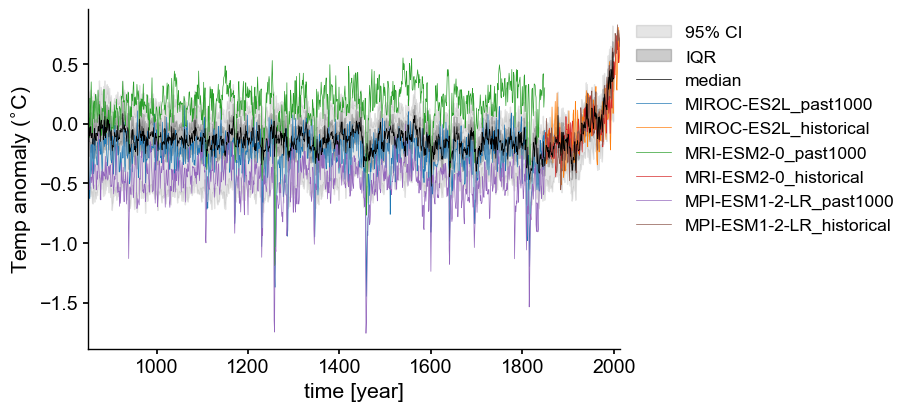
Great! Now we can see how the physics-based GCM simulations compare to the envelope of LMR reconstructions. All three models closely follow the increase captured by the reconstructions over the “historical” period (1850-2014) and show an approximately flat trend over the “past1000k” interval. Different GCMs use different approaches to describe the physics behind earth system processes. Therefore, it is not surprising to see slight offsets among them. Differences in the interannual variability stem partially from those differences, as well as different initial conditions for each simulation (the “Butterfly Effect”).
Punctuating the “past1000” interval are a series of abrupt decreases, coincident across all models, that correspond to volcanic eruptions. The recovery period length varies by model, but broadly, the temperature response follows the reconstructed trajectory. Based on these observations, we can conclude that the model physics are true to pre-industrial climate dynamics. Furthermore, the amplitude of the post-1850 increase is too large to be attributed to pre-1850 interannual variability alone, suggesting that anthropogenic forcing must have played a significant role. (This has been formally demonstrated many times elsewhere)
Spatial Visualization#
The global mean collapses spatial heterogeneity into a single summary statistic that is valuable for looking at over-arching or long-term trends where local nuance would distract. However, spatial patterns are essential for tracking dynamical processes, and are masked by the canceling effects of the spatial averaging inherent in a global mean. In many instances, one might want to diagnose spatio-temporal modes of variability ; we shall do so in a future notebook. For now, let’s just visualize the temperature response to the volcanic erutions mentioned earlier.
In April 5-15 1815, the Tambora volcano erupted, releasing a huge plume of sulfate aerosols into the atmosphere, causing global cooling for much of the following year. That is visible in the global mean anomaly timeseries plotted above, but now let’s also look into the spatial distribution for the three models and the LMR reconstruction at that time, and also the time evolution of the temperature anomaly in a specific place (in contrast to the global mean we looked at earlier). The final figure will contain:
Four snapshot maps (one for each model + LMR) that show the spatial distribution of temperature anomaly at a particular point in time
One plot of the time evolution of temperature anomaly at a specific location for each model + LMR
# let's select an arbitrary location at which to plot temperature evolution
lat = -10
lon = 100
# Tambora coordinates
tam_lat = -8.2479
tam_lon = 117.9911
time_pt = 1816
cmip6_snapshot_ps = {}
LMR#
Previously, we loaded 1000 traces of LMR global mean temperature anomaly. As a matter of computational practicality, the LMR spatial fields are only available as the ensemble mean for each of 20 iterations. Here, we will load those data from Pangeo-Forge and average over the 20 iterations so that we have a single field at each time step.
# Load data using Pangeo-Forge
store = "https://ncsa.osn.xsede.org/Pangeo/pangeo-forge/test/pangeo-forge/staged-recipes/recipe-run-1200/LMRv2p1_MCruns_ensemble_gridded.zarr"
lmr_ds_gridded = xr.open_dataset(store, engine='zarr', chunks={})
# temperature anomaly
lmr_ds_gridded_temp = lmr_ds_gridded['air_mean']
# spatial distribution of temperature amomaly (average of members)
lmr_ds_gridded_temp_mean = lmr_ds_gridded_temp.mean(dim='MCrun')
%%time
# this takes about 1.5 minutes
timeseries = lmr_ds_gridded_temp.sel({'lon': lon, 'lat': lat}, method="nearest")
timeseries = timeseries.chunk({'time':1}).compute()
MCrun_grps = [grp for grp in timeseries.groupby('MCrun')]
tmp_pss = []
for MCrun_grp in MCrun_grps:
MCrun = MCrun_grp[1]
tmp_pss.append(pyleo.Series(MCrun.time.dt.year, MCrun.data, time_unit='year', clean_ts=False,
verbose=False, value_name='MCrun {}'.format(MCrun_grp[0])))
CPU times: user 29.7 s, sys: 10.6 s, total: 40.3 s
Wall time: 2min 46s
surftemp_mean = timeseries.mean(dim='MCrun').compute()
snapshot_data = lmr_ds_gridded_temp_mean.sel(time=(lmr_ds_gridded_temp_mean.time.dt.year == time_pt))
cmip6_snapshot_ps['LMR2.1'] = {'snapshot':snapshot_data,
'ps_atloc': {'full':pyleo.Series(surftemp_mean.time.dt.year, surftemp_mean.data,
label='LMR2.1', time_unit='year', clean_ts=False,
verbose=False)}}
CMIP6#
Now we’ll return to the annualized anomaly calculation we did earlier to pull the spatial snapshot at time_pt and the time series at lat,lon for each of our CMIP6 models. Pulling all of these pieces together will make the plotting easier.
%%time
# this may take ~5 minutes
for institution in annualized_anomaly_spatial.keys():
exp_d = {}
for exp in annualized_anomaly_spatial[institution].keys():
# select spatial distribution at time_pt
if time_pt in annualized_anomaly_spatial[institution][exp].year:
snapshot_anom = annualized_anomaly_spatial[institution][exp].sel({'year':time_pt}).squeeze()
# select time series at lat,lon location
ts_atloc = annualized_anomaly_spatial[institution][exp].sel({'lon': lon, 'lat': lat}, method="nearest").chunk(
{'year':len(annualized_anomaly_spatial[institution][exp].year)}).squeeze().compute()
exp_d[exp] = pyleo.Series(ts_atloc.year, ts_atloc.data, time_unit='year',
clean_ts=False, label= '_'.join([institution, exp]),
verbose=False)
cmip6_snapshot_ps[institution]= {'snapshot':snapshot_anom, 'ps_atloc':exp_d}
CPU times: user 2min 38s, sys: 47.3 s, total: 3min 26s
Wall time: 9min 55s
Combined figure#
Finally, we’ll build the figure. For more details about building filled contour maps and wrangling color bars, check out this lifehack notebook and for more on dashboards, check out this science bit.
def make_scalar_mappable(lims, cmap, n=None):
ax_norm = mpl.colors.Normalize(vmin=min(lims), vmax=max(lims), clip=False)
if n is None:
ax_cmap = plt.get_cmap(cmap)
else:
ax_cmap = plt.get_cmap(cmap, n)
ax_sm = cm.ScalarMappable(norm=ax_norm, cmap=ax_cmap)
return ax_sm
lims = [np.abs(cmip6_snapshot_ps[key]['snapshot'].max().compute()) for key in cmip6_snapshot_ps.keys()]
lims += [np.abs(cmip6_snapshot_ps[key]['snapshot'].min().compute()) for key in cmip6_snapshot_ps.keys()]
# establish scale
ax2_Li_1 = max(lims)
ax2_levels = np.around(np.linspace(-ax2_Li_1, ax2_Li_1, 15), decimals=1)
# make scalar mappable
ax2_sm = make_scalar_mappable([ax2_Li_1, -ax2_Li_1], 'RdBu_r', 15)
cf2_kwargs = {'cmap':ax2_sm.cmap, 'norm' : ax2_sm.norm}
nc = 21
fig = plt.figure(figsize=(12, 8))
gs = gridspec.GridSpec(3, 3, wspace=0.05, hspace=.2,width_ratios=[3,3,.25], height_ratios=[3,3,3])
# add subplot with specified map projection and coastlines (GeoAxes)
gs_squares = [gs[0, 0], gs[0, 1], gs[1, 0], gs[1, 1]]
axs = [fig.add_subplot(sqr, projection=ccrs.Robinson(central_longitude=0)) for sqr in gs_squares]
for ik, key in enumerate(['LMR2.1', 'MIROC', 'MPI', 'MRI']):
axs[ik].add_feature(cfeature.COASTLINE, edgecolor='k',linewidth=.5)
# place data on coordinate system with continuous x axis (longitude axis)
tas_c, lonc = cutil.add_cyclic_point(cmip6_snapshot_ps[key]['snapshot'], cmip6_snapshot_ps[key]['snapshot']['lon'])
# plot contourf on ax2 (geosubplot)
cf2 = axs[ik].contourf(lonc,cmip6_snapshot_ps[key]['snapshot']['lat'],tas_c.squeeze(),nc, levels=ax2_levels,
transform=ccrs.PlateCarree(), **cf2_kwargs)
axs[ik].scatter(lon, lat, transform=ccrs.PlateCarree())
axs[ik].set_title(key)
axs[ik].scatter(tam_lon, tam_lat, marker='^', color='k', transform=ccrs.PlateCarree())
# add annotations (colorbar, title)
ax2_cb = fig.add_subplot(gs[:2, 2])
cb2 = plt.colorbar(ax2_sm,cax=ax2_cb, orientation='vertical',label="\xb0C",
ticks=[loc for ik, loc in enumerate(ax2_levels) if ik%2>0])
cb2.minorticks_off()
# time series
ax_ts = fig.add_subplot(gs[2, :2])
ax_ts.axvline(x=time_pt, alpha=.5)
for MCrun_ps in tmp_pss:
MCrun_ps.plot(ax=ax_ts, color='k', alpha=.15, linewidth=.5)
# CMIP6 trajectories
for key in cmip6_snapshot_ps.keys():
for exp in cmip6_snapshot_ps[key]['ps_atloc'].keys():
cmip6_snapshot_ps[key]['ps_atloc'][exp].plot(ax=ax_ts, linewidth=.5, alpha=.5)
ax_ts.legend(bbox_to_anchor=(1,1))
ax_ts.set_xlim([1600, 2014])
ax_ts.set_ylabel('Annualized TAS anomaly (\xb0C)');
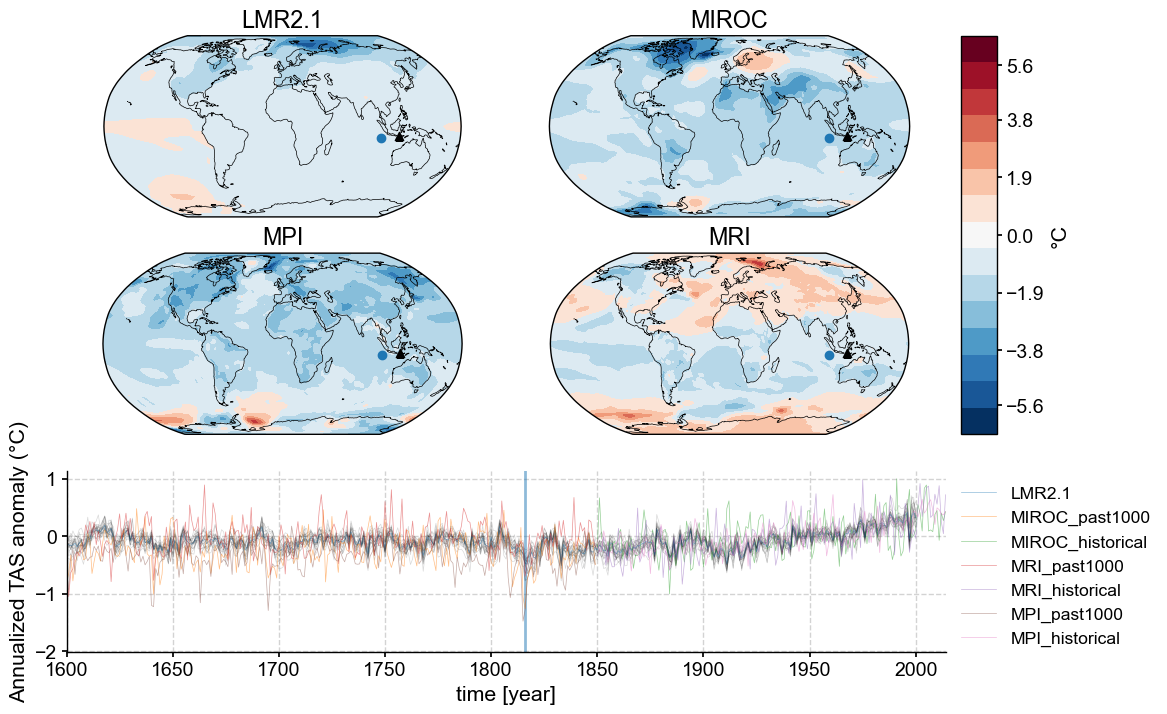
Summary#
Comparing model output to data is a critical step in assessing how well a physics-based model describes the Earth system. Here we demonstrated how to look at time series data next to spatial snapshots to tease out the details behind the larger patterns. There are many more potential things we could do with this. In future notebooks, we will:
map the multivariate response to volcanic eruptions (see VICS dashboards)
analyze the main modes of climate variability in reconstructions and simulations.
Resources and references#
Citations |
|---|
Hakim, G. J., Emile-Geay, J., Steig, E. J., Noone, D., Anderson, D. M., Tardif, R., Steiger, N., and Perkins, W. A. (2016), The last millennium climate reanalysis project: Framework and first results, J. Geophys. Res. Atmos., 121, 6745– 6764, doi:10.1002/2016JD024751. |
Tardif, R., Hakim, G. J., Perkins, W. A., Horlick, K. A., Erb, M. P., Emile-Geay, J., Anderson, D. M., Steig, E. J., and Noone, D.: Last Millennium Reanalysis with an expanded proxy database and seasonal proxy modeling, Clim. Past, 15, 1251–1273, https://doi.org/10.5194/cp-15-1251-2019 , 2019. |
Neukom, R., L. A. Barboza, M. P. Erb, F. Shi, J. Emile-Geay, M. N. Evans, J. Franke, D. S. Kaufman, L. Lücke, K. Rehfeld, A. Schurer, F. Zhu, S. Br ̈onnimann, G. J. Hakim, B. J. Henley, F. C. Ljungqvist, N. McKay, V. Valler, and L. von Gunten (2019), Consistent multidecadal variability in global temperature reconstructions and simulations over the common era, Nature Geoscience, 12(8), 643–649, doi:10.1038/s41561-019-0400-0. |
Kageyama, M., Braconnot, P., Harrison, S. P., Haywood, A. M., Jungclaus, J. H., Otto-Bliesner, B. L., Peterschmitt, J.-Y., Abe-Ouchi, A., Albani, S., Bartlein, P. J., Brierley, C., Crucifix, M., Dolan, A., Fernandez-Donado, L., Fischer, H., Hopcroft, P. O., Ivanovic, R. F., Lambert, F., Lunt, D. J., Mahowald, N. M., Peltier, W. R., Phipps, S. J., Roche, D. M., Schmidt, G. A., Tarasov, L., Valdes, P. J., Zhang, Q., and Zhou, T.: The PMIP4 contribution to CMIP6 – Part 1: Overview and over-arching analysis plan, Geosci. Model Dev., 11, 1033–1057, https://doi.org/10.5194/gmd-11-1033-2018, 2018. |