
Uniform time sampling with Pyleoclim#
Preamble#
A common issue in the paleosciences is the presence of uneven time spacing between consecutive observations. While pyleoclim includes several methods that can deal with this effectively, there are certain applications for which it is ncessary to place the records on a uniform time axis. In this tutorial you’ll learn a few ways to do with pyleoclim.
Goals:#
Become familiar with time regridding methods in Pyleoclim
Reading Time:
10 minutes
Keywords#
Signal Processing; Visualization
Pre-requisites#
None. This tutorial assumes basic knowledge of Python. If you are not familiar with this coding language, check out this tutorial: http://linked.earth/LeapFROGS/.
Relevant Packages#
Matplotlib
Data Description#
Jouzel, J., Masson-Delmotte, V., Cattani, O., Dreyfus, G., Falourd, S., Hoffmann, G., … Wolff, E. W. (2007). Orbital and millennial Antarctic climate variability over the past 800,000 years. Science (New York, N.Y.), 317(5839), 793–796. doi:10.1126/science.1141038
Demonstration#
Let’s import the packages needed for this tutorial:
%load_ext watermark
import pyleoclim as pyleo
import matplotlib.pyplot as plt
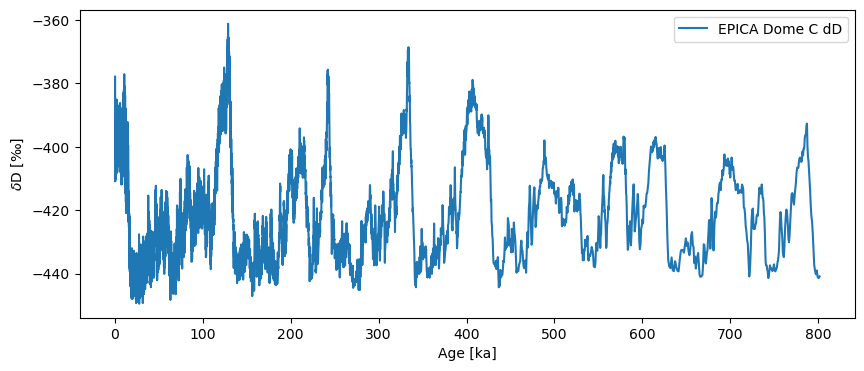
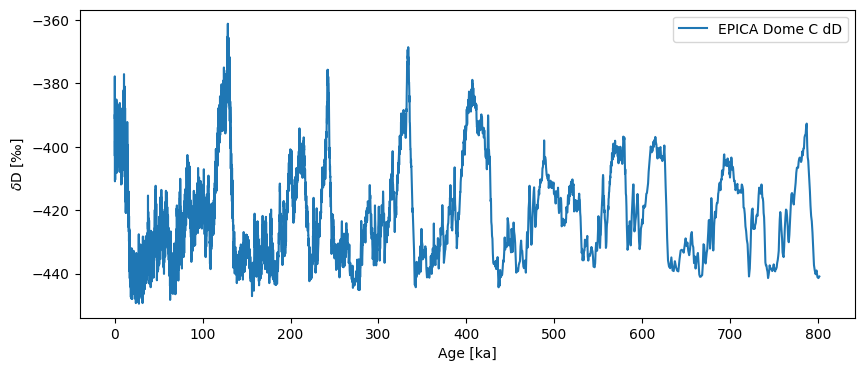
The dataset ships with Pyleoclim, so it is very quick to load. However, the original timescale is in years BP, which gets unwieldy after counting through 800,000 of them. We thus convert to “ky BP”, using intuitive semantics:
tsy = pyleo.utils.load_dataset('EDC-dD')
ts = tsy.convert_time_unit('ky BP')
fig, ax = ts.plot()
<<<<<<< local
=======
>>>>>>> remote
First we should check whether this is necessary with the .is_evenly_spaced() method:
ts.is_evenly_spaced()
False
An uneven resolution#
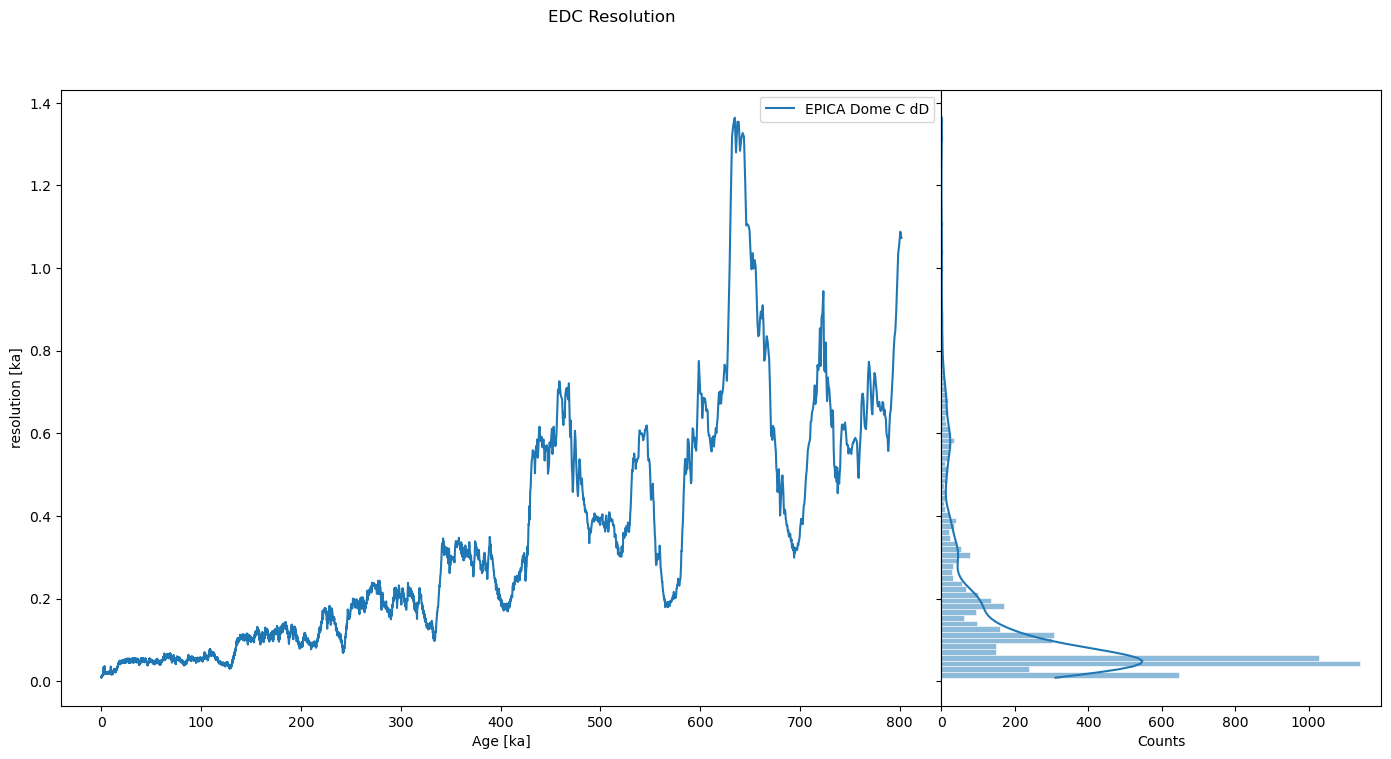
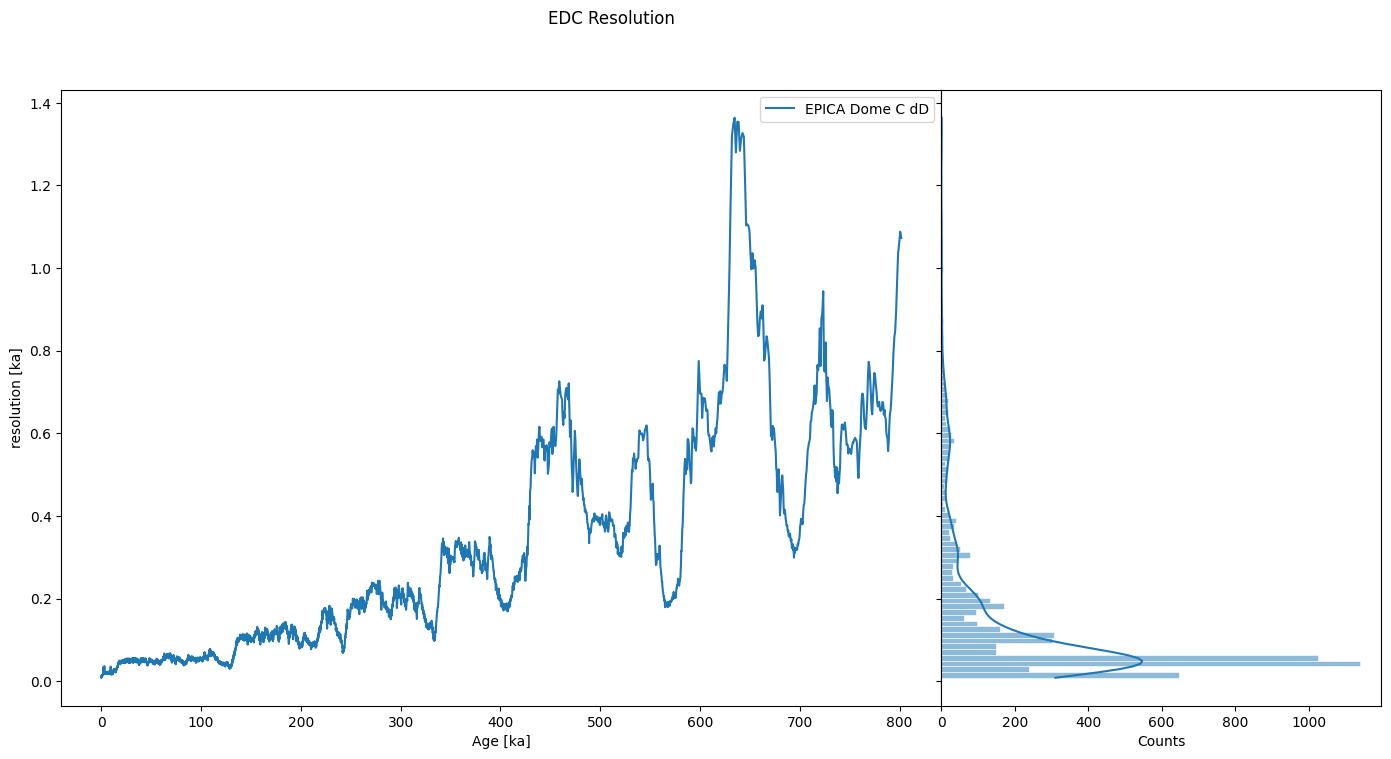
First we inspect the records’ resolution, i.e. the distribution and sequence of its time increments. Lucky for us, there is a class dedicated to that: Resolution, which ships with plotting and summary methods that makes it easy to see what is happening:
res = ts.resolution()
res.describe()
{'nobs': np.int64(5784),
'minmax': (np.float64(0.008244210009855486), np.float64(1.3640000000207237)),
'mean': np.float64(0.13859329637102363),
'variance': np.float64(0.029806736482500852),
'skewness': np.float64(2.6618614618357794),
'kurtosis': np.float64(8.705801510816693),
'median': np.float64(0.05813225000042621)}
res.dashboard(title='EDC Resolution')
(<Figure size 1100x800 with 2 Axes>,
{'res': <Axes: xlabel='Age [ka]', ylabel='resolution [ka]'>,
'res_hist': <Axes: xlabel='Counts'>})
<<<<<<< local
=======
>>>>>>> remote
We can see that the series is very unevenly spaced, with a resolution of ~100y at the beginning (top), increasing to over 1000y near the end (bottom) of the core. There are a variety of reasons why we might want to place these data on an even time grid, usually to apply a technique that requires them to be evenly spaced (most timeseries methods make this assumption). For instance, a filter, a detrending method, and so on.
There are a few different methods available in Pyleoclim to place them on a uniform axis: interpolating, binning, resampling and coarse graining via a Gaussian kernel. Let’s look at them in sequence.
Solution 1: Interpolation#
Interpolation projects the data onto an evenly spaced time axis with a distance between points (step size) of our choosing. The default step size is the mean spacing between consecutive points. There are a variety of different methods by which the data can be interpolated, these being: linear, nearest, zero, slinear, quadratic, cubic, previous, and next. More on these and their associated key word arguments can be found in the documentation. By default, .interp() implements linear interpolation:
ts_linear = ts.interp()
Let’s check whether or not the series is now evenly spaced:
ts_linear.is_evenly_spaced()
True
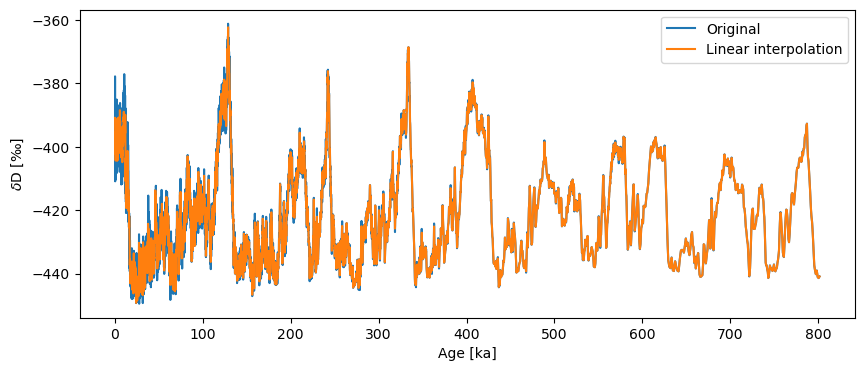
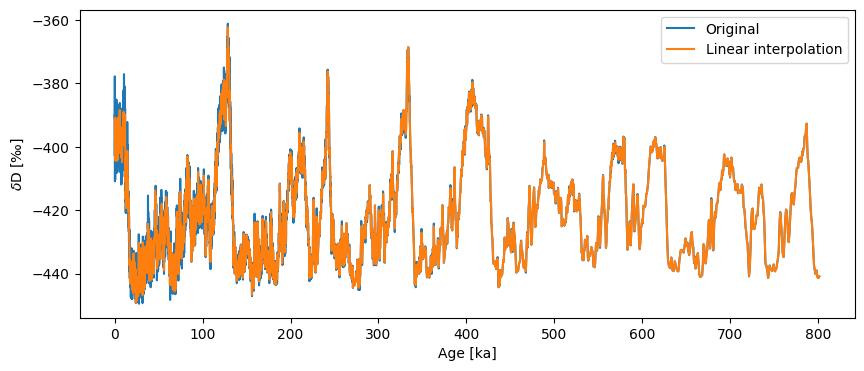
Success! Let’s take a look at our handiwork.
fig, ax = ts.plot(label='Original')
ts_linear.plot(ax=ax,label='Linear interpolation')
<Axes: xlabel='Age [ka]', ylabel='$\\delta \\mathrm{D}$ [‰]'>
<<<<<<< local
=======
>>>>>>> remote
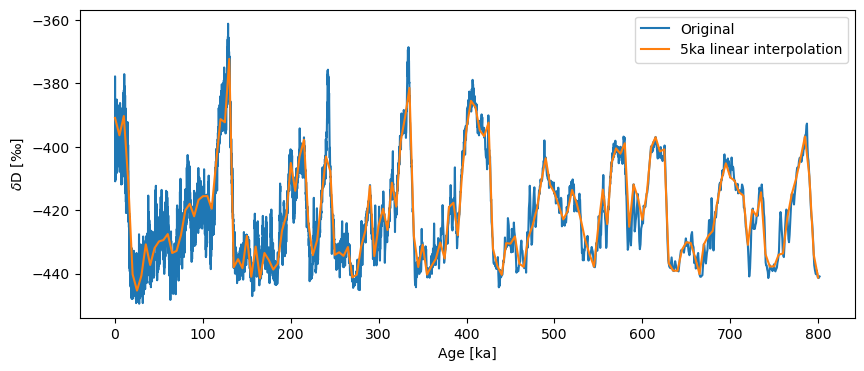
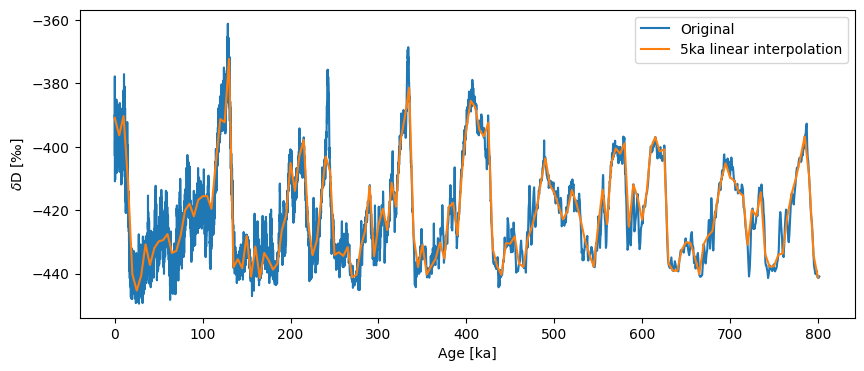
If we wanted a coarser resolution, we need only specify the step parameter.
ts_linear = ts.interp(step=5)
ts_linear.label = '5ka linear interpolation'
fig, ax = ts.plot(label='Original')
ts_linear.plot(ax=ax)
<Axes: xlabel='Age [ka]', ylabel='$\\delta \\mathrm{D}$ [‰]'>
<<<<<<< local
=======
>>>>>>> remote
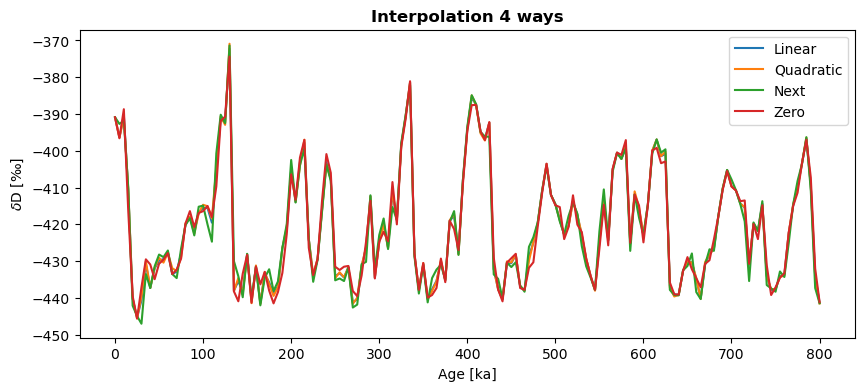
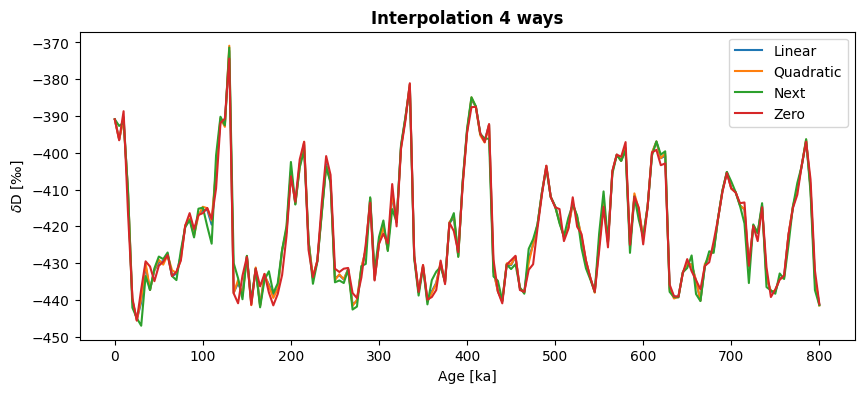
Linear interpolation is generally safest, because it makes the fewest assumptions. However, for coarse time grids, it can look a little jagged. Let’s compare a few of the different methods with one another just to see how they might differ:
ts_quadratic=ts.interp(method='quadratic',step=5)
ts_next = ts.interp(method='next',step=5)
ts_zero = ts.interp(method='zero',step=5)
fig,ax = ts_linear.plot(label='Linear')
ts_quadratic.plot(ax=ax,label='Quadratic')
ts_next.plot(ax=ax,label='Next')
ts_zero.plot(ax=ax,label='Zero')
ax.set_title('Interpolation 4 ways',fontweight='bold')
Text(0.5, 1.0, 'Interpolation 4 ways')
<<<<<<< local
=======
>>>>>>> remote
You can see how the methods can produce fairly similar results. If we fiddled more with keyword arguments, the differences would be even more obvious. Play around a bit and read the documentation to find the solution that best suits your needs.
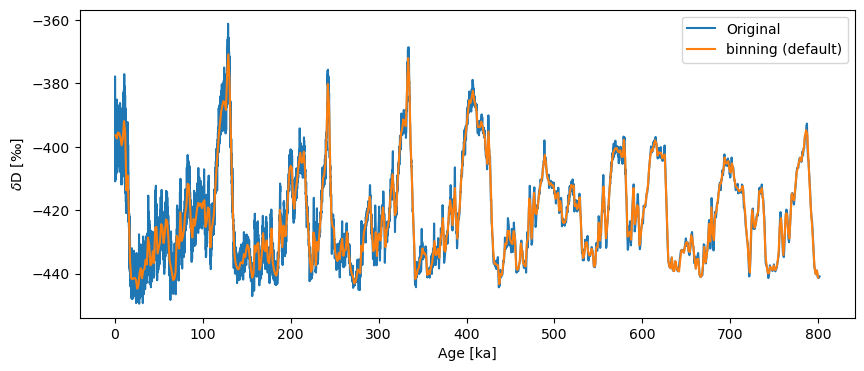
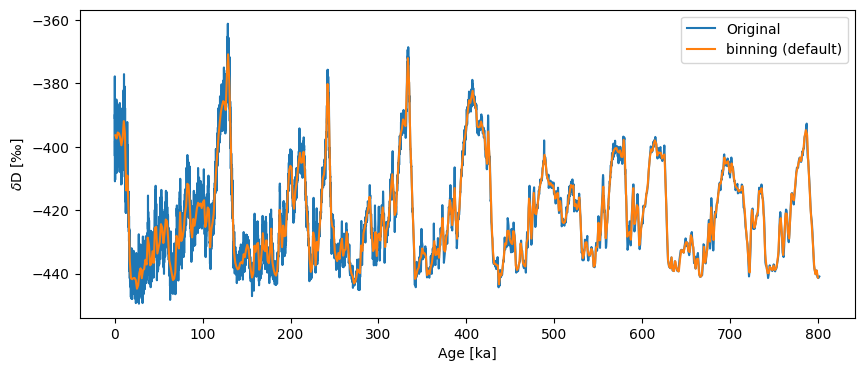
Solution 2: Binning#
Instead of interpolating we could average the series values over uniform bins. The defaults for binning are inherently quite conservative, picking as bin size the coarsest time spacing present in the dataset, and averaging data over a uniform sequence of such intervals:
ts_bin = ts.bin()
ts_bin.label = 'binning (default)'
fig, ax = ts.plot(label='Original')
ts_bin.plot(ax=ax)
<Axes: xlabel='Age [ka]', ylabel='$\\delta \\mathrm{D}$ [‰]'>
<<<<<<< local
=======
>>>>>>> remote
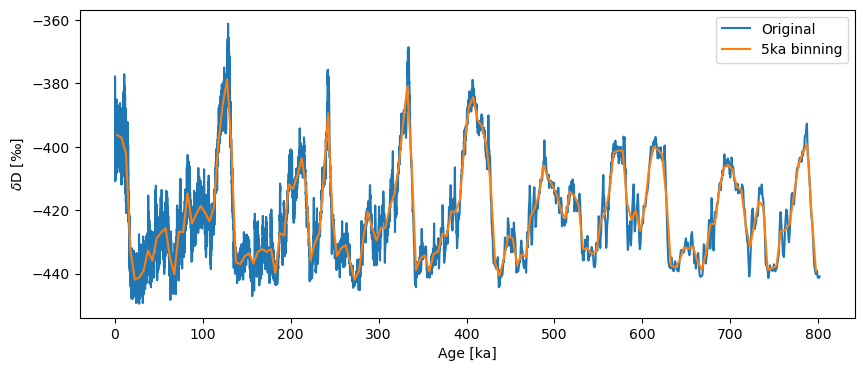
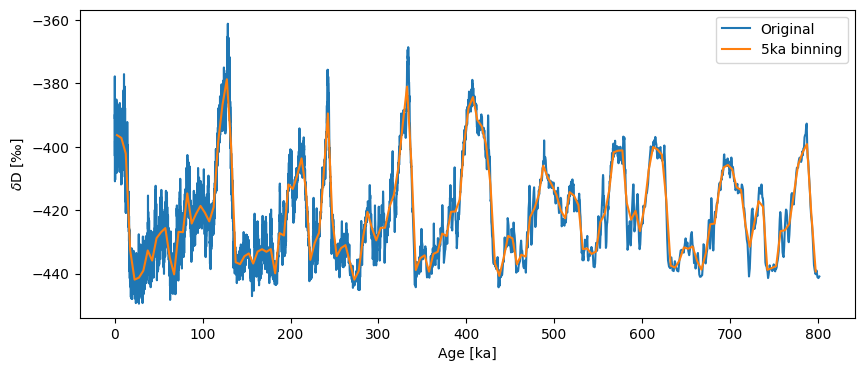
If we want this to be less conservative we can set the bin size using the bin_size key word argument, but that means the series is no longer guaranteed to be evenly spaced.
ts_bin = ts.bin(bin_size=5)
ts_bin.label='5ka binning'
ts_bin.is_evenly_spaced()
True
fig,ax = ts.plot(label='Original')
ts_bin.plot(ax=ax)
<Axes: xlabel='Age [ka]', ylabel='$\\delta \\mathrm{D}$ [‰]'>
<<<<<<< local
=======
>>>>>>> remote
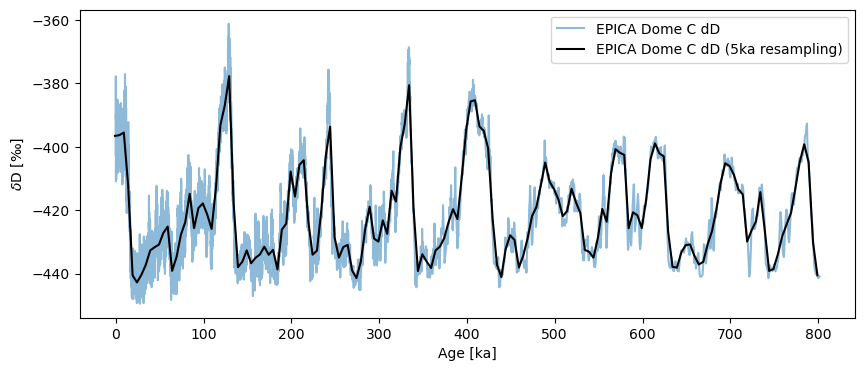
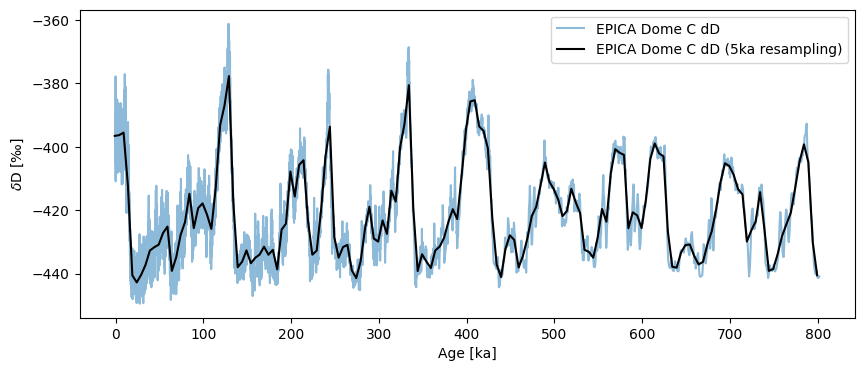
Solution 3: Resampling#
As introduced in the pandas demo, another option is to use the pandas resampler, then aggregate the data in some way, e.g. by averaging (though resample offers many more options, few of which are helpful to a paleoclimatologist). Let’s stick with goold old averaging, then:
ts5k = ts.resample('5ka').mean()
fig, ax = ts.plot(alpha=.5)
ts5k.plot(ax=ax,color='black')
<Axes: xlabel='Age [ka]', ylabel='$\\delta \\mathrm{D}$ [‰]'>
<<<<<<< local
=======
>>>>>>> remote
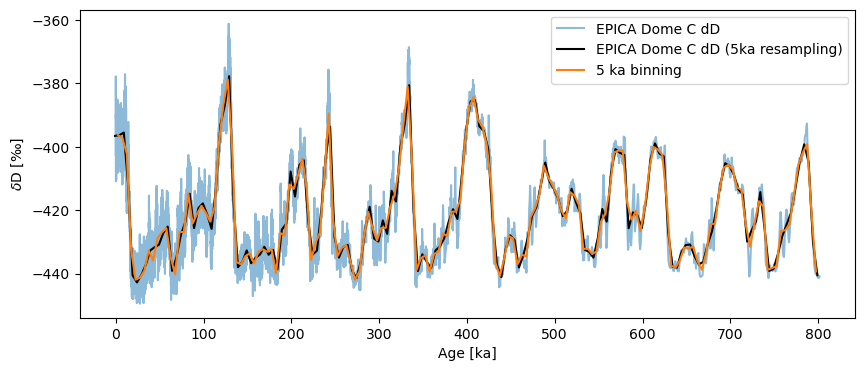
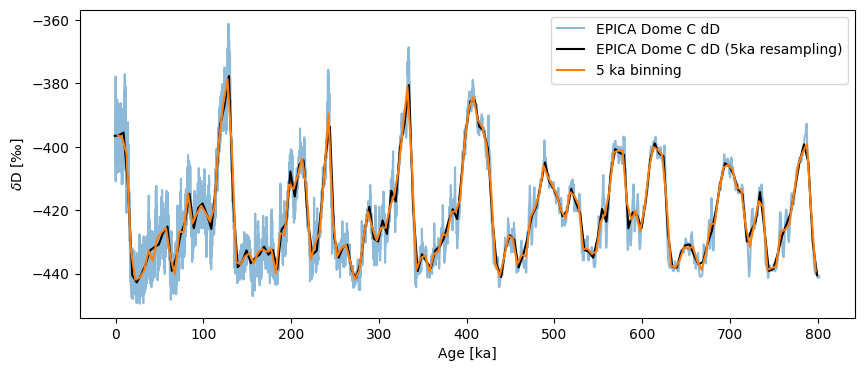
One nice thing is that resample automatically updates the Series label for you. It also understand time semantics, so you can specify units, as we’ve done here. If you think it looks very much like binning, you are not wrong. Let’s line them up to better see the effect:
fig, ax = ts.plot(alpha=.5)
ts5k.plot(ax=ax,color='black')
ts_bin.plot(ax=ax,label='5 ka binning')
<Axes: xlabel='Age [ka]', ylabel='$\\delta \\mathrm{D}$ [‰]'>
<<<<<<< local
=======
>>>>>>> remote
Indeed, they are very close.
Solution 4: Coarsening with a Gaussian kernel#
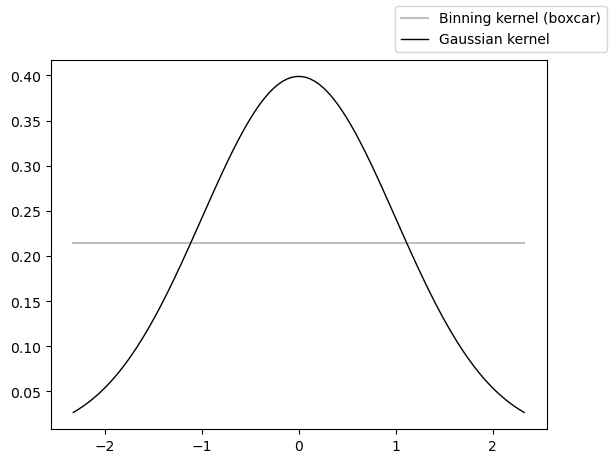
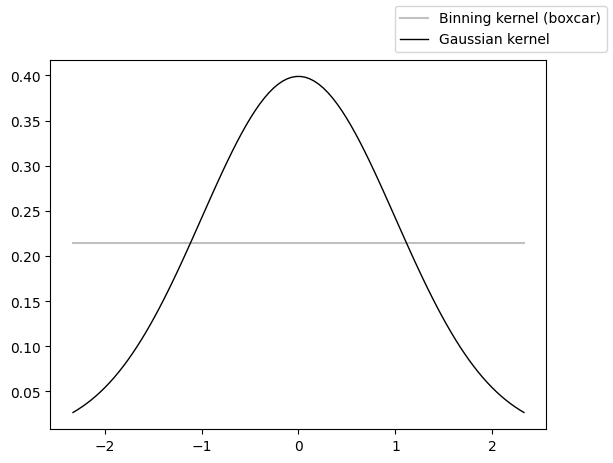
The last option is to coarsen the series using a Gaussian kernel (Rehfeld et al. (2011)) via the .gkernel() method. Like .bin() this technique is conservative and uses the max space between points as the default spacing. Unlike .bin(), .gkernel() uses a Gaussian kernel to calculate the weighted average of the time series over these intervals.
from scipy.stats import norm
import numpy as np
rv = norm()
x = np.linspace(norm.ppf(0.01), norm.ppf(0.99), 100)
unif = np.ones_like(x)/np.ptp(x)
fig, ax = plt.subplots()
ax.plot(x, unif, color='silver',label='Binning kernel (boxcar)')
ax.plot(x, rv.pdf(x), 'k-', lw=1, label='Gaussian kernel')
fig.legend()
<<<<<<< local <modified: text/plain>
<matplotlib.legend.Legend at 0x3570de360>
=======
<matplotlib.legend.Legend at 0x14eb31190>
>>>>>>> remote <modified: text/plain>
<<<<<<< local
=======
>>>>>>> remote
Compared with binning’s boxcar, this offers the possibility of centering the average on each observation, dropping off smoothly away (as opposed to brutally dropping off to 0 at the bin’s edge). Let’s see it in action:
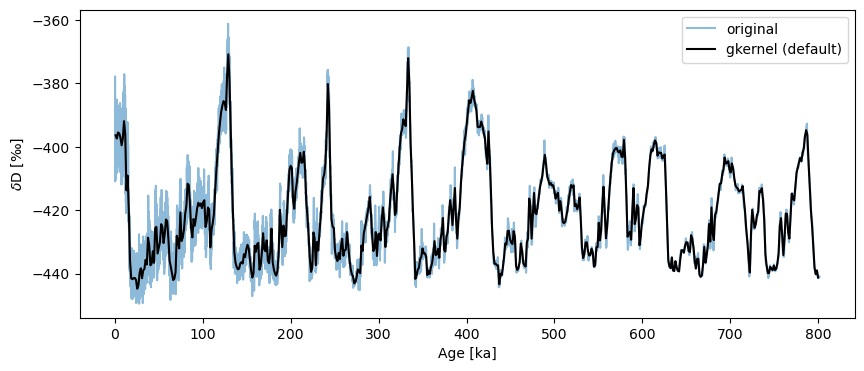
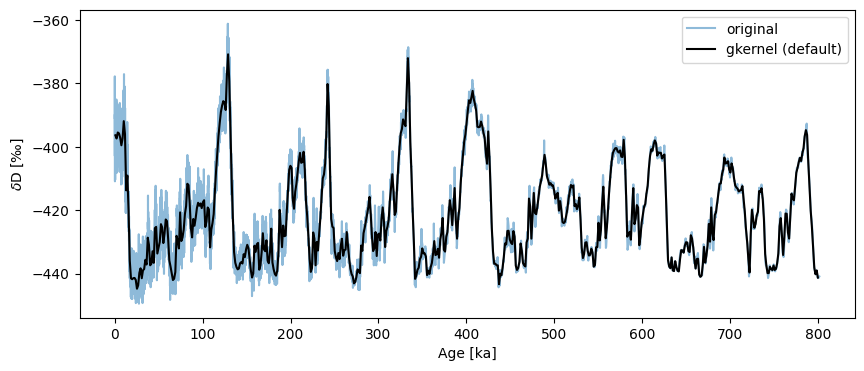
ts_gk = ts.gkernel()
fig,ax = ts.plot(label='original', alpha=.5)
ts_gk.plot(ax=ax,label='gkernel (default)',color='black')
<Axes: xlabel='Age [ka]', ylabel='$\\delta \\mathrm{D}$ [‰]'>
<<<<<<< local
=======
>>>>>>> remote
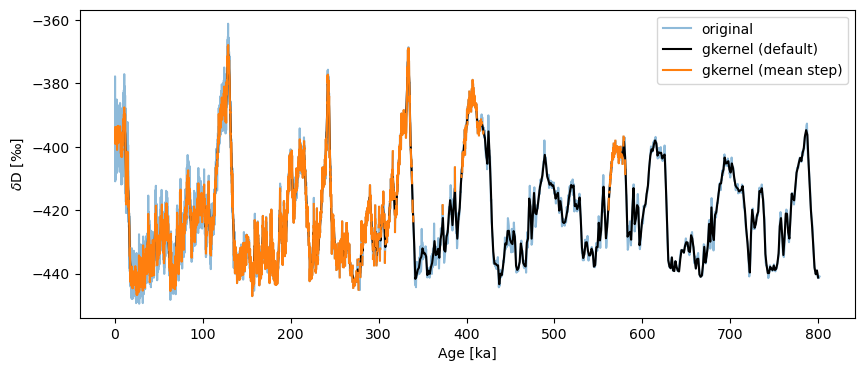
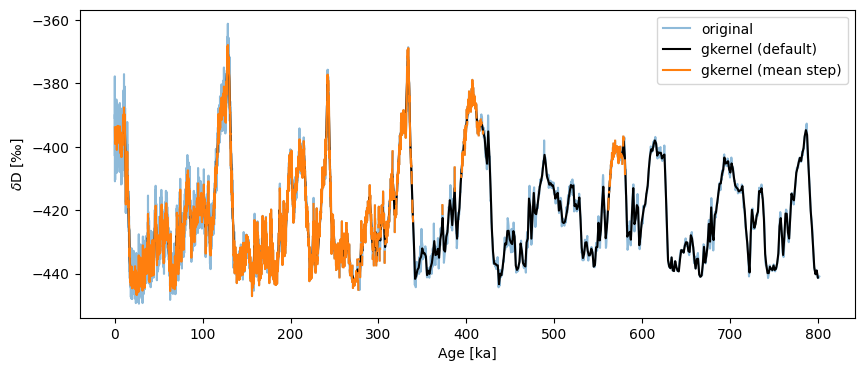
Though the default uses the maximum bin size, the result is relatively smooth. If one gets greedy and grabs the mean step size (here, ~138y), bad surprises await:
fig,ax = ts.plot(label='original', alpha=.5)
ts_gk.plot(ax=ax,label='gkernel (default)',color='black')
ts.gkernel(step_style='mean').plot(label='gkernel (mean step)',color='C1',ax=ax)
<Axes: xlabel='Age [ka]', ylabel='$\\delta \\mathrm{D}$ [‰]'>
<<<<<<< local
=======
>>>>>>> remote
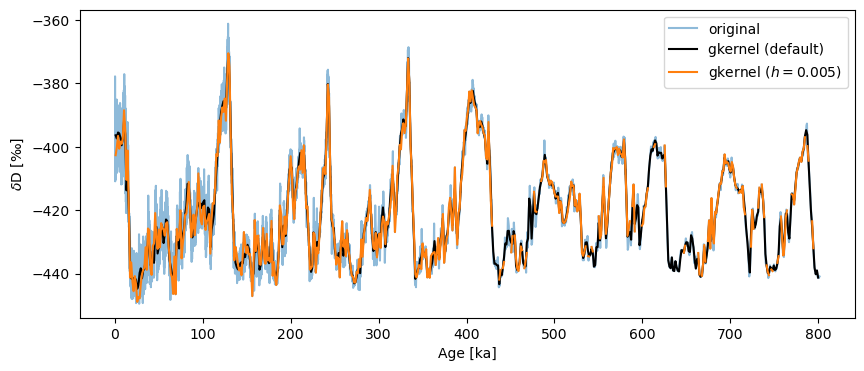
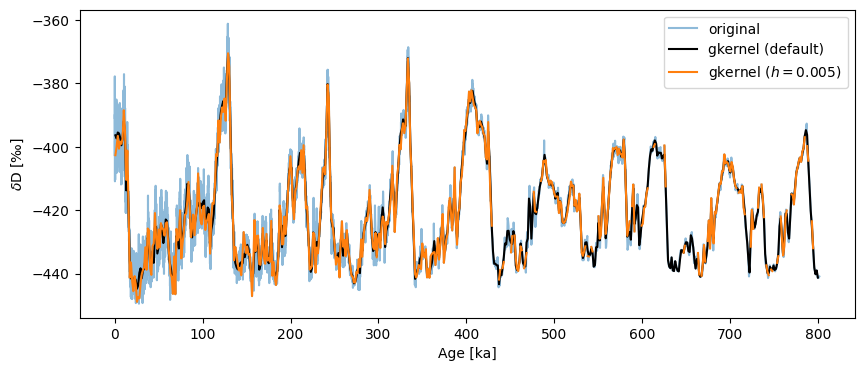
What is happening here is that we’re asking the method to make up data where it cannot find any (bins smaller than the actual spacing between points), so it protests silently by outputting NaNs over those intervals. In a plot like this, NaNs are invisible, hence the relative absence of orange ink prior to 400 ky BP on the plot above.
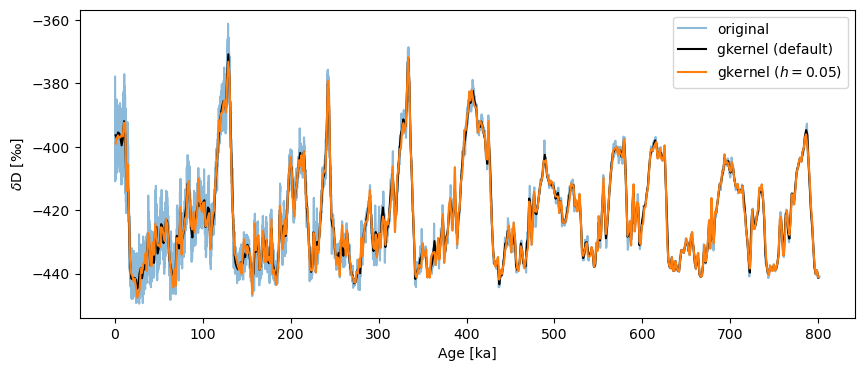
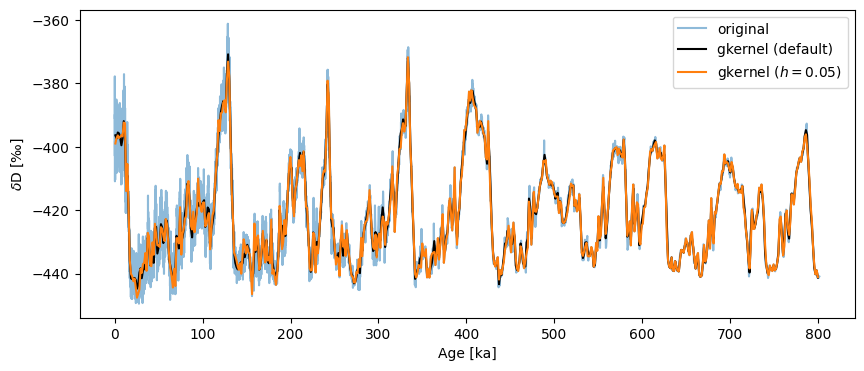
gkernel has another parameter: the kernel bandwidth \(h\), which governs the width of the Gaussian used for the averaging. The default value is 3, and it typically has a weak influence over the result. For instance:
fig,ax = ts.plot(label='original', alpha=.5)
ts_gk.plot(ax=ax,label='gkernel (default)',color='black')
ts.gkernel(h=.05).plot(label='gkernel ($h=0.05$)',color='C1',ax=ax)
<Axes: xlabel='Age [ka]', ylabel='$\\delta \\mathrm{D}$ [‰]'>
<<<<<<< local
=======
>>>>>>> remote
Insisting on a an overly narrow kernel will also result in bins with no values:
fig,ax = ts.plot(label='original', alpha=.5)
ts_gk.plot(ax=ax,label='gkernel (default)',color='black')
ts.gkernel(h=.005).plot(label='gkernel ($h=0.005$)',color='C1',ax=ax)
<Axes: xlabel='Age [ka]', ylabel='$\\delta \\mathrm{D}$ [‰]'>
<<<<<<< local
=======
>>>>>>> remote
Battle Royale#
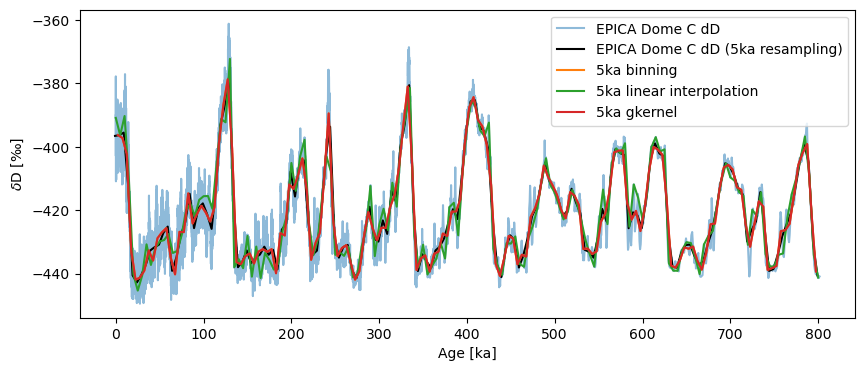
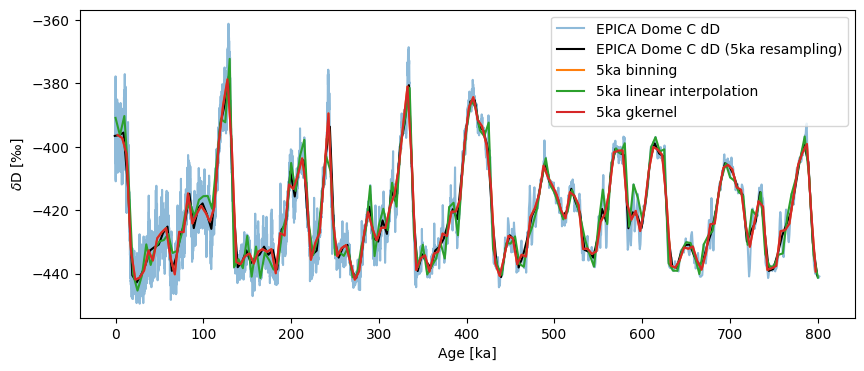
Let’s now look at how these methods compare to place the data on an even 5ka grid:
fig, ax = ts.plot(alpha=.5)
ts5k.plot(ax=ax,color='black')
ts_bin.plot(ax=ax)
ts_linear.plot(ax=ax)
ts.gkernel(step=5).plot(ax=ax, label='5ka gkernel')
<Axes: xlabel='Age [ka]', ylabel='$\\delta \\mathrm{D}$ [‰]'>
<<<<<<< local
=======
>>>>>>> remote
The results are quite similar. One can see that gkernel is a tad smoother than the lot, interp more jerky than the lot.
Summary#
As of version 0.11.0, pyleoclim features no fewer than 4 methods to place a timeseries on a uniform time axis. Each of these methods has its own keyword arguments that can be adjusted to produce different results. A comprehensive investigation of these arguments and how they affect the outcome of the imputation is left as an exercise for the reader. In general, we recommend trying several strategies to check that your analysis is not overly sensitive to any particular choice of method/parameter.
Equally important is to know when not to apply these methods: for spectral and wavelet analysis, pyleoclim implements methods that do not require evenly-spaced data. In those cases, one can happily abstain from regridding. In all other cases, however, you should feel free to regrid with abandon, but always be mindful of robustness.
%watermark -n -u -v -iv -w
<<<<<<< local <modified: >
Last updated: Thu, 12 Mar 2026
Python implementation: CPython
Python version : 3.12.13
IPython version : 9.10.0
matplotlib: 3.10.8
numpy : 2.4.2
pyleoclim : 1.3.1b0
Watermark: 2.6.0
=======
Last updated: Thu, 12 Mar 2026
Python implementation: CPython
Python version : 3.12.11
IPython version : 9.6.0
matplotlib: 3.10.8
numpy : 2.4.3
pyleoclim : 1.3.1b0
Watermark: 2.6.0
>>>>>>> remote <modified: >