
Outlier Detection with Pyleoclim#
by Deborah Khider & Pin-Tzu Lee
Preamble#
Goals#
Understand outlier detection through clustering
Apply detection algorithm and understand the difference between the two algorithms used in Pyleoclim, namely k-means and DBSCAN.
Understand the diagnostic metrics returned by each algorithm
Understand the parameters and when to apply them
Reading time: 10 minutes
Keywords#
Outlier detection; anomaly detection; clustering; unsupervised machine learning.
Pre-requisites#
An understanding of clustering is useful
Relevant Packages#
scikit-learn
Data Description#
This tutorial makes use of the following dataset, stored in LiPD format:
Khider, D., Jackson, C. S., and Stott, L. D. (2014), Assessing millennial-scale variability during the Holocene: A perspective from the western tropical Pacific, Paleoceanography, 29, 143– 159, doi:10.1002/2013PA002534.
Demonstration#
Let’s import the necessary packages:
%load_ext watermark
import pyleoclim as pyleo
import pandas as pd
from pylipd.lipd import LiPD
# For clustering
from sklearn.datasets import make_blobs
from sklearn.cluster import DBSCAN
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import KMeans
from sklearn.neighbors import LocalOutlierFactor
from sklearn.metrics import silhouette_score
import math
import warnings
warnings.filterwarnings('ignore')
The watermark extension is already loaded. To reload it, use:
%reload_ext watermark
D = LiPD()
D.load('../data/MD982181.Khider.2014.lpd')
timeseries,df = D.get_timeseries(D.get_all_dataset_names(),to_dataframe=True)
df
Loading 1 LiPD files
100%|█████████████████████████████████████████████| 1/1 [00:00<00:00, 1.57it/s]
Loaded..
Extracting timeseries from dataset: MD982181.Khider.2014 ...
| mode | time_id | funding1_agency | funding1_grant | funding1_principalInvestigator | funding1_country | funding2_agency | funding2_principalInvestigator | funding2_country | funding2_grant | ... | paleoData_interpretation | paleoData_takenAtDepth | paleoData_inferredVariableType | paleoData_notes | paleoData_physicalSample_collectionmethod | paleoData_physicalSample_name | paleoData_physicalSample_housedat | paleoData_sensorGenus | paleoData_sensorSpecies | paleoData_calibration | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | paleoData | age | National Science Foundation | [AGS#1049238] | L. Stott | United States | National Science Foundation | L. Stott | United States | [AGS#1344514] | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | paleoData | age | National Science Foundation | [AGS#1049238] | L. Stott | United States | National Science Foundation | L. Stott | United States | [AGS#1344514] | ... | [{'variableDetail': 'calendar', 'rank': 1.0, '... | Depth | Age | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | paleoData | age | National Science Foundation | [AGS#1049238] | L. Stott | United States | National Science Foundation | L. Stott | United States | [AGS#1344514] | ... | [{'hasVariable': {'label': 'temperature'}, 'sc... | Depth | NaN | Average duplicates from paleo1measurementTable1 | Calypso Giant Corer | MD98-2181 | Oregon State University | Cibicidoides | mundulus | NaN |
| 3 | paleoData | age | National Science Foundation | [AGS#1049238] | L. Stott | United States | National Science Foundation | L. Stott | United States | [AGS#1344514] | ... | [{'scope': 'Isotope', 'interpdirection': 'posi... | depth_cm | d18O | NaN | NaN | NaN | NaN | NaN | NaN | [{'equation': 'T = 14.9 - 4.81(dc-dsw+0.27)', ... |
| 4 | paleoData | age | National Science Foundation | [AGS#1049238] | L. Stott | United States | National Science Foundation | L. Stott | United States | [AGS#1344514] | ... | [{'variableDetail': 'sea surface', 'local': 'l... | depth_cm | NaN | Average duplicates from paleo1measurementTable1 | Calypso Giant Corer | MD98-2181 | Oregon State University | Globigerinoides | ruber | NaN |
| 5 | paleoData | age | National Science Foundation | [AGS#1049238] | L. Stott | United States | National Science Foundation | L. Stott | United States | [AGS#1344514] | ... | [{'scope': 'Climate', 'interpdirection': 'posi... | depth_cm | Sea Surface Temperature | NaN | NaN | NaN | NaN | NaN | NaN | [{'equation': 'Mg/Ca = 0.5exp(0.08T)', 'uncert... |
| 6 | paleoData | age | National Science Foundation | [AGS#1049238] | L. Stott | United States | National Science Foundation | L. Stott | United States | [AGS#1344514] | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 7 | paleoData | age | National Science Foundation | [AGS#1049238] | L. Stott | United States | National Science Foundation | L. Stott | United States | [AGS#1344514] | ... | [{'local': 'local', 'interpdirection': 'positi... | depth_cm | NaN | Average duplicates from paleo1measurementTable1 | Calypso Giant Corer | MD98-2181 | Oregon State University | Globigerinoides | ruber | NaN |
| 8 | paleoData | age | National Science Foundation | [AGS#1049238] | L. Stott | United States | National Science Foundation | L. Stott | United States | [AGS#1344514] | ... | [{'scope': 'Age', 'rank': 1.0, 'hasVariable': ... | depth_cm | Age | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 9 | paleoData | age | National Science Foundation | [AGS#1049238] | L. Stott | United States | National Science Foundation | L. Stott | United States | [AGS#1344514] | ... | NaN | depth_cm | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 10 | paleoData | age | National Science Foundation | [AGS#1049238] | L. Stott | United States | National Science Foundation | L. Stott | United States | [AGS#1344514] | ... | NaN | depth_cm | NaN | NaN | Calypso Giant Corer | MD98-2181 | Oregon State University | Globigerinoides | ruber | NaN |
| 11 | paleoData | age | National Science Foundation | [AGS#1049238] | L. Stott | United States | National Science Foundation | L. Stott | United States | [AGS#1344514] | ... | [{'local': 'local', 'hasVariable': {'label': '... | depth_cm | NaN | NaN | Calypso Giant Corer | MD98-2181 | Oregon State University | Globigerinoides | ruber | NaN |
| 12 | paleoData | age | National Science Foundation | [AGS#1049238] | L. Stott | United States | National Science Foundation | L. Stott | United States | [AGS#1344514] | ... | [{'rank': 1.0, 'hasVariable': {'label': 'tempe... | depth_cm | NaN | NaN | Calypso Giant Corer | MD98-2181 | Oregon State University | Globigerinoides | ruber | NaN |
| 13 | paleoData | age | National Science Foundation | [AGS#1049238] | L. Stott | United States | National Science Foundation | L. Stott | United States | [AGS#1344514] | ... | NaN | depth_cm | NaN | NaN | Calypso Giant Corer | MD98-2181 | Oregon State University | Cibicidoides | mundulus | NaN |
| 14 | paleoData | age | National Science Foundation | [AGS#1049238] | L. Stott | United States | National Science Foundation | L. Stott | United States | [AGS#1344514] | ... | [{'hasVariable': {'label': 'd18Osw'}, 'local':... | depth_cm | NaN | NaN | Calypso Giant Corer | MD98-2181 | Oregon State University | Cibicidoides | mundulus | NaN |
| 15 | paleoData | age | National Science Foundation | [AGS#1049238] | L. Stott | United States | National Science Foundation | L. Stott | United States | [AGS#1344514] | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
16 rows × 87 columns
Let’s use the sea surface temperatures (SST) record:
row = df[df['paleoData_variableName']=='temperature']
ts = pyleo.Series(
time=row['age'].values[0],
value=row['paleoData_values'].values[0],
time_name = 'Age',
time_unit = 'yr BP',
value_name = 'SST',
value_unit = 'deg C',
label='MD982181.Khider.2014'
)
NaNs have been detected and dropped.
Time axis values sorted in ascending order
Let’s plot the timeseries:
ts.plot()
(<Figure size 1000x400 with 1 Axes>,
<Axes: xlabel='Age [yr BP]', ylabel='SST [deg C]'>)
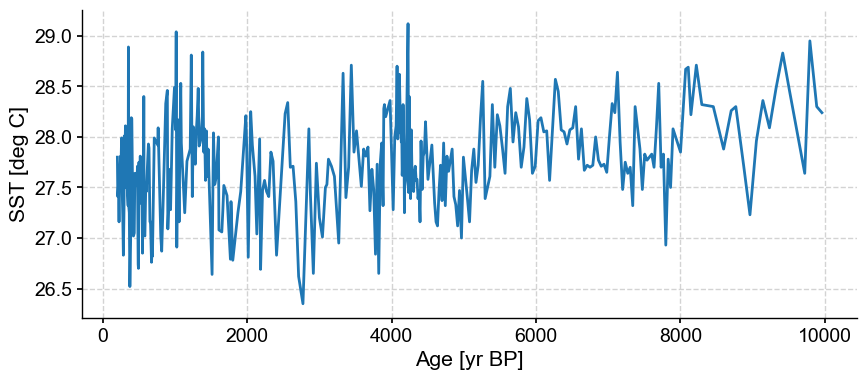
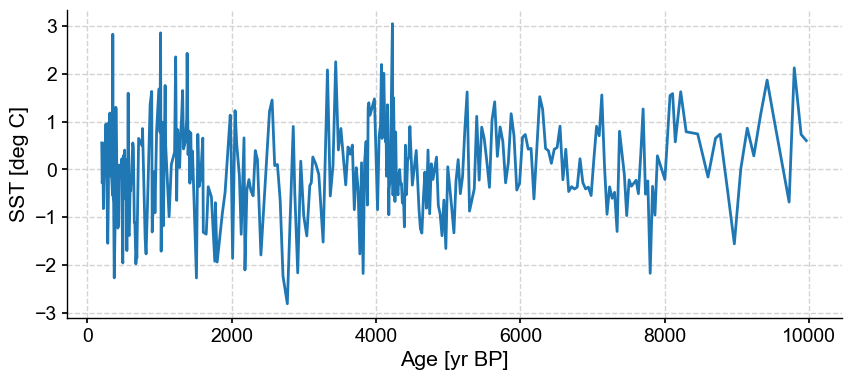
This record contains a long-term trend through the Holocence. In addition, it is fairly noisy, with some spurious spikes. Tempted to remove them by hand? Let’s use the outlier detection algorithm on this dataset first.
Unsupervised machine learning - clustering#
Unsupervised learning learns patterns from unlabeled data. One example of unsupervised learning is clustering, which groups a set of objects in such a way that objects in the same group (called a cluster) are more similar (in some sense) to each other than to those in other groups (clusters). Outliers can then be identified depending on how far they fall from the cluster. They are several methods for clustering. In Pyleoclim, we make use of two algorithms:
k-means, which is centroid based. The principle is simple: find the \(k\) cluster centers and assign the objects to the nearest cluster center, such that the squared distances from the cluster are minimized. This algorithm requires the number of clusters to be known in advance. Alternatively, one can sweep over a number of clusters and use an optimization metric to decide on the number of clusters present in the dataset. Outliers are then indentified as data falling from a certain distance away from the centroid or its local density compared to the local densities of its neighbors (LOF). We’ll elaborate more on outlier detection later.
DBSCAN is an example of density-based clustering, in which clusters are defined as areas of higher density than the remainder of the data set. Data that sit in sparse areas are usually considered to be outliers.
Let’s have a look on how these two methods work for clustering.
DBSCAN#
Pyleoclim makes use of the method in scikit-learn. Let’s import the package and run through an example:
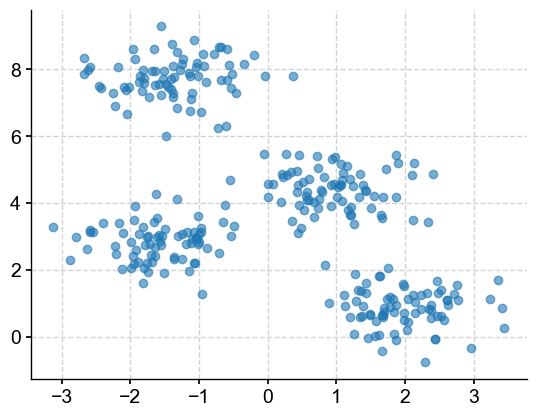
First, let’s make some random blobs of 300 data points for illustrative purposes. Let’s create four clusters, with data clustered within a 0.60 standard deviation.
X, y = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0)
plt.scatter(X[:,0], X[:,1], alpha=0.6)
<matplotlib.collections.PathCollection at 0x33f5998d0>
Have a look at the parameters for the DBSCAN algorithm. The most relevant ones are:
eps: Threshold \(\epsilon\). Two points are considered neighbors if the distance between the two points is below the threshold \(\epsilon\).min_samples: The minimum number of neighbors a given point should have in order to be classified as a core point. It’s important to note that the point itself is included in the minimum number of samples. If the value of this parameter is set to 8, then there must be at least 8 points to form a cluster.metric: The metric to use when calculating distance between instances in a feature array (i.e. euclidean distance).
Let’s have a look using semi-random values for eps and min_samples:
m = DBSCAN(eps=0.3, min_samples=5)
m.fit(X)
DBSCAN(eps=0.3)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
DBSCAN(eps=0.3)
The labels_ property contains the list of clusters and their respective points:
clusters = m.labels_
np.unique(clusters)
array([-1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
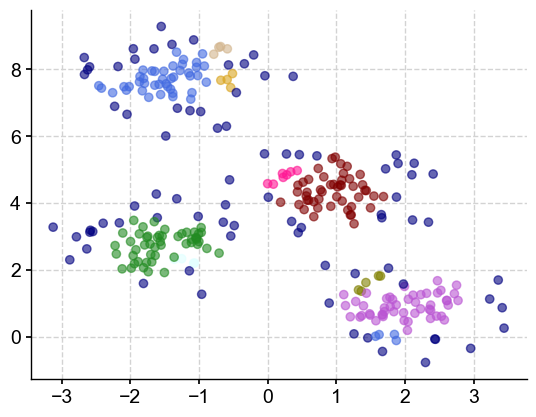
Using these particular values, DBSCAN identified 11 clusters (the points contained in the ‘-1’ label are considered outliers by the algorithm), which is more than the 4 blobs they were originally created. Let’s plot them in various colors. The outliers will be plotted in navy (dark blue):
colors = ['royalblue', 'maroon', 'forestgreen', 'mediumorchid', 'tan', 'deeppink', 'olive', 'goldenrod', 'lightcyan', 'navy']
vectorizer = np.vectorize(lambda x: colors[x % len(colors)])
plt.scatter(X[:,0], X[:,1], c=vectorizer(clusters), alpha=0.6)
<matplotlib.collections.PathCollection at 0x33efa2c10>
There seems to be a lot of outliers and clusters that seem to be very close to each other. Remember that we chose a distance threshold of 0.3. Let’s increase this value to 0.7:
m2 = DBSCAN(eps=0.7, min_samples=5)
m2.fit(X)
DBSCAN(eps=0.7)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
DBSCAN(eps=0.7)
clusters = m2.labels_
np.unique(clusters)
array([-1, 0, 1, 2])
We have identified 3 clusters (and other outliers).
colors = ['royalblue', 'maroon', 'forestgreen', 'navy']
vectorizer = np.vectorize(lambda x: colors[x % len(colors)])
plt.scatter(X[:,0], X[:,1], c=vectorizer(clusters), alpha=0.6)
<matplotlib.collections.PathCollection at 0x33f00e750>
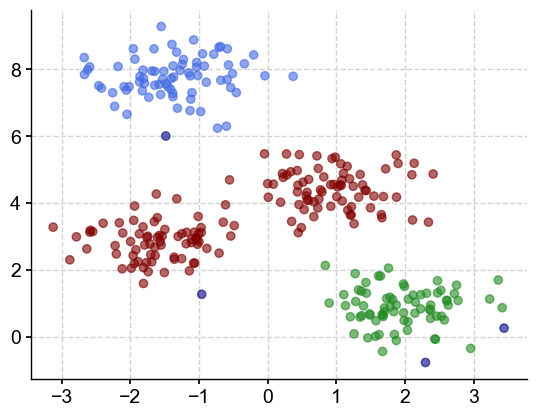
With this value of eps, we now have three clusters and some outliers. You may ask yourself, if this algortihm is so sensitive to the parameter values, how do I know which one to choose? One solution (the one implemented by Pyleoclim) is to sweep throught a range of values for eps and min_sample and evaluate the best combination using a performance metric, in this case, the silhouette score.
The Silhouette Coefficient is calculated using the mean intra-cluster distance (a) and the mean nearest-cluster distance (b) for each sample. The Silhouette Coefficient for a sample is (b - a) / max(a, b). To clarify, b is the distance between a sample and the nearest cluster that the sample is not a part of.
The best value is 1 and the worst value is -1. Values near 0 indicate overlapping clusters. Negative values generally indicate that a sample has been assigned to the wrong cluster, as a different cluster is more similar.
Let’s calculate the silhouette score for the two different eps values:
s1 = silhouette_score(y.reshape(-1, 1), m.labels_)
s1
-0.25666666666666665
The silhouette score for eps = 0.3 is negative and close to zero, which indicates that this really wasn’t an appropriate choice for parameter values.
s2 = silhouette_score(y.reshape(-1, 1), m2.labels_)
s2
0.41586666666666666
A silhouette score of 0.42 is definitely better, but let’s see if we can improve upon the score by sweeping across values of the parameters. Now, the question becomes, what are appropriate values for eps and min_samples to sweep over. Well, let’s start with min_samples.
Essentially, this is the number of samples to expect at a minimum in each cluster, which means that we need at least 2 samples. The maximum values will depend on the application but let’s assume that we don’t want more than 1/4 of the data:
min_samples_list = np.linspace(2,len(y)/4,50,dtype='int')
For the eps value, we can decide based on distance to the nearest neighbor:
from sklearn.neighbors import NearestNeighbors
neigh = NearestNeighbors(n_neighbors=5)
nbrs = neigh.fit(X)
distances, indices = nbrs.kneighbors(X)
distances = np.sort(distances, axis=0)
distances = distances[:,1]
plt.plot(distances)
plt.ylabel('distance')
Text(0, 0.5, 'distance')
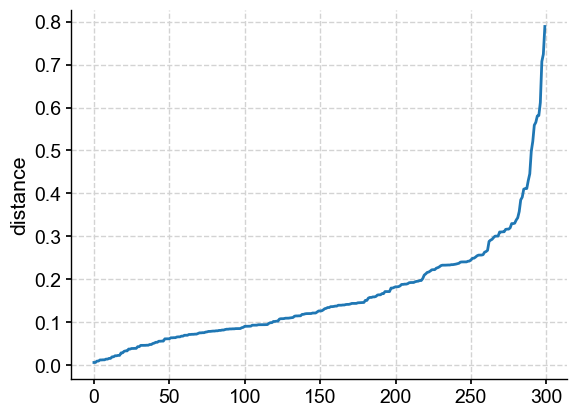
From this plot, it would make sense to sweep from 0.05 to 0.8. If you are familiar with DBSCAN, you know that this method can be used to define the “best” eps value as the “knee” of the curve (or elbow depending on your perspective). This would indicate that 0.3 would have been the best value; yet we have shown that it defnitely isn’t. For this reason, Pyleoclim does not emply this method by default and we caution against the use of it.
eps_list = np.linspace(0.05, 0.8, 20)
Now let’s sweep!… and keep track of a few things:
nbr_clusters=[] # the number of clusters
sil_score =[] # the silhouette score
eps_matrix=[] # tracking the value of eps for each min_sample
min_sample_matrix=[] # tracking the value of min_sample for each eps
for eps in eps_list:
for min_samples in min_samples_list:
eps_matrix.append(eps)
min_sample_matrix.append(min_samples)
m = DBSCAN(eps=eps, min_samples=min_samples)
m.fit(X)
nbr_clusters.append(len(np.unique(m.labels_)))
try:
sil_score.append(silhouette_score(X, m.labels_))
except:
sil_score.append(np.nan)
res = pd.DataFrame({'eps':eps_matrix,'min_samples':min_sample_matrix,'number of clusters':nbr_clusters,'silhouette score':sil_score})
res
| eps | min_samples | number of clusters | silhouette score | |
|---|---|---|---|---|
| 0 | 0.05 | 2 | 20 | -0.624168 |
| 1 | 0.05 | 3 | 2 | -0.224822 |
| 2 | 0.05 | 4 | 1 | NaN |
| 3 | 0.05 | 6 | 1 | NaN |
| 4 | 0.05 | 7 | 1 | NaN |
| ... | ... | ... | ... | ... |
| 995 | 0.80 | 69 | 1 | NaN |
| 996 | 0.80 | 70 | 1 | NaN |
| 997 | 0.80 | 72 | 1 | NaN |
| 998 | 0.80 | 73 | 1 | NaN |
| 999 | 0.80 | 75 | 1 | NaN |
1000 rows × 4 columns
And now let’s locate the maximum value of the silhouette score (which hopefully is close to 1):
res.loc[res['silhouette score']==np.max(res['silhouette score'])]
| eps | min_samples | number of clusters | silhouette score | |
|---|---|---|---|---|
| 905 | 0.760526 | 9 | 5 | 0.672543 |
| 906 | 0.760526 | 10 | 5 | 0.672543 |
| 955 | 0.800000 | 9 | 5 | 0.672543 |
| 956 | 0.800000 | 10 | 5 | 0.672543 |
This looks promising: I’m beeing told that I have 5 clusters (the 4 clusters I asked for in the blob + the outliers) and the silhouette score is closer to 1. Let’s plot #906:
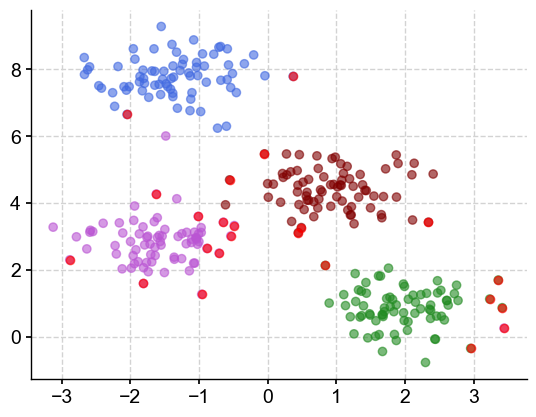
m3 = DBSCAN(eps=0.760526, min_samples=10)
m3.fit(X)
colors = ['royalblue', 'maroon', 'forestgreen', 'mediumorchid', 'deeppink']
vectorizer = np.vectorize(lambda x: colors[x % len(colors)])
plt.scatter(X[:,0], X[:,1], c=vectorizer(m3.labels_), alpha=0.6)
plt.title('eps: 0.76; min_samples: 10')
plt.show()
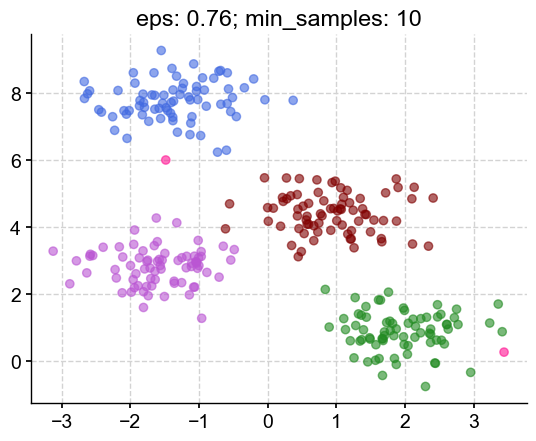
The clusters look like something I would have chosen by eye, with 2 outliers (deep pink) on the outside.
k-means#
Pyleoclim uses the k-means method from scikit-learn. In this case, the most important parameter is the number of clusters. Let’s use this algorithm on the blobs, with a number set to 4:
kmeans = KMeans(n_clusters=4)
m = kmeans.fit(X)
Let’s have a look at our four clusters:
colors=['royalblue', 'maroon', 'forestgreen', 'mediumorchid']
vectorizer = np.vectorize(lambda x: colors[x % len(colors)])
plt.scatter(X[:,0], X[:,1], c=vectorizer(m3.labels_), alpha=0.6)
<matplotlib.collections.PathCollection at 0x33f250d10>
Now that we have our four clusters, how do we determing the outliers?
Outliers are identified based on their distance from the clusters. This can be done in two ways: (1) by using a threshold that corresponds to the Euclidean distance from the centroid and (2) using the Local Outlier Function
Let’s take a look at the result of these two different approaches:
threshold#
threshold = 1
center=m.cluster_centers_[m.labels_]
distance = []
for idx,item in enumerate(center):
distance.append(math.dist(item,X[idx,:]))
idx_out = np.argwhere(np.array(distance)>threshold).reshape(1,-1)[0]
Let’s plot our clusters and outliers in red:
plt.scatter(X[:,0], X[:,1], c=vectorizer(m3.labels_), alpha=0.6)
plt.scatter(X[idx_out,0], X[idx_out,1],c='r', alpha=0.6)
<matplotlib.collections.PathCollection at 0x33f260610>
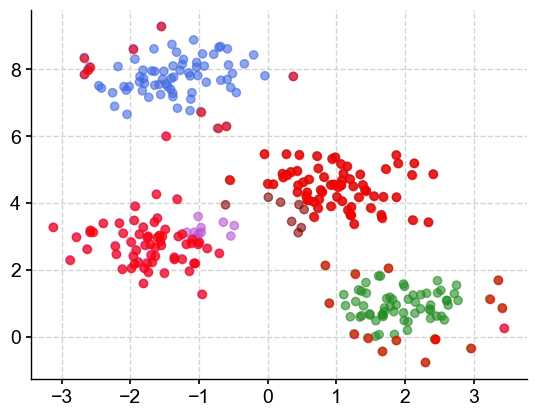
How to choose the right number of clusters? Visual inspection can be useful but a simlar sweep with the sillhouette score as the performance metric can also be used.
LOF#
n_frac = 0.01
contamination = 'auto'
model = LocalOutlierFactor(n_neighbors=int(X.size*n_frac), contamination=contamination)
pred = model.fit_predict(X)
idx_out = np.where(pred==-1)
plt.scatter(X[:,0], X[:,1], c=vectorizer(m3.labels_), alpha=0.6)
plt.scatter(X[idx_out,0], X[idx_out,1],c='r', alpha=0.6)
<matplotlib.collections.PathCollection at 0x33237bbd0>
Outlier detection in Pyleoclim#
Pyleoclim employs the two clustering algorithms details aboved for its outlier detection in timeseries data. The functions take several arguments, the most relevant being listed here:
method – You can select either ‘kmeans’ or ‘DBSCAN’
remove (bool, optional) – If True, removes the outliers.
settings (dict, optional) – Specific arguments for the clustering functions. As detailed above the argument for each of these methods can be quite different. Let’s have a look:
-
nbr_clusters – Number of clusters. Remember that the DSBCAN method finds the number of clusters automatically. This is an optimization parameter, allowing you to override the behavior of looking for the highest silhouette score.
eps – epsilon. The default is None, which allows the algorithm to optimize for the best value of eps, using the silhouette score as the optimization criterion. The sweep is made over eps values determined from nearest neighbors optimization as described above. You can choose to pass your own list for the sweep or choose one value.
min_samples – The number of samples (or total weight) in a neighborhood for a point to be considered as a core point. This includes the point itself. The default is None and optimized using the silhouette score. The sweep occurs from 2 to len(y)/4. You can pass your own list for the sweep.
n_neighbors – Number of neighbors to use by default for kneighbors queries, which can be used to calculate a range of plausible eps values. The default is None, which results in using the scikit-learn default.
-
nbr_clusters – A user number of clusters to considered. The default is None to use the optimization from the Silhouette Score. If the number of clusters can be inferred from a plot, use this parameter to set it.
max_cluster – The maximum number of clusters to consider in the optimization based on the Silhouette Score. The default is 10.
threshold – The algorithm uses the suclidean distance for each point in the cluster to identify the outliers. This parameter sets the threshold on the euclidean distance to define an outlier. The default is 3. By default, the algorithm standardizes the timeseries. Therefore, a value of 3 represents three standard deviation away from the mean.
LOF – By default, detect_outliers_kmeans uses euclidean distance for outlier detection (LOF = False). Set LOF to True to use LocalOutlierFactor for outlier detection. LOF measures the local deviation of the density of a given sample with respect to its neighbors. By comparing the local density of a sample to the local densities of its neighbors, one can identify samples that have a substantially lower density than their neighbors. These are considered outliers.
n_frac – The percentage of the time series length (the length, representing number of points) to be used to set the n_neighbors parameter for the LOF function in scikit-learn. We recommend using at least 50% (n_frac=0.5) of the timeseries. You cannot use 100% (n_frac!=1)
contamination – Same as LOF parameter from scikit-learn. We recommend using the default mode of ‘auto’. See scikit-learn document for details.
-
fig_outliers – Whether to display the timeseries showing the outliers. The default is True. This is a diagnostic plot, showing you the outliers in red.
fig_clusters – Whether to display the clusters. The default is True. This is a diagnostic plot.
keep_log – Keeps a log of the transformation. We recommend setting this value to
Truesince the log will contain several diagnostics that can be very useful.
Let’s give this a try on the MD98-2181 series. As you can imagine, trends can be problematic for clustering so let’s remove it.
ts_p = ts.detrend().standardize()
ts_p.plot()
(<Figure size 1000x400 with 1 Axes>,
<Axes: xlabel='Age [yr BP]', ylabel='SST [deg C]'>)
And let’s apply our outlier algorithm. We will start with kmeans, which is the default in Pyleoclim. Remember that these algorithms are fundamentally different, and may return different clusters.
Outlier dectection using k-means#
Using a threshold value based on the Euclidean Distance from centroid#
For the purpose of demonstration, let’s set the remove parameter to False, keep the log, and use the default removal method, which uses the threshold value.
ts_out = ts_p.outliers(method='kmeans', remove=False, keep_log=True)
No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
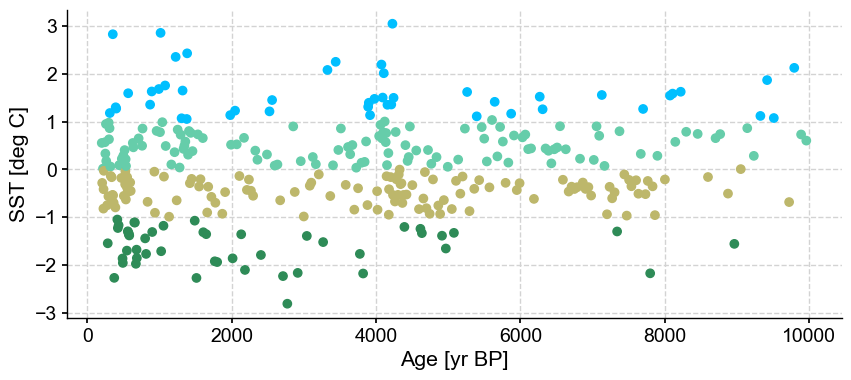
Using the default settings, the number of clusters that maximizes the silhouette score is 4, with no outliers detected. Let’s have a look at the diagnostic kept in the log:
ts_out.log[0]['results']
| number of clusters | silhouette score | outlier indices | clusters | |
|---|---|---|---|---|
| 0 | 2 | 0.557350 | [] | [0, 1, 0, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 0, 0, ... |
| 1 | 3 | 0.530963 | [] | [2, 0, 0, 1, 0, 0, 2, 0, 2, 0, 0, 1, 0, 2, 2, ... |
| 2 | 4 | 0.565988 | [] | [2, 0, 2, 0, 0, 0, 2, 2, 2, 2, 0, 3, 0, 2, 2, ... |
| 3 | 5 | 0.549426 | [] | [2, 0, 2, 0, 0, 2, 2, 2, 4, 2, 0, 3, 0, 4, 2, ... |
| 4 | 6 | 0.539486 | [] | [2, 4, 2, 0, 4, 4, 2, 2, 1, 2, 0, 5, 4, 1, 2, ... |
| 5 | 7 | 0.542952 | [] | [5, 6, 3, 0, 6, 3, 5, 3, 5, 3, 0, 2, 6, 5, 5, ... |
| 6 | 8 | 0.548035 | [] | [1, 6, 7, 0, 6, 6, 1, 7, 1, 7, 0, 5, 0, 1, 1, ... |
| 7 | 9 | 0.538591 | [] | [4, 8, 0, 3, 8, 8, 4, 0, 4, 0, 3, 1, 3, 4, 4, ... |
| 8 | 10 | 0.540070 | [] | [8, 2, 4, 5, 2, 4, 8, 4, 0, 4, 5, 1, 5, 0, 8, ... |
The dataframe contains several pieces of information:
the number of clusters - Remember that this is set as in input to the k-means algorithm and we are sweeping over this range of values.
the silhouette score - Notice that it doesn’t vary much in this case for the various number of clusters.
the indices of the outliers - In this case, there are none.
the cluster assignment for each point - This can be valuable if you are more interested in recovering the clusters than the outliers.
But let’s consider the silhouette score for a minute. There is not much difference between 0.557 (2 clusters) and the optimized 0.565 (4 clusters). However, an argument could be made that there are really two clusters in this series (above and below 0) and the outlying clusters in turquoise and light blue are just representing the noise.
Let’s run this again, but impose 2 clusters:
ts_out = ts_p.outliers(method='kmeans', settings={'nbr_clusters':2}, remove=False, keep_log=True)
No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
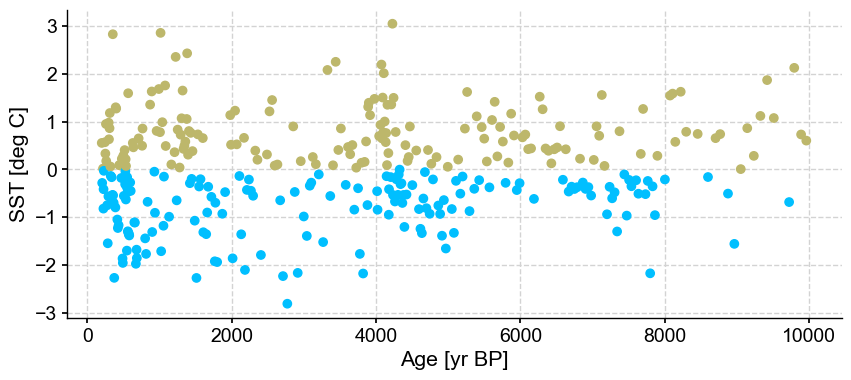
Results are very much identical, with no outliers being detected.
Let’s lower the threshold:
ts_out = ts_p.outliers(method='kmeans', settings={'nbr_clusters':2, 'threshold':2}, remove=False, keep_log=True)
No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
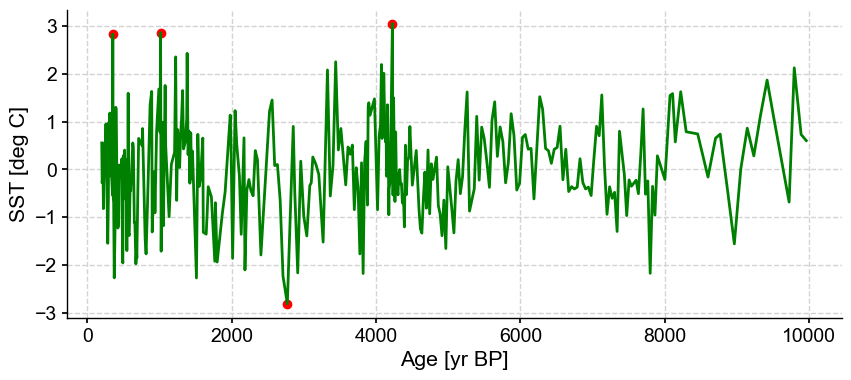
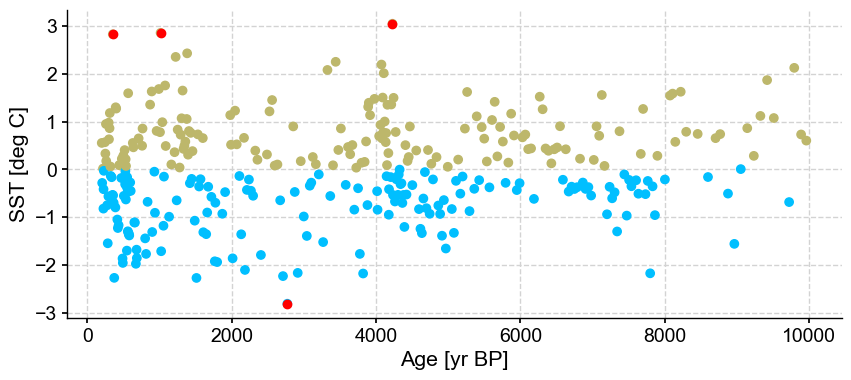
With a lower threshold, the outmost values are being removed, which is not surprising. This is the most sensitive parameter when using the k-mean algorithm and should be chosen with care.
Using LOF#
Next, let’s try out the other outlier removal method: LOF. For the purpose of demonstration, we start with the default settings of n_frac = 0.9, contamination = 'auto', and also set the remove parameter to False and keep the log.
ts_out = ts_p.outliers(method='kmeans', settings={'LOF':True}, remove=False, keep_log=True)
No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
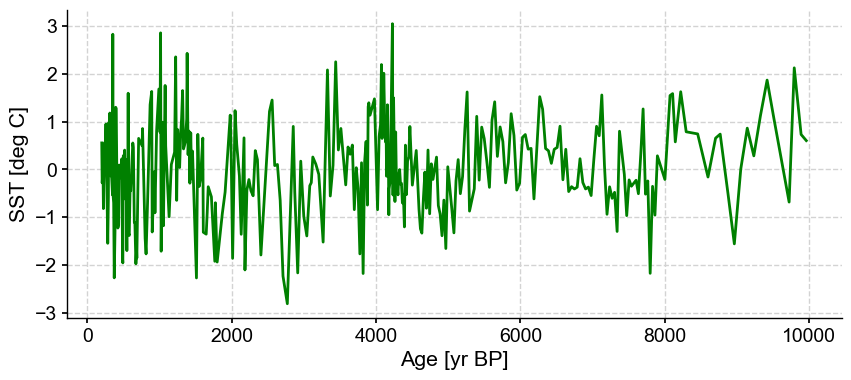
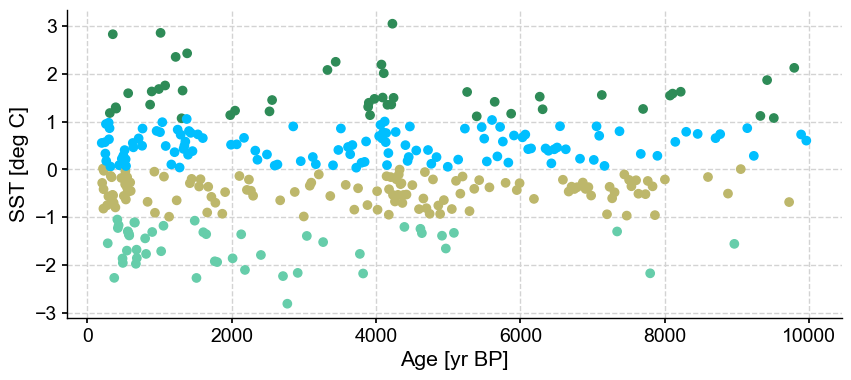
ts_out.log[0]['results']
| number of clusters | silhouette score | outlier indices | clusters | |
|---|---|---|---|---|
| 0 | 2 | 0.557350 | ([],) | [1, 0, 1, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0, 1, 1, ... |
| 1 | 3 | 0.530963 | ([],) | [2, 0, 0, 1, 0, 0, 2, 0, 2, 0, 0, 1, 0, 2, 2, ... |
| 2 | 4 | 0.565762 | ([],) | [1, 0, 0, 0, 0, 0, 1, 1, 1, 1, 0, 2, 0, 1, 1, ... |
| 3 | 5 | 0.511526 | ([],) | [1, 2, 2, 0, 0, 2, 1, 1, 1, 2, 0, 4, 0, 1, 1, ... |
| 4 | 6 | 0.543902 | ([],) | [4, 1, 4, 5, 1, 4, 4, 4, 0, 4, 5, 2, 1, 0, 0, ... |
| 5 | 7 | 0.536126 | ([],) | [4, 5, 0, 5, 5, 0, 4, 0, 4, 0, 5, 2, 5, 4, 4, ... |
| 6 | 8 | 0.548035 | ([],) | [3, 0, 7, 5, 0, 0, 3, 7, 3, 7, 5, 4, 5, 3, 3, ... |
| 7 | 9 | 0.541802 | ([],) | [0, 7, 7, 8, 1, 7, 0, 4, 0, 4, 8, 5, 1, 0, 0, ... |
| 8 | 10 | 0.543038 | ([],) | [3, 7, 0, 4, 7, 0, 3, 0, 9, 0, 4, 1, 4, 9, 3, ... |
As expected, the best silhouette score is obtained with two clusters. Let’s set nbr_cluster to 2 and look at how the two removal method compare.
ts_out = ts_p.outliers(method='kmeans', settings={'nbr_clusters':2, 'LOF':True}, remove=False, keep_log=True)
No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
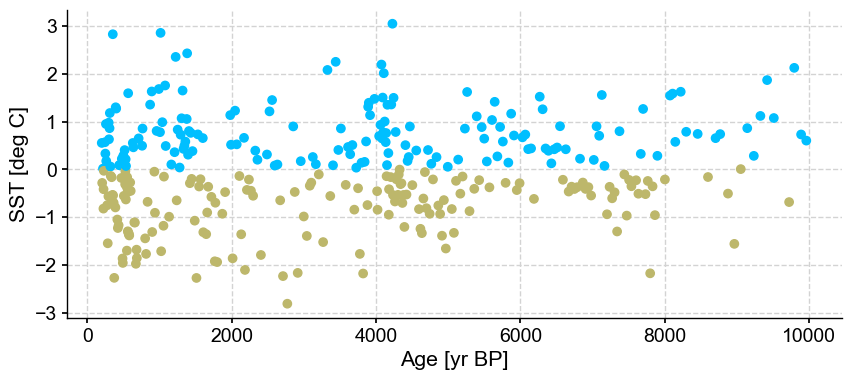
Results are identical with previous one using euclidean distance with no outliers being detected.
LOF has two main parameters to consider: n_frac and contamination. Let’s have a look at these two.
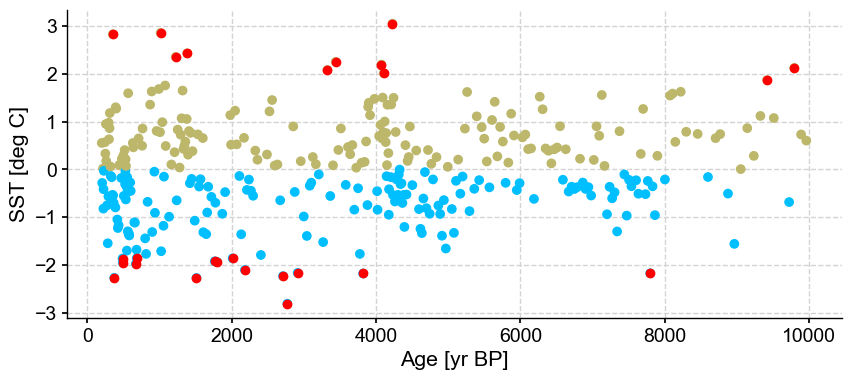
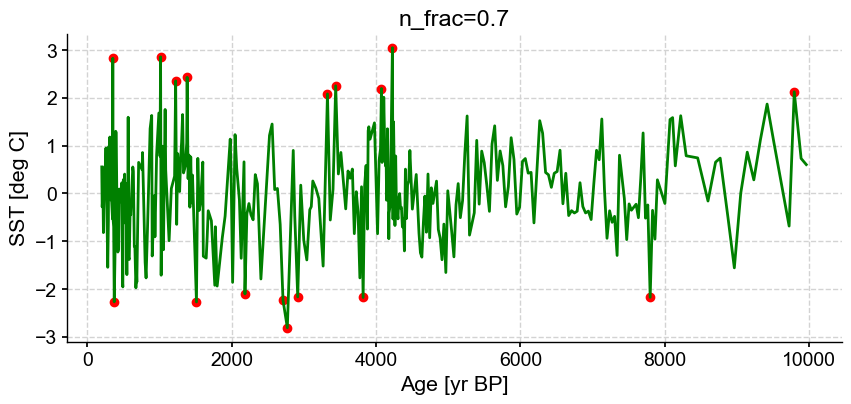
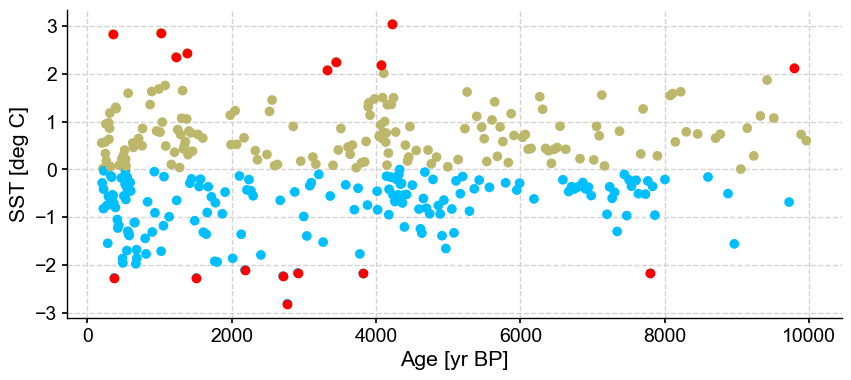
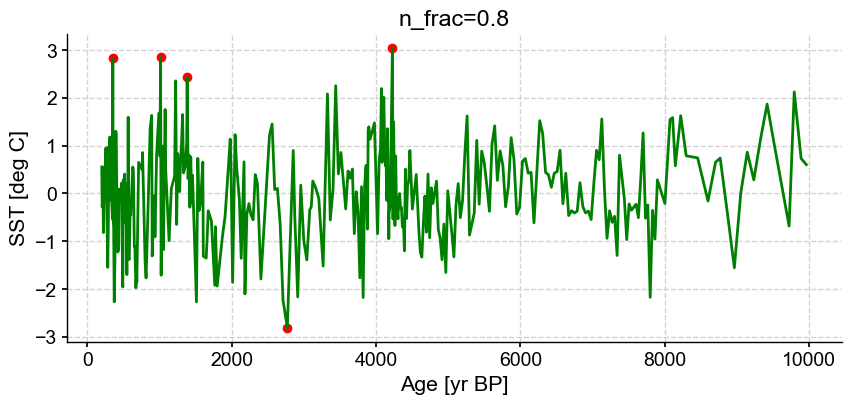
First let’s vary n_frac from 0.5 to 0.9 (default)
ts_out = ts_p.outliers(method='kmeans', settings={'nbr_clusters':2, 'LOF':True, 'n_frac':0.5}, remove=False, keep_log=True, plotoutliers_kwargs={'title':'n_frac=0.5'})
ts_out = ts_p.outliers(method='kmeans', settings={'nbr_clusters':2, 'LOF':True, 'n_frac':0.6}, remove=False, keep_log=True, plotoutliers_kwargs={'title':'n_frac=0.6'})
ts_out = ts_p.outliers(method='kmeans', settings={'nbr_clusters':2, 'LOF':True, 'n_frac':0.7}, remove=False, keep_log=True, plotoutliers_kwargs={'title':'n_frac=0.7'})
ts_out = ts_p.outliers(method='kmeans', settings={'nbr_clusters':2, 'LOF':True, 'n_frac':0.8}, remove=False, keep_log=True, plotoutliers_kwargs={'title':'n_frac=0.8'})
ts_out = ts_p.outliers(method='kmeans', settings={'nbr_clusters':2, 'LOF':True, 'n_frac':0.9}, remove=False, keep_log=True, plotoutliers_kwargs={'title':'n_frac=0.9'})
No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
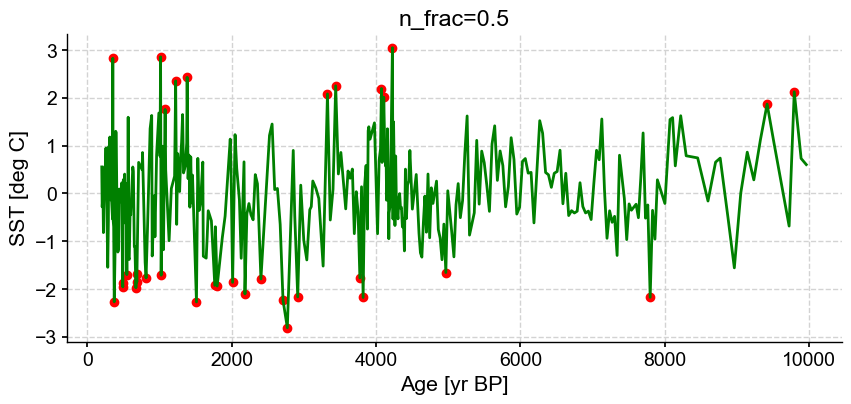
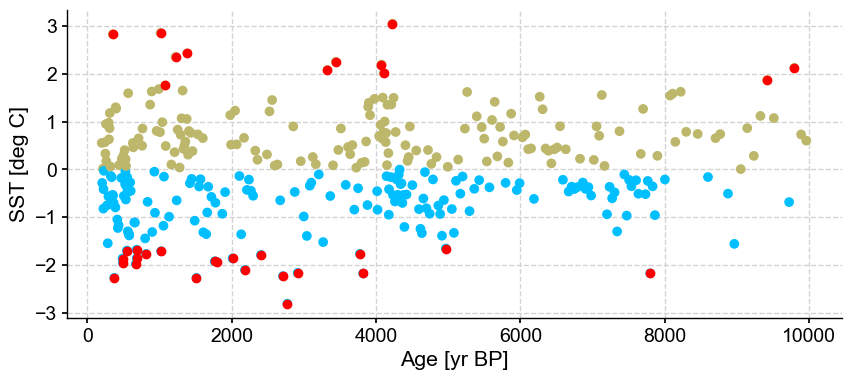
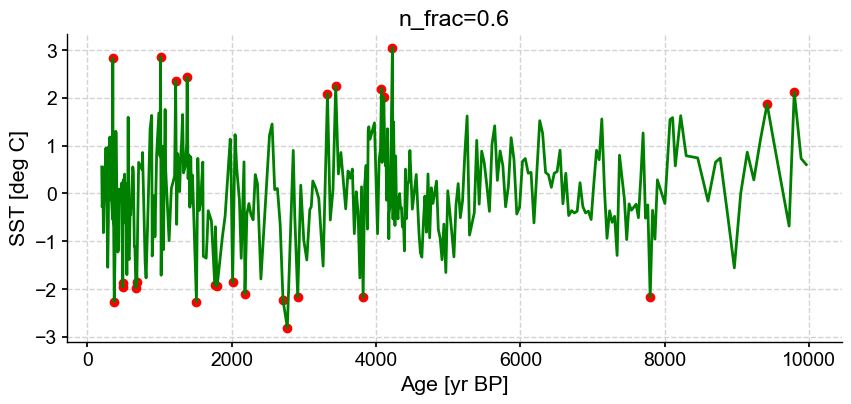
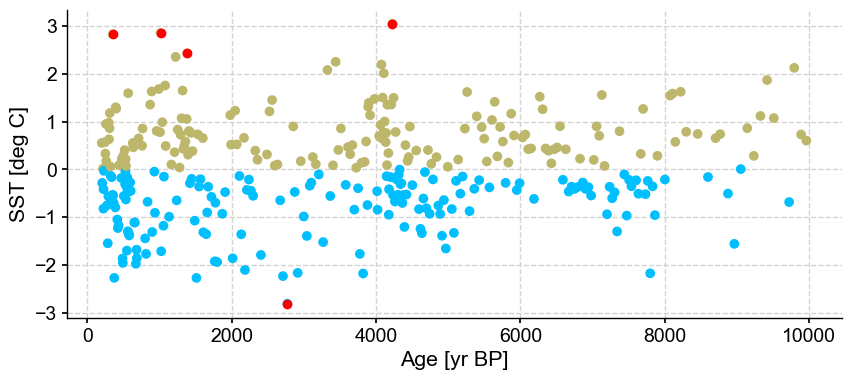
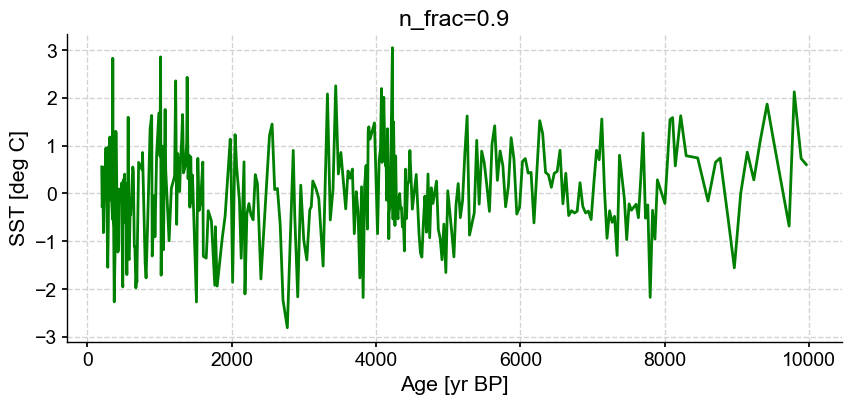
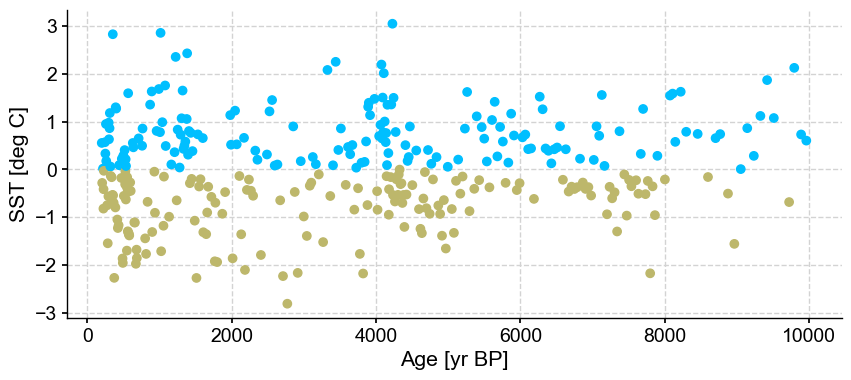
Next let’s vary contamination with 0.02, 0.1, 0.3
ts_out = ts_p.outliers(method='kmeans', settings={'nbr_clusters':2, 'LOF':True, 'contamination':0.02}, remove=False, keep_log=True, plotoutliers_kwargs={'title':'contamination=0.02'})
ts_out = ts_p.outliers(method='kmeans', settings={'nbr_clusters':2, 'LOF':True, 'contamination':0.1}, remove=False, keep_log=True, plotoutliers_kwargs={'title':'contamination=0.1'})
ts_out = ts_p.outliers(method='kmeans', settings={'nbr_clusters':2, 'LOF':True, 'contamination':0.3}, remove=False, keep_log=True, plotoutliers_kwargs={'title':'contamination=0.3'})
No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
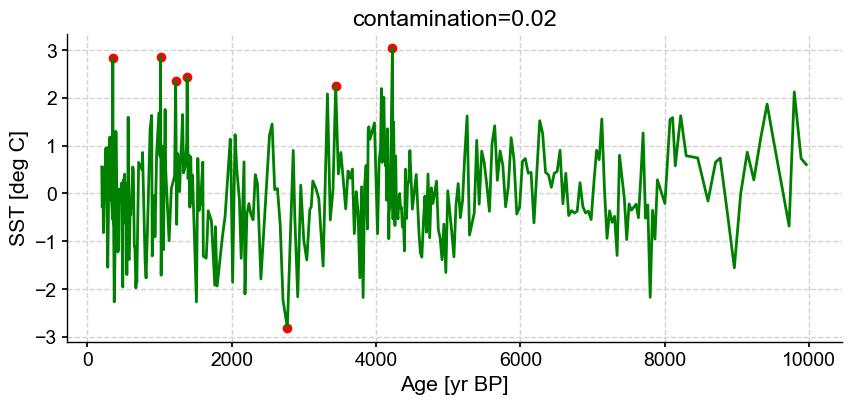
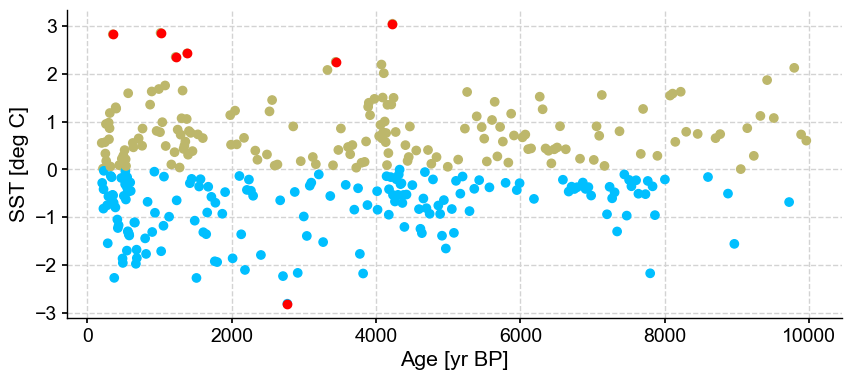
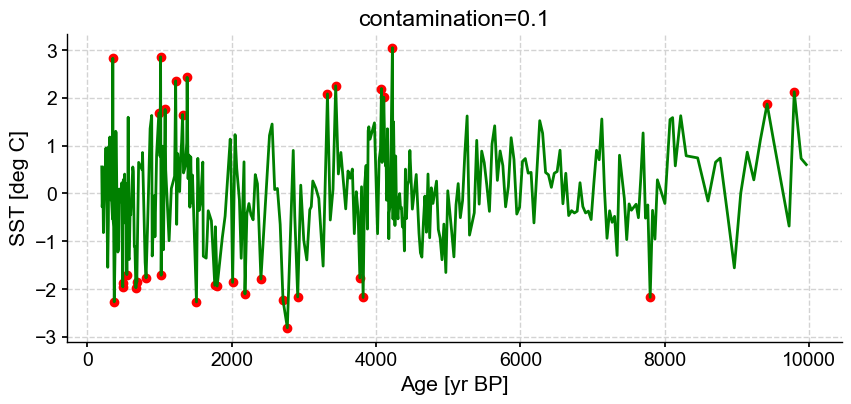
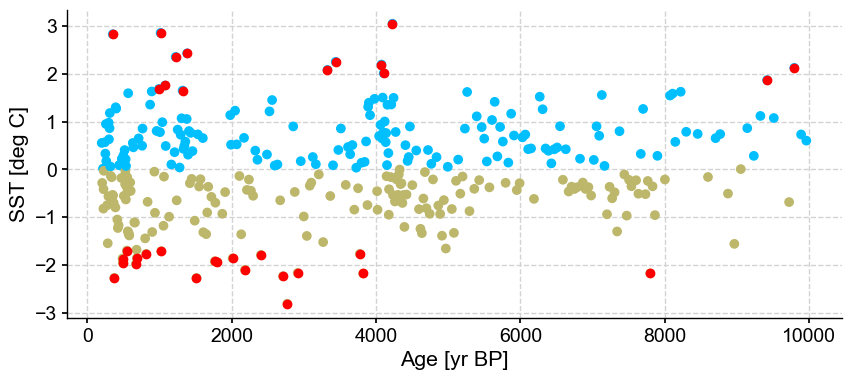
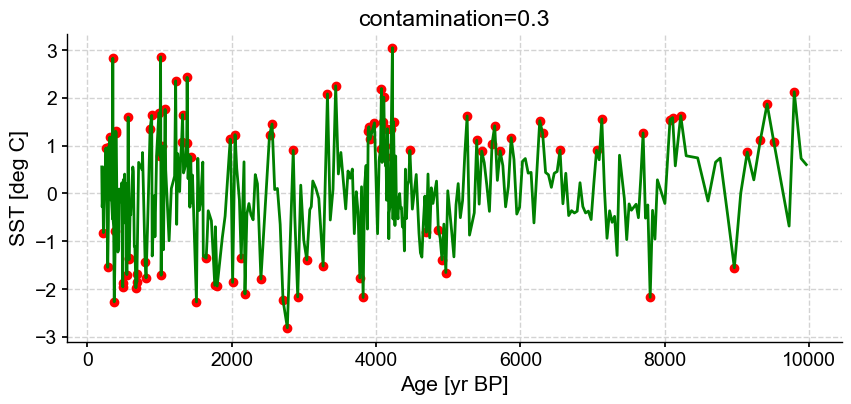
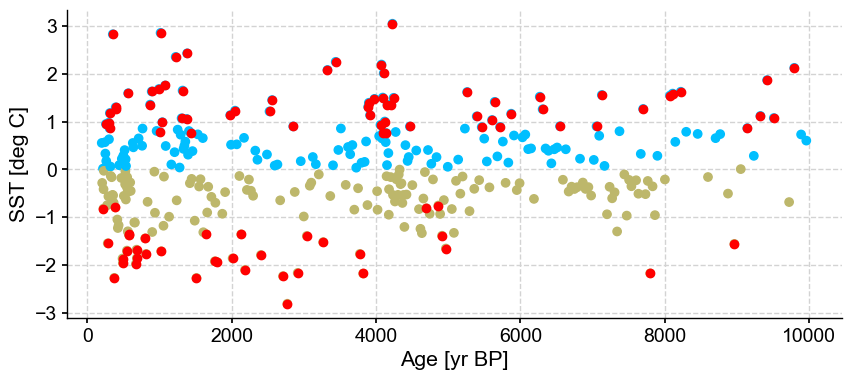
Outlier detection with DBSCAN#
Let’s turn our attention to DBSCAN:
ts_out = ts_p.outliers(method='DBSCAN', remove=False, keep_log=True)
Optimizing for the best number of clusters, this may take a few minutes
No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
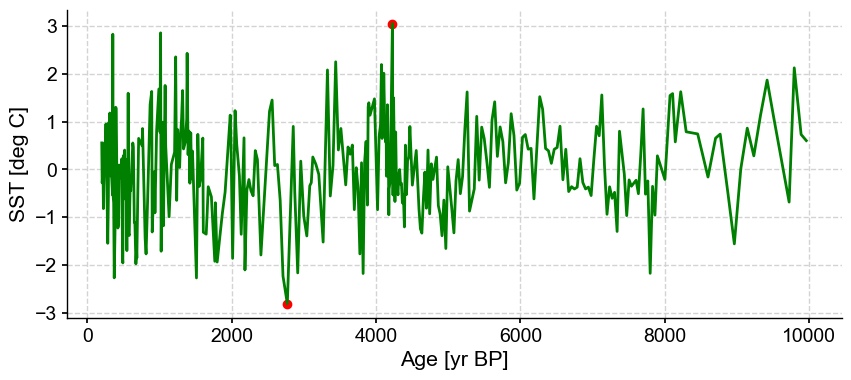
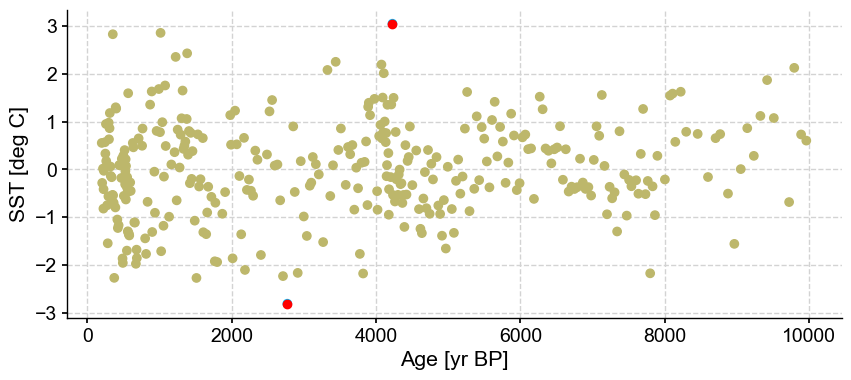
The algorithm optimizes for one cluster and two outliers. Let’s have a look at the log, which will contain the silhouette score:
res = ts_out.log[0]['results']
res
| eps | min_samples | number of clusters | silhouette score | outlier indices | clusters | |
|---|---|---|---|---|---|---|
| 0 | 0.010000 | 2 | 65 | 0.346318 | [2, 8, 11, 13, 14, 16, 21, 25, 26, 28, 29, 30,... | [0, 1, -1, 2, 3, 4, 5, 6, -1, 7, 8, -1, 9, -1,... |
| 1 | 0.010000 | 3 | 44 | 0.185807 | [0, 2, 8, 11, 13, 14, 16, 17, 21, 24, 25, 26, ... | [-1, 0, -1, 1, 2, 15, 3, 32, -1, 4, 5, -1, 6, ... |
| 2 | 0.010000 | 5 | 15 | -0.272447 | [0, 2, 3, 5, 7, 8, 9, 10, 11, 13, 14, 16, 17, ... | [-1, 0, -1, -1, 1, -1, 13, -1, -1, -1, -1, -1,... |
| 3 | 0.010000 | 7 | 3 | -0.280342 | [0, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14... | [-1, 0, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1... |
| 4 | 0.010000 | 8 | 2 | -0.306025 | [0, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14... | [-1, 0, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1... |
| ... | ... | ... | ... | ... | ... | ... |
| 2495 | 5.665417 | 77 | 0 | NaN | [] | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... |
| 2496 | 5.665417 | 79 | 0 | NaN | [] | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... |
| 2497 | 5.665417 | 80 | 0 | NaN | [] | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... |
| 2498 | 5.665417 | 82 | 0 | NaN | [] | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... |
| 2499 | 5.665417 | 84 | 0 | NaN | [] | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... |
2500 rows × 6 columns
The log contains the values of eps and min_samples that were tried, the number of resulting clusters, the silhouette score, the indices of the outliers and the cluster assignment.
Let’s look for the maximum value of the silhouette score:
res.loc[res['silhouette score']==np.max(res['silhouette score'])]
| eps | min_samples | number of clusters | silhouette score | outlier indices | clusters | |
|---|---|---|---|---|---|---|
| 202 | 0.471667 | 5 | 1 | 0.616233 | [145, 201] | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... |
| 203 | 0.471667 | 7 | 1 | 0.616233 | [145, 201] | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... |
| 204 | 0.471667 | 8 | 1 | 0.616233 | [145, 201] | [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ... |
Several combinations result in a similar silhouette score (by default, Pyleoclim will work with the first one), with a eps value of 0.47. Let’s make sure that this value is not the maximum that was tried (if so, I would recommend passing your own list of eps value direclty):
res['eps'].max()
5.6654168267442815
res['eps'].min()
0.01
This seems reasonable (and not an artifact of the limits on the parameter sweeps). Note that DBSCAN and k-means both identified a common set of outliers that could be candidates for removal. Generally, if the answers are sensitive to the method and parameters, then it is a good indication that the method is too sensitive and conclusions (i.e., whether the data points are outliers) are not robust. If this is the case, proceed carefully with remove.
%watermark -n -u -v -iv -w
Last updated: Mon Mar 04 2024
Python implementation: CPython
Python version : 3.11.7
IPython version : 8.20.0
pyleoclim: 0.13.1b0
Watermark: 2.4.3