
Loading data into Pyleoclim#
by Jordan Landers, Deborah Khider, Julien Emile-Geay.
Preamble#
Contrary to common beliefs, Pyleoclim is not specific to the LiPD. The object at the heart of the package is the
Series object, which describes the fundamentals of a time series. To create a
Pyleoclim Series, we first need to load the data set, and then specify values for its various properties:
time: Time values for the time seriesvalue: Paleo values for the time seriestime_name(optional): Name of the time vector, (e.g., ‘Time’, ‘Age’). This is used to label the x-axis on plotstime_unit(optional): The units of the time axis (e.g., ‘years’)value_name(optional): The name of the paleo variable (e.g., ‘Temperature’)value_unit(optional): The units of the paleo variable (e.g., ‘deg C’)label(optional): Name of the time series (e.g., ‘Nino 3.4’)log(dict) – Dictionary of tuples documentating the various transformations applied to the objectkeep_log(bool) – Whether to keep a log of applied transformations. False by defaultimportedFrom(string) – source of the dataset. If it came from a LiPD file, this could be the datasetID propertyarchiveType(string) – climate archivedropna(bool) – Whether to drop NaNs from the series to prevent downstream functions from choking on them defaults to Truesort_ts(str) – Direction of sorting over the time coordinate; ‘ascending’ or ‘descending’ Defaults to ‘ascending’verbose(bool) – If True, will print warning messages if there is anyclean_ts(optional): set to True to remove the NaNs and make time axis strictly prograde with duplicated timestamps reduced by averaging the values Default is None.
Data may be stored in different file types, which can be ingested in different ways.
Goals:#
Create Pyleoclim Series objects from datasets stored as CSV, NetCDF, LiPD, and NOAA txt files.
Reading Time: 5 minutes
Keywords#
CSV; NetCDF; LiPD, Series; EnsembleSeries; MultipleSeries
Pre-requisites#
None. This tutorial assumes basic knowledge of Python. If you are not familiar with this coding language, check out this tutorial: http://linked.earth/ec_workshops_py/.
Relevant Packages#
Pandas; Xarray; pylipd; pangaeapy
Data Description#
McCabe-Glynn, S., Johnson, K., Strong, C. et al. Variable North Pacific influence on drought in southwestern North America since AD 854. Nature Geosci 6, 617–621 (2013). doi:10.1038/ngeo1862
Euro2k database: PAGES2k Consortium., Emile-Geay, J., McKay, N. et al. A global multiproxy database for temperature reconstructions of the Common Era. Sci Data 4, 170088 (2017). doi:10.1038/sdata.2017.88
Lisiecki, L. E., and Raymo, M. E. (2005), A Pliocene-Pleistocene stack of 57 globally distributed benthic δ18O records, Paleoceanography, 20, PA1003, doi:10.1029/2004PA001071.
Demonstration#
First we import our favorite packages:
%load_ext watermark
import pyleoclim as pyleo
from pylipd.lipd import LiPD
import xarray as xr
import pandas as pd
from pangaeapy.pandataset import PanDataSet
Pre-loaded datasets#
First, note that pyleoclim ships with a few pre-defined datasets:
pyleo.utils.available_dataset_names()
['SOI',
'NINO3',
'HadCRUT5',
'AIR',
'LR04',
'AACO2',
'EDC-dD',
'GISP2',
'cenogrid_d18O',
'cenogrid_d13C']
To load one such dataset, simply type its name within pyleo.utils.load_dataset(), like so:
ts = pyleo.utils.load_dataset('cenogrid_d18O')
ts.plot(invert_yaxis=True)
(<Figure size 1000x400 with 1 Axes>,
<Axes: xlabel='Age [My BP]', ylabel='$\\delta^{18} \\mathrm{O}$ [‰ VPDB]'>)
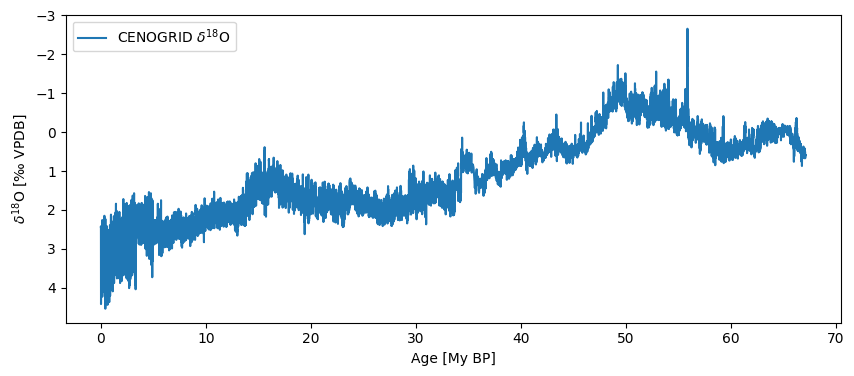
Of course, there is a whole world out there full of wondrous data. How do you pull them into your Python workspace and get them to play nice with Pyleoclim? A few options below.
LiPD#
Linked Paleo Data format (LiPD) files contain time series information in addition to supporting metadata (e.g., root metadata, location).
Data stored in this format can be loaded into Python through a package called pylipd. Tutorials for this toolbox are available here.
Loading a single LiPD file#
data_path = '../data/Crystal.McCabe-Glynn.2013.lpd'
D = LiPD()
D.load(data_path)
Loading 1 LiPD files
100%|██████████| 1/1 [00:00<00:00, 3.27it/s]
Loaded..
You can extract each available variable and load them into a Pandas DataFrame. Each row will represent one variable:
d, df = D.get_timeseries(D.get_all_dataset_names(), to_dataframe=True)
df.head()
Extracting timeseries from dataset: Crystal.McCabe-Glynn.2013 ...
| mode | time_id | archiveType | investigator | createdBy | pub1_author | pub1_journal | pub1_year | pub1_doi | pub1_volume | ... | paleoData_resolution_hasMeanValue | paleoData_resolution_hasMaxValue | paleoData_resolution_hasMinValue | paleoData_resolution_hasMedianValue | paleoData_hasMinValue | paleoData_proxyObservationType | paleoData_variableType | paleoData_units | paleoData_values | paleoData_inferredVariableType | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | paleoData | age | Speleothem | [{'name': 'S. McCabe-Glynn'}, {'name': 'R.L. E... | excel | Hai Cheng and R. Lawrence Edwards Ashish Sinha... | Nature Geoscience | 2013 | 10.1038/ngeo1862 | 6.0 | ... | -1.097626 | -0.7 | 2.5 | -1.1 | 10.43 | d18O | measured | permil | [-8.01, -8.23, -8.61, -8.54, -8.6, -9.08, -8.9... | NaN |
| 1 | paleoData | age | Speleothem | [{'name': 'S. McCabe-Glynn'}, {'name': 'R.L. E... | excel | Hai Cheng and R. Lawrence Edwards Ashish Sinha... | Nature Geoscience | 2013 | 10.1038/ngeo1862 | 6.0 | ... | NaN | NaN | NaN | NaN | 851.90 | NaN | inferred | yr AD | [2007.7, 2007.0, 2006.3, 2005.6, 2004.9, 2004.... | Age |
| 2 | paleoData | age | Speleothem | [{'name': 'S. McCabe-Glynn'}, {'name': 'R.L. E... | excel | Hai Cheng and R. Lawrence Edwards Ashish Sinha... | Nature Geoscience | 2013 | 10.1038/ngeo1862 | 6.0 | ... | -1.097626 | -0.7 | 2.5 | -1.1 | 0.05 | depth | measured | mm | [0.05, 0.1, 0.15, 0.2, 0.25, 0.3, 0.35, 0.4, 0... | NaN |
3 rows × 52 columns
The available properties are stored in the columns of the DataFrame:
df.columns
Index(['mode', 'time_id', 'archiveType', 'investigator', 'createdBy',
'pub1_author', 'pub1_journal', 'pub1_year', 'pub1_doi', 'pub1_volume',
'pub1_pages', 'pub1_dataUrl', 'pub1_title', 'pub1_abstract',
'funding1_grant', 'funding1_agency', 'funding2_grant',
'funding2_agency', 'funding3_grant', 'funding3_agency', 'lipdVersion',
'dataSetName', 'geo_meanLon', 'geo_meanLat', 'geo_meanElev', 'geo_type',
'hasUrl', 'tableType', 'paleoData_tableName', 'paleoData_filename',
'paleoData_missingValue', 'age', 'ageUnits', 'depth', 'depthUnits',
'paleoData_hasMeanValue', 'paleoData_hasMedianValue', 'paleoData_TSid',
'paleoData_hasMaxValue', 'paleoData_takenAtDepth',
'paleoData_variableName', 'paleoData_number',
'paleoData_resolution_hasMeanValue', 'paleoData_resolution_hasMaxValue',
'paleoData_resolution_hasMinValue',
'paleoData_resolution_hasMedianValue', 'paleoData_hasMinValue',
'paleoData_proxyObservationType', 'paleoData_variableType',
'paleoData_units', 'paleoData_values',
'paleoData_inferredVariableType'],
dtype='str')
Let’s see which variables are available:
df['paleoData_variableName'].unique()
<StringArray>
['d18O', 'age', 'depth']
Length: 3, dtype: str
df_filter=df[df['paleoData_variableName']=='d18O']
df_filter
| mode | time_id | archiveType | investigator | createdBy | pub1_author | pub1_journal | pub1_year | pub1_doi | pub1_volume | ... | paleoData_resolution_hasMeanValue | paleoData_resolution_hasMaxValue | paleoData_resolution_hasMinValue | paleoData_resolution_hasMedianValue | paleoData_hasMinValue | paleoData_proxyObservationType | paleoData_variableType | paleoData_units | paleoData_values | paleoData_inferredVariableType | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | paleoData | age | Speleothem | [{'name': 'S. McCabe-Glynn'}, {'name': 'R.L. E... | excel | Hai Cheng and R. Lawrence Edwards Ashish Sinha... | Nature Geoscience | 2013 | 10.1038/ngeo1862 | 6.0 | ... | -1.097626 | -0.7 | 2.5 | -1.1 | 10.43 | d18O | measured | permil | [-8.01, -8.23, -8.61, -8.54, -8.6, -9.08, -8.9... | NaN |
1 rows × 52 columns
Let’s create a Series object from the information in the file:
ts = pyleo.Series(time=df_filter['age'].iloc[0], value=df_filter['paleoData_values'].iloc[0],
time_name = 'Age', time_unit = df_filter['ageUnits'].iloc[0],
value_name = df_filter['paleoData_variableName'].iloc[0],
value_unit = df_filter['paleoData_units'].iloc[0],
label = df_filter['dataSetName'].iloc[0],
archiveType = df_filter['archiveType'].iloc[0],
auto_time_params=False, verbose=False)
And plot the timeseries:
ts.plot()
(<Figure size 1000x400 with 1 Axes>,
<Axes: xlabel='Age [yr AD]', ylabel='d18O [permil]'>)
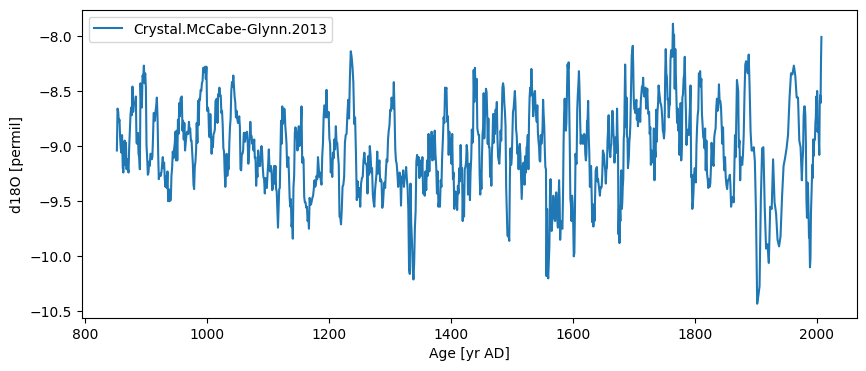
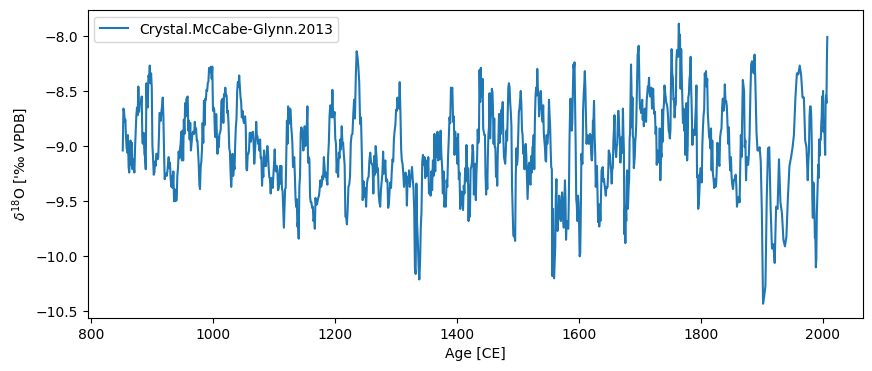
By default, the plot will use the name/units passed to Series to make the plots. You can change these labels directly on the graph or update the information in the Series object at any time:
ts.time_unit = 'CE'
ts.value_name = '$\delta^{18}$O'
ts.value_unit = "'‰ VPDB"
ts.plot()
(<Figure size 1000x400 with 1 Axes>,
<Axes: xlabel='Age [CE]', ylabel="$\\delta^{18}$O ['‰ VPDB]">)
Loading multiple LiPD files#
data_path = '../data/Euro2k/'
D_euro = LiPD()
D_euro.load_from_dir(data_path)
Loading 31 LiPD files
100%|██████████| 31/31 [00:00<00:00, 55.33it/s]
Loaded..
Let’s use the same .get_timeseries function to load all the variables in a DataFrame:
d_euro, df_euro = D_euro.get_timeseries(D_euro.get_all_dataset_names(),to_dataframe=True)
Extracting timeseries from dataset: Ocn-RedSea.Felis.2000 ...
Extracting timeseries from dataset: Arc-Forfjorddalen.McCarroll.2013 ...
Extracting timeseries from dataset: Eur-Tallinn.Tarand.2001 ...
Extracting timeseries from dataset: Eur-CentralEurope.Dobrovoln_.2009 ...
Extracting timeseries from dataset: Eur-EuropeanAlps.B_ntgen.2011 ...
Extracting timeseries from dataset: Eur-CentralandEasternPyrenees.Pla.2004 ...
Extracting timeseries from dataset: Arc-Tjeggelvas.Bjorklund.2012 ...
Extracting timeseries from dataset: Arc-Indigirka.Hughes.1999 ...
Extracting timeseries from dataset: Eur-SpannagelCave.Mangini.2005 ...
Extracting timeseries from dataset: Ocn-AqabaJordanAQ19.Heiss.1999 ...
Extracting timeseries from dataset: Arc-Jamtland.Wilson.2016 ...
Extracting timeseries from dataset: Eur-RAPiD-17-5P.Moffa-Sanchez.2014 ...
Extracting timeseries from dataset: Eur-LakeSilvaplana.Trachsel.2010 ...
Extracting timeseries from dataset: Eur-NorthernSpain.Mart_n-Chivelet.2011 ...
Extracting timeseries from dataset: Eur-MaritimeFrenchAlps.B_ntgen.2012 ...
Extracting timeseries from dataset: Ocn-AqabaJordanAQ18.Heiss.1999 ...
Extracting timeseries from dataset: Arc-Tornetrask.Melvin.2012 ...
Extracting timeseries from dataset: Eur-EasternCarpathianMountains.Popa.2008 ...
Extracting timeseries from dataset: Arc-PolarUrals.Wilson.2015 ...
Extracting timeseries from dataset: Eur-LakeSilvaplana.Larocque-Tobler.2010 ...
Extracting timeseries from dataset: Eur-CoastofPortugal.Abrantes.2011 ...
Extracting timeseries from dataset: Eur-TatraMountains.B_ntgen.2013 ...
Extracting timeseries from dataset: Eur-SpanishPyrenees.Dorado-Linan.2012 ...
Extracting timeseries from dataset: Eur-FinnishLakelands.Helama.2014 ...
Extracting timeseries from dataset: Eur-Seebergsee.Larocque-Tobler.2012 ...
Extracting timeseries from dataset: Eur-NorthernScandinavia.Esper.2012 ...
Extracting timeseries from dataset: Arc-GulfofAlaska.Wilson.2014 ...
Extracting timeseries from dataset: Arc-Kittelfjall.Bjorklund.2012 ...
Extracting timeseries from dataset: Eur-L_tschental.B_ntgen.2006 ...
Extracting timeseries from dataset: Eur-Stockholm.Leijonhufvud.2009 ...
Extracting timeseries from dataset: Arc-AkademiiNaukIceCap.Opel.2013 ...
Let’s have a look at the available variable names:
df_euro['paleoData_variableName'].unique()
<StringArray>
[ 'year', 'd18O', 'MXD', 'temperature', 'JulianDay',
'ringWidth', 'sampleID', 'age', 'uncertainty', 'density',
'd13C', 'count', 'thickness', 'sodium']
Length: 14, dtype: str
Let’s filter the temperature records:
df_euro_filt = df_euro[df_euro['paleoData_variableName']=='temperature']
df_euro_filt.shape
(12, 113)
Which leaves us with 12 timeseries. Let’s iterate over the DataFrame and create a Series for each of these:
ts_list = []
for _,row in df_euro_filt.iterrows():
ts_list.append(pyleo.GeoSeries(time=row['year'],value=row['paleoData_values'],
time_name='Year',value_name=row['paleoData_variableName'],
time_unit=row['yearUnits'], value_unit=row['paleoData_units'],
lat = row['geo_meanLat'], lon = row['geo_meanLon'],
archiveType = row['archiveType'],
label=row['dataSetName']+'_'+row['paleoData_proxy'],
auto_time_params=False, verbose=False))
Here I chose to keep these series into a list, which makes it easy to create a MultipleSeries object. However, you could choose to keep them in a dictionary, using the datasetname/proxy as a key.
ms = pyleo.MultipleSeries(ts_list)
And plot them:
ms.stackplot(figsize = [10,20])
(<Figure size 1000x2000 with 13 Axes>,
{0: <Axes: ylabel='temperature [degC]'>,
1: <Axes: ylabel='temperature [degC]'>,
2: <Axes: ylabel='temperature [degC]'>,
3: <Axes: ylabel='temperature [degC]'>,
4: <Axes: ylabel='temperature [degC]'>,
5: <Axes: ylabel='temperature [degC]'>,
6: <Axes: ylabel='temperature [degC]'>,
7: <Axes: ylabel='temperature [degC]'>,
8: <Axes: ylabel='temperature [degC]'>,
9: <Axes: ylabel='temperature [degC]'>,
10: <Axes: ylabel='temperature [degC]'>,
11: <Axes: ylabel='temperature [degC]'>,
'x_axis': <Axes: xlabel='Time [yr AD]'>})
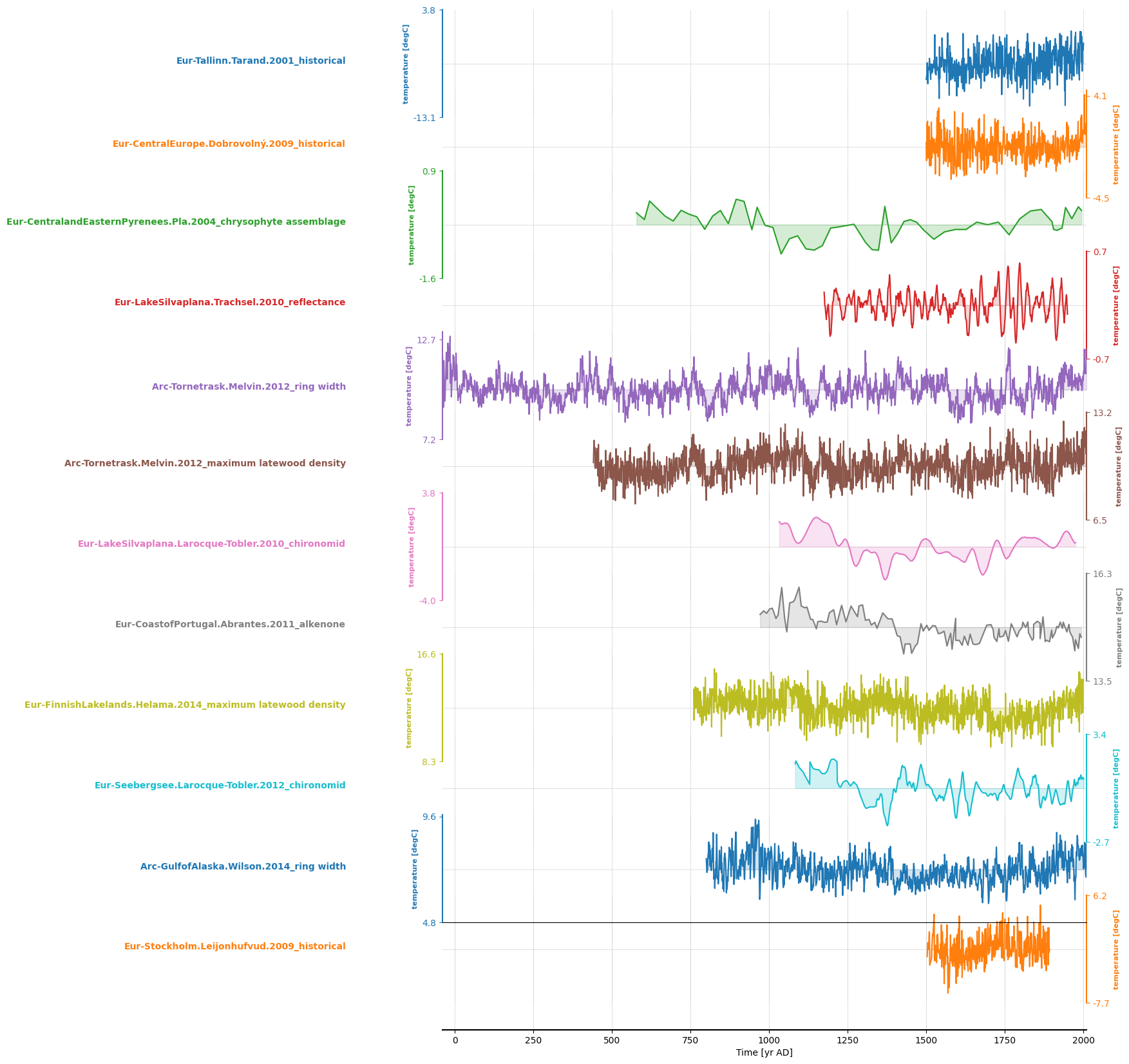
NetCDF#
In order to load data from a NetCDF file, we will use Xarray.
file_path = '../data/p2k_ngeo19_recons.nc'
p2k_nc = xr.open_dataset(file_path)
The coordinates of this data set are year and ens, and the temperature anamoly is contained in the variable
LMRv2.1. Below we extract the timeseries for the ensemble runs:
variable_name = 'LMRv2.1'
ens_runs = p2k_nc.groupby('ens')
To create the pyleo.Series, we pass the time coordinate of the dataset, p2k_nc.year, as time, and one of the ensemble runs as value. It is optional to specify time_name and time_unit, and
value_name and value_unit, but doing so ensures that plot axes are properly labeled.
ens_run1 = ens_runs[1].data_vars[variable_name]
p2k_ps = pyleo.Series(time=p2k_nc.year, value=ens_run1,
time_name='Time', time_unit='year', label = 'LMRv2.1 member #1',
value_name='GMST', value_unit='$^{\circ}$C', verbose=False)
fig, ax = p2k_ps.plot()
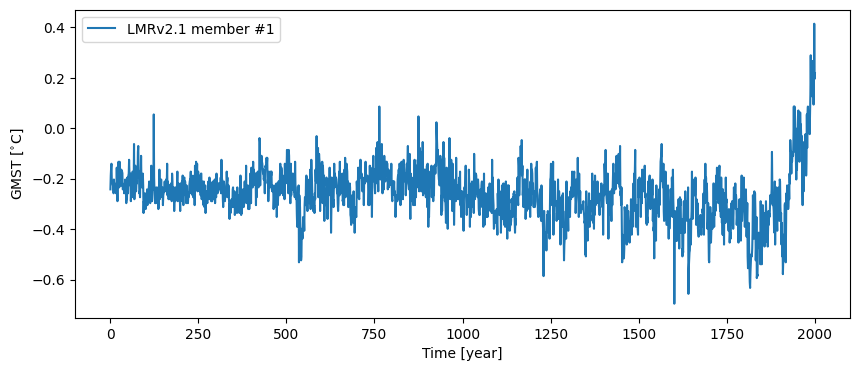
However, given this is an ensemble, capturing this data in a pyleo.EnsembleSeries will open up opportunities for
specific analysis and visualization. In the cell below, we generate a list of pyleo.Series (one for each trace) for
the full set of ensemble runs in much the same way as above.
%%time
ts_list = []
for im in range(len(p2k_nc.ens)):
ens_run = ens_runs[im+1].data_vars[variable_name]
ts_list.append(pyleo.Series(time=p2k_nc.year, value=ens_run,
time_name='Time', time_unit='year', verbose=False,
value_name='GMST', value_unit='$^{\circ}$C'))
CPU times: user 347 ms, sys: 5.91 ms, total: 353 ms
Wall time: 351 ms
Then we simply pass ts_list to pyleo.EnsembleSeries…
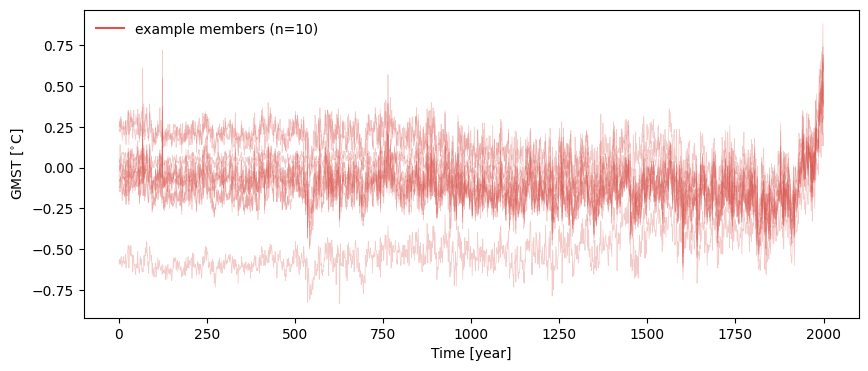
ts_ens = pyleo.EnsembleSeries(ts_list)
For more detail on visualizing pyleo.EnsembleSeries, check out the tutorial on Basic operations with
MultipleSeries and EnsembleSeries, but we can use plot_traces() to quickly check to make sure the data seems
properly organized (by default, plot_traces() plots 10 randomly selected traces).
fig, ax = ts_ens.plot_traces()
CSV#
CSV files have a table structure, so we will use Pandas and the read the data into a pandas DataFrame.
LR04 = pd.read_csv('../data/LR04.csv', header=4)
LR04.head()
| Time (ka) | Benthic d18O (per mil) | Standard error (per mil) | |
|---|---|---|---|
| 0 | 0.0 | 3.23 | 0.03 |
| 1 | 1.0 | 3.23 | 0.04 |
| 2 | 2.0 | 3.18 | 0.03 |
| 3 | 3.0 | 3.29 | 0.03 |
| 4 | 4.0 | 3.30 | 0.03 |
LR04.columns
Index(['Time (ka)', 'Benthic d18O (per mil) ', 'Standard error (per mil)'], dtype='str')
To create a pyleo.Series, we pass the Time (ka) column as time and the Benthic d18O (per mil) column as value. Note the extra space at the end of that column name! We have to work with what the interwebs give us.
LR04_ps = pyleo.Series(time=LR04['Time (ka)'], value=LR04['Benthic d18O (per mil) '],
time_name='Age', time_unit='ka', verbose=False,
value_name='$\delta^{18}$O', value_unit=u'‰')
fig, ax = LR04_ps.plot(invert_yaxis=True)
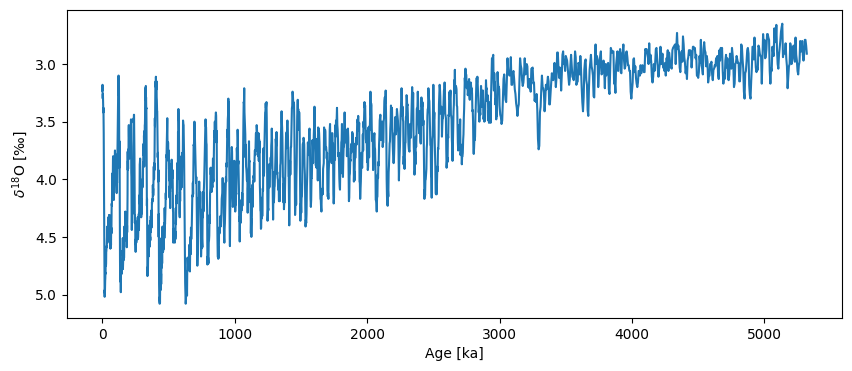
Note that you would get the exact same result with LR04_ps = pyleo.utils.load_dataset('LR04'). Generally speaking, it is very easy to go between Pyleoclim and CSV files, but the file needs to have a certain structure to be properly read with the function from_csv(). For an example, see this tutorial. If it doesn’t follow that structure, proceed as outlined above.
NOAA txt files#
As you may now, the World Data Service for paleoclimatology, operated by NCEI/NOAA of the US Department of Commerce, hosts thousands of data files in various formats. A common one is a templated text file, containing rich data and metadata. One can treat the file as a raw text file, ignoring the header and loading the data directly into a Pandas DataFrame.
Automatic Dataset loading with PyleoTUPS#
NOAA paleoclimate datasets are typically hosted as structured text files containing both metadata and tabular data.
With PyleoTUPS, users do not need to manually download or parse these text files.
The NOAADataset class handles:
Retrieving the file from NOAA/NCEI
Parsing the metadata header
Cleaning and structuring the data
Returning a pandas DataFrame
Initialize a NOAADataset object and use the get_data method to load the dataset. The get_data method returns a list of dataframes, so we select the first dataframe using [0].
# path = 'ftp://ftp.ncdc.noaa.gov/pub/data/paleo/icecore/antarctica/antarctica2015co2composite.txt'
# co2df = pd.read_csv(path, skiprows=137, sep='\t')
# co2df.head()
from pyleotups import NOAADataset
ds = NOAADataset()
co2dfs = ds.get_data(file_urls = "https://www.ncei.noaa.gov/pub/data/paleo/icecore/antarctica/antarctica2015co2composite.txt")
co2df = co2dfs[0]
co2df.head()
| age_gas_calBP | co2_ppm | co2_1s_ppm | |
|---|---|---|---|
| 0 | -51.03 | 368.02 | 0.06 |
| 1 | -48.00 | 361.78 | 0.37 |
| 2 | -46.28 | 359.65 | 0.10 |
| 3 | -44.41 | 357.11 | 0.16 |
| 4 | -43.08 | 353.95 | 0.04 |
### The output obtained from pyleotups tool might have the data types of the columns as object. We can use the following code to be sure we dont mix data types.
co2df = co2df.apply(pd.to_numeric, errors="coerce")
Finally, we pull the relevant columns of this datframe into a Series object, convert the years to kyr for ease of use, and put in the relevant metadata so that we can get a well-labeled, publication-quality plot right off the bat:
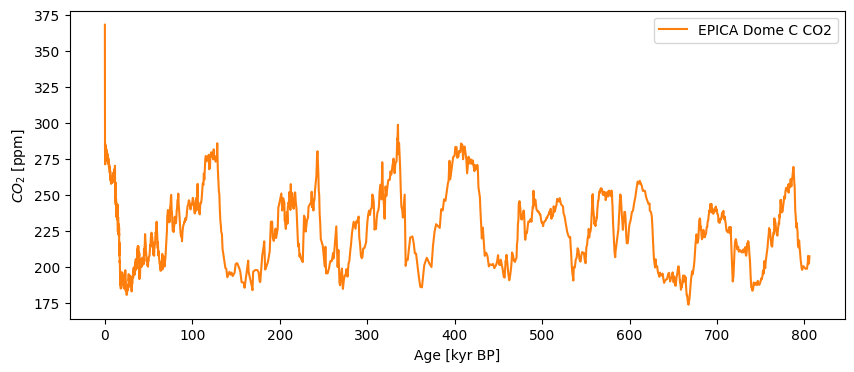
co2ts = pyleo.Series(time=co2df['age_gas_calBP']/1000,value= co2df['co2_ppm'],
time_name='Age',time_unit='kyr BP',value_name = r'$CO_2$',
value_unit='ppm',label='EPICA Dome C CO2', verbose=False)
co2ts.plot(color='C1')
(<Figure size 1000x400 with 1 Axes>,
<Axes: xlabel='Age [kyr BP]', ylabel='$CO_2$ [ppm]'>)
Loading from PANGAEA#
Another major repository for paleoclimate data is PANGAEA. Here we load the dataset of Skinner et al. (2007), using the very helpful pangaeapy package:
PyleoTUPS also provides a convenient way to load data from Pangaea. With pyleotups’s PangaeaDataset, you can also view other metadata related to studies. You can directly pass the url or the doi of the dataset to the get_data method of PanDataSet class. The method will return a list of dataframes, one for each table in the dataset. You can then select the dataframe you want and convert it to a Series as we did before.
# ds = PanDataSet('10.1594/PANGAEA.619066')
# print(ds.title)
# print(ds.data.head())
from pyleotups import PangaeaDataset
ds = PangaeaDataset()
dfs = ds.get_data(619066) ## Directly pass the url to the pyleotups's PanageaDataset
ds = dfs[0]
print(ds.head())
[2026-03-13 12:33:17,128][INFO] - Study 619066 not previously registered. Loading ad hoc.
Age Mg/Ca Temp G. affinis δ18O δ18O H2O Event Latitude \
0 10.534 3.490 2.272 3.47 0.09 MD99-2334 37.801167
1 11.394 3.231 1.303 4.14 0.50 MD99-2334 37.801167
2 11.761 2.585 -1.498 3.77 -0.66 MD99-2334 37.801167
3 12.064 2.993 0.344 3.79 -0.12 MD99-2334 37.801167
4 12.368 2.786 -0.558 3.91 -0.25 MD99-2334 37.801167
Longitude Elevation Date/Time
0 -10.171333 -3166.0 1999-09-14
1 -10.171333 -3166.0 1999-09-14
2 -10.171333 -3166.0 1999-09-14
3 -10.171333 -3166.0 1999-09-14
4 -10.171333 -3166.0 1999-09-14
One can extract the dataset column names via:
ds.columns
Index(['Age', 'Mg/Ca', 'Temp', 'G. affinis δ18O', 'δ18O H2O', 'Event',
'Latitude', 'Longitude', 'Elevation', 'Date/Time'],
dtype='str')
type(ds['Temp'])
pandas.Series
As a pandas Series object, this variable has an associated plot method:
ds['Temp'].plot()
<Axes: >
However, we see that the x-axis knows nothing about time; indeed, PANGAEA services a dizzying array of dataset types, and their API has to be very general. This is one reason to have a Pyleoclim Series class that knows explicitly about time. Let us create an instance here, with proper metadata that are not available in the original, barebones PANGAEA format:
S07_temp = pyleo.Series(time=ds['Age'], value=ds['Temp'],
time_name='Age', time_unit='ka BP', verbose=False,
value_name='Temperature', value_unit=r'$^{\circ}$ C',
label = 'Skinner et al. (2007)')
S07_temp.plot()
(<Figure size 1000x400 with 1 Axes>,
<Axes: xlabel='Age [ka BP]', ylabel='Temperature [$^{\\circ}$ C]'>)
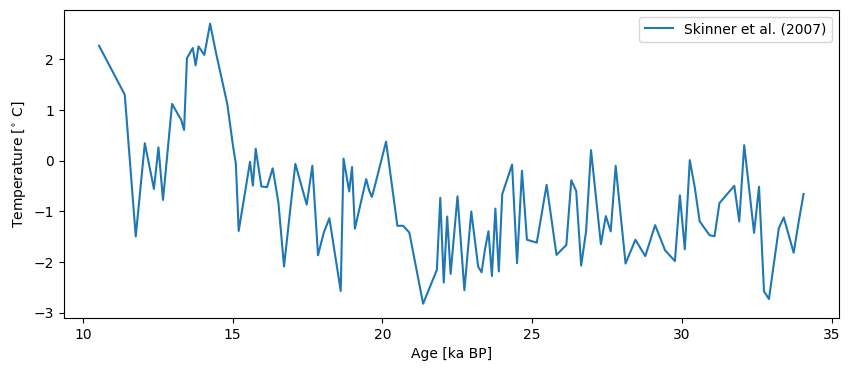
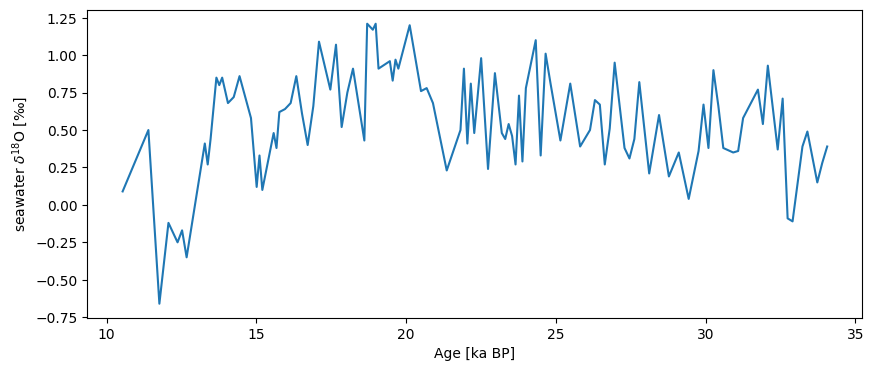
As of now, you can create this object manually, but we will soon automate this process to a large extent. Let us also load their reconstruction of seawater \(\delta^{18}\)O:
S07_d18Osw = pyleo.Series(time=ds['Age'], value=ds['δ18O H2O'],
time_name='Age', time_unit='ka BP', verbose=False,
value_name='seawater $\delta^{18}$O', value_unit='$\perthousand$')
S07_d18Osw.plot()
(<Figure size 1000x400 with 1 Axes>,
<Axes: xlabel='Age [ka BP]', ylabel='seawater $\\delta^{18}$O [$\\perthousand$]'>)
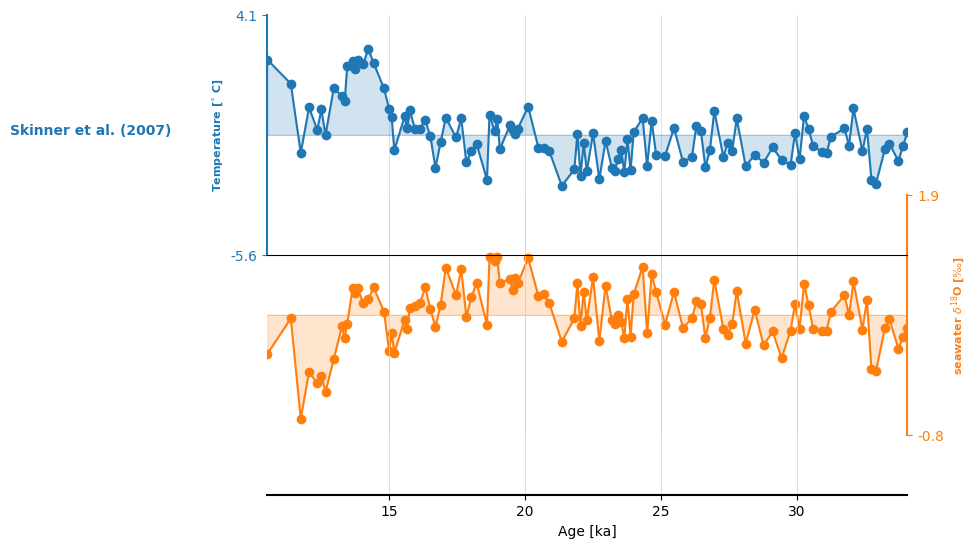
We can put both series into a MultipleSeries object, which unlocks fun features, like stackplot():
ms = S07_temp & S07_d18Osw
ms.stackplot(plot_kwargs={'marker':'o'})
(<Figure size 640x480 with 3 Axes>,
{0: <Axes: ylabel='Temperature [$^{\\circ}$ C]'>,
1: <Axes: ylabel='seawater $\\delta^{18}$O [$\\perthousand$]'>,
'x_axis': <Axes: xlabel='Age [ka]'>})
For more information on MultipleSeries, read the documentation and/or follow this tutorial.
Takeway#
There are multiple paths into Series, unlocking the full power of Pyleoclim to work with data originally stored in all manner of formats.
%watermark -n -u -v -iv -w
Last updated: Fri, 13 Mar 2026
Python implementation: CPython
Python version : 3.12.11
IPython version : 9.6.0
pandas : 3.0.1
pangaeapy: 1.1.0
pyleoclim: 1.3.1b0
pyleotups: 0.0.2b0
pylipd : 1.5.1
xarray : 2025.12.0
Watermark: 2.6.0