
Singular Spectrum Analysis with Pyleoclim#
Preamble#
Introduced by Broomhead & King, (1986), SSA is a method steeped in the theory of dynamical systems, designed specifically for the short and noisy timeseries that paleogeoscientists love so. (yes, even if a record reaches back to the precambrian, it is “short” if the number of points is less than a few hundred samples). SSA is based on a fundamental theorem due to Takens. Unlike Fourier or wavelet analysis, and like principal component analysis, SSA extracts patterns of variations from the data themselves (using an eigendecomposition of lagged copies of the timeseries) to extract eigenmodes (natural oscillating tones present in the series). It then projects the data onto these eigenmodes to achieve various things, like smoothing, interpolation, or decomposition. In effect, SSA replaces Fourier’s sines/cosines, or wavelet bases, by oscillations it pulls out of the data. The advantage is that those patterns came from the data, so they are (by construction) well suited to describing the data in question. The disadvantage is that some data must be sacrificed to find these patterns in the first place (unlike parametric methods like Fourier or wavelet analysis, where they are imposed). There is no free lunch!
Goals#
Learn the basics of SSA
Learn how to apply SSA in
PyleoclimUse SSA for three applications: reconstruction, filtering, and imputation of missing values (interpolation).
Reading Time: 15 min
Keywords#
Singular Spectral Analysis, Synthesis, Filtering, Imputation, Visualization
Pre-requisites#
None
Relevant Packages#
pandas, matplotlib
Data Description#
Sea-surface temperature from Kaplan (1998) averaged over the NINO3 (5N-5S, 150W-190E) region.
Demonstration#
Caveat emptor: like the vast majority of timeseries techniques, SSA assumes that the data are evenly-spaced. If you want to apply SSA to an unevenly-spaced series, you will need to cast it onto a regular time grid, using NaNs to signal missing values. Pyleoclim’s SSA implementation does allow modest amounts of missing values in the timeseries, though they should not be present in large contiguous blocks (see last section, below).
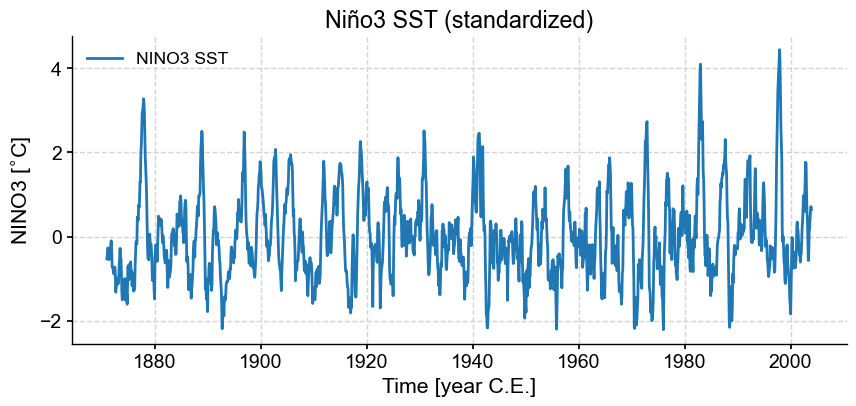
We start by importing relevant packages, loading and plotting the timeseries of interest (NINO3). To simplify matters, let’s standardize this timeseries (give it zero mean and unit standard deviation).
%load_ext watermark
import pyleoclim as pyleo
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
import numpy as np
ts_nino = pyleo.utils.load_dataset('NINO3')
ts_n = ts_nino.standardize()
fig, ax = ts_n.plot(title= 'Niño3 SST (standardized)')
Let us now apply SSA to this series. While SSA is non-parametric, it does rely on one crucial parameter, the embedding dimension, denoted \(M\), which describes the length of the time window over which SSA will hunt for oscillations. It has been shown that SSA can well identify oscillations with a period between \(M/5\) and \(M\). By default, pyleoclim will use a value of 10% of the timeseries, in this case 159 months. In order to focus on interannual modes, let’s use 60 months (5 years), in accord with Ghil et al (2002).
nino_ssa = ts_n.ssa(M = 60)
The output of this function is an SsaRes object, which includes a number of fields.
Let us now see how to make use of all these arrays. The first step is to inspect the eigenvalue spectrum (”scree plot”) to identify remarkable modes.
nino_ssa.screeplot()
(<Figure size 600x400 with 1 Axes>,
<Axes: title={'center': 'SSA scree plot'}, xlabel='Mode index $i$', ylabel='$\\lambda_i$'>)
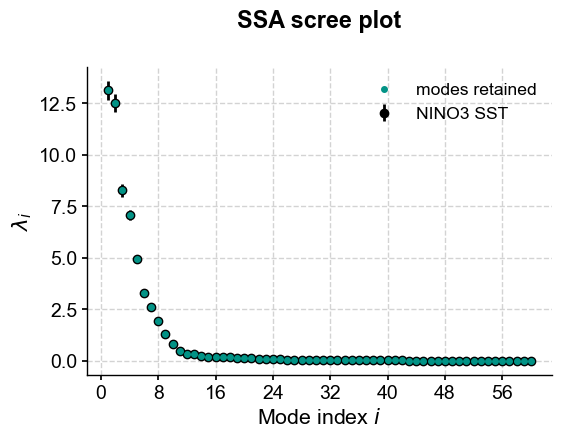
This highlights a few common phenomena with SSA:
the eigenvalues are in descending order
their uncertainties are proportional to the eigenvalues themselves
the eigenvalues tend to come in pairs : (0,1) (2,3), are all clustered within uncertainties.
around \(i=15\), the eigenvalues appear to reach a floor, and all subsequent eigenvalues explain a very small amount of variance.
Indeed, the variance explained by mode \(i\) is $\( v_i = \frac{\lambda_i}{\sum_{k=0}^{M} \lambda_k} \)\( where \)\lambda_{i}\( the eigenvalue corresponding to mode \)i$. So, summing the variance of all modes higher than 15, we get:
print(nino_ssa.pctvar[15:].sum())
4.112069865177367
That is, over 95% of the variance is in the first 15 modes; almost all of it in the first 10 modes. That is a typical result for a “warm-colored” timeseries, which is most geophysical timeseries; a few modes do the vast majority of the work. That means we can focus our attention on these modes and capture most of the interesting behavior. To see this, let’s use the reconstructed components (RCs), and sum the RC matrix over the first 10 columns:
RCk = nino_ssa.RCmat[:,:15].sum(axis=1)
fig, ax = ts_n.plot(title='NINO3 index')
ax.plot(ts_n.time,RCk,label='SSA reconstruction, 15 modes',color='orange')
ax.legend()
<matplotlib.legend.Legend at 0x1746aa770>
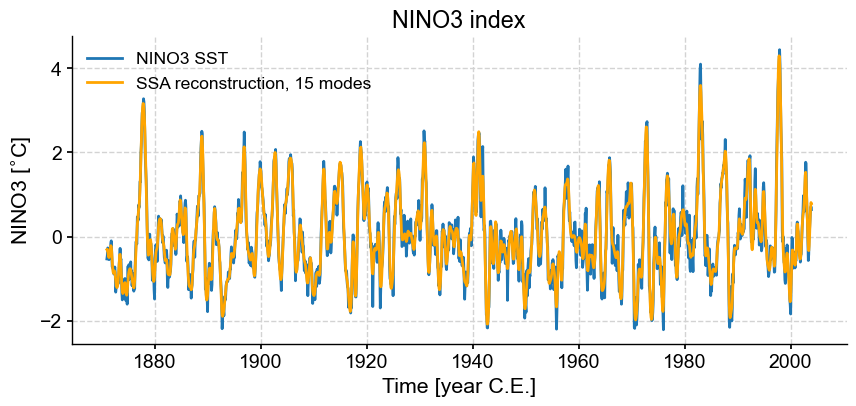
Indeed, these first few modes capture the vast majority of the low-frequency behavior, including all the El Niño/La Niña events. What is left (the blue wiggles not captured in the orange curve) are high-frequency oscillations that might be considered “noise” from the standpoint of ENSO dynamics. This illustrates how SSA might be used for filtering a timeseries. One must be careful however:
there was not much rhyme or reason for picking 15 modes. Why not 5, or 39? All we have seen so far is that they gather >95% of the variance, which is by no means a magic number.
there is no guarantee that the first few modes will filter out high-frequency behavior, or at what frequency cutoff they will do so. If you need to cut out specific frequencies, you are better off doing it with a classical filter (see filtering and detrending). However, in many instances the choice of a cutoff frequency is itself rather arbitrary. In such cases, SSA provides a principled alternative for generating a version of a timeseries that preserves features and excludes others (i.e, a filter).
as with all orthogonal decompositions, summing over all RCs will recover the original signal within numerical precision.
Monte-Carlo SSA#
Selecting meaningful modes in eigenproblems like SSA or PCA is more art than science. However, one technique stands out here: Monte Carlo SSA, introduced by Allen & Smith, (1996) to identiy SSA modes that rise above what one would expect from “red noise”, specifically an AR(1) process. To run it, simply provide the parameter \(MC\), ideally with a number of iterations sufficient to get decent statistics. Here’s let’s use \(MC = 1000\). The result will be stored in the eigvals_q array, which has the same length as eigvals, and its two columns contain the 5% and 95% quantiles of the ensemble of MC-SSA eigenvalues.
nino_mcssa = ts_n.ssa(M = 60, nMC=1000)
Now let’s look at the result:
nino_mcssa.screeplot()
(<Figure size 600x400 with 1 Axes>,
<Axes: title={'center': 'SSA scree plot'}, xlabel='Mode index $i$', ylabel='$\\lambda_i$'>)
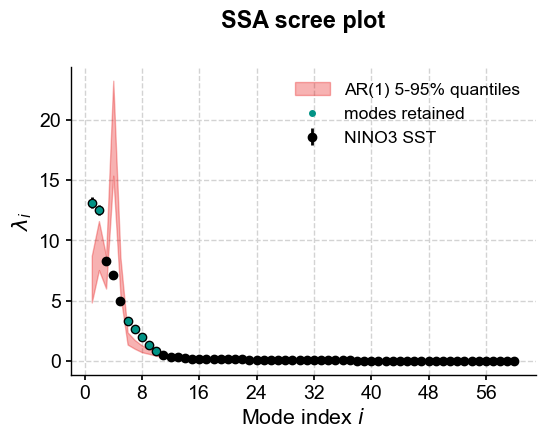
The screeplot method was able to make use of this new information and added a red noise background spectrum (in red, naturally). The plot suggests that modes 1, 2 and 6 to 10 fall above the red noise benchmark. More precisely, one may extract those modes using mode_idx:
nino_mcssa.mode_idx
array([0, 1, 5, 6, 7, 8, 9])
Pursuant to Python’s 0-based indices, this vector of indices is 0-based. However, to conform to standard usage, the modes are referred to by their ordinal (i.e. index \(i\) corresponds to mode \(i+1\)). Let us zoom in on those modes, and use them for pre-filtering prior to spectral analysis.
SSA pre-filtering#
Let’s first look at the spectrum of the raw index, using two methods included in Pyleoclim: the Multi-Taper Method (MTM) and the Weighted Wavelet Z transform (WWZ). A tutorial on pyleoclim’s spectral methods may be found here.
psd_mtm = ts_n.interp().spectral(method='mtm', settings={'NW': 2})
psd_wwz = ts_n.spectral(method='wwz', settings={'freq':psd_mtm.frequency}) # pass the frequency vector to compare apples to apples
fig, ax = psd_wwz.plot(label='WWZ', zorder=99)
ax = psd_mtm.plot(ax=ax, label='MTM')
OMP: Info #276: omp_set_nested routine deprecated, please use omp_set_max_active_levels instead.
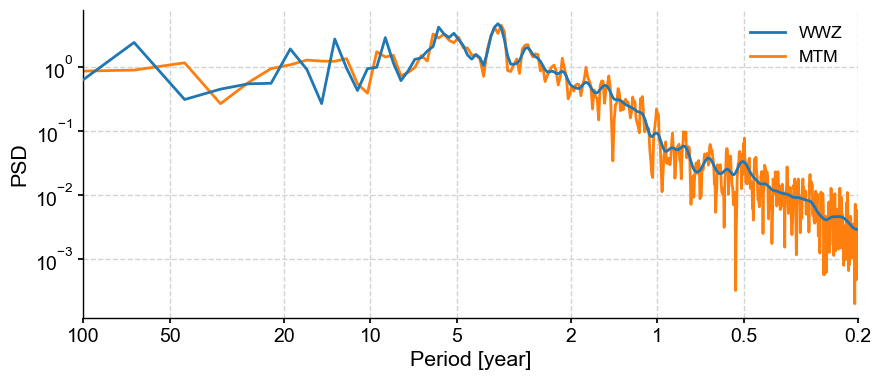
Here we see clear interannual peaks, particular the quasi-quadriennial one (around 4 years, as the name implies). MTM with default parameters smoothes out the decadal-to-centennial part of the spectrum, but produces a lot of peaks at periods shorter than 2 years. In contrast, WWZ smoothes out these high-frequency features, but shows peaks in the decadal range that MTM, certainly, does not see. Would pre-filtering NINO3 using the most robust SSA modes help with that? Also, are each of the interannual peaks carried by individual oscillations that a linear method like SSA could separate?
To answer these questions, let’s inspect those key modes with the modeplot function, which shows the corresponding T-EOF, RC, and spectra. First, mode 1 (remember that index = mode - 1).
fig,ax=nino_mcssa.modeplot(index=0)
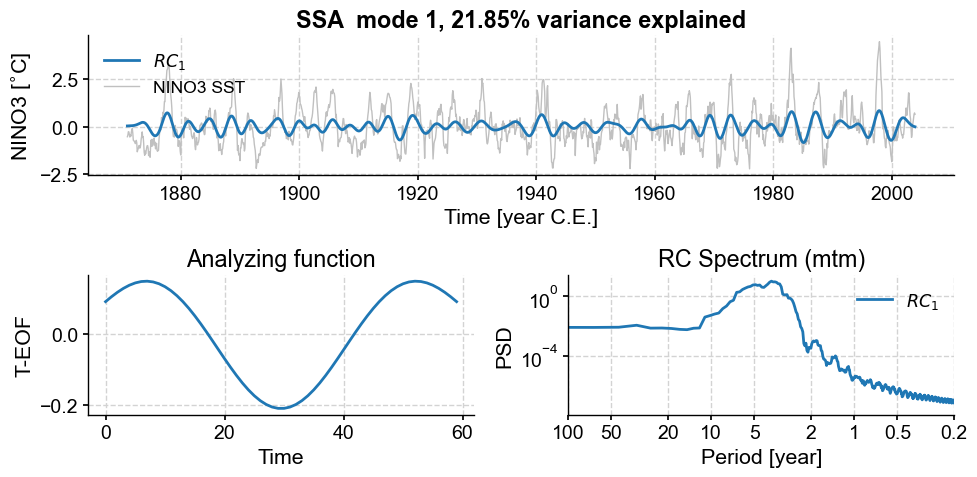
This first mode, with ~22% of the variance, is associated with a nearly pure sinusoid with a period near 48 months. The two peaks near 0.2 years are strange, and in need of an explanation. Now mode 2:
nino_mcssa.modeplot(index=1)
(<Figure size 1000x500 with 3 Axes>,
<Axes: title={'center': 'RC Spectrum (mtm)'}, xlabel='Period [year]', ylabel='PSD'>)
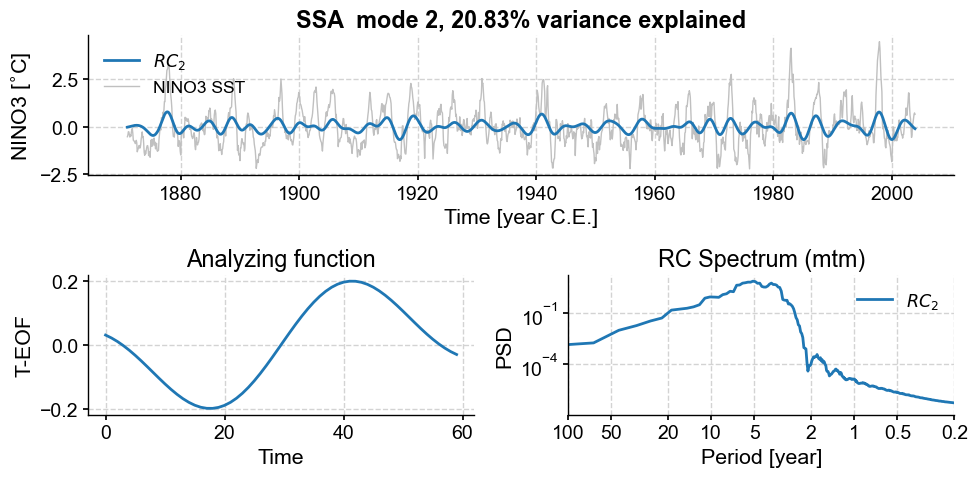
Mode 2 has a nearly equal variance and similar spectral signature as mode 1, consistent with those two modes being part of a pair. Its T-EOF is (by construction) orthogonal to that of mode 1, and one may think of them as a sine/cosine pair for this particular oscillation around 4 years. Together, they account for about 2/3 of the total variance. What about modes 6 to 9?
nino_mcssa.modeplot(index=5)
nino_mcssa.modeplot(index=6)
(<Figure size 1000x500 with 3 Axes>,
<Axes: title={'center': 'RC Spectrum (mtm)'}, xlabel='Period [year]', ylabel='PSD'>)
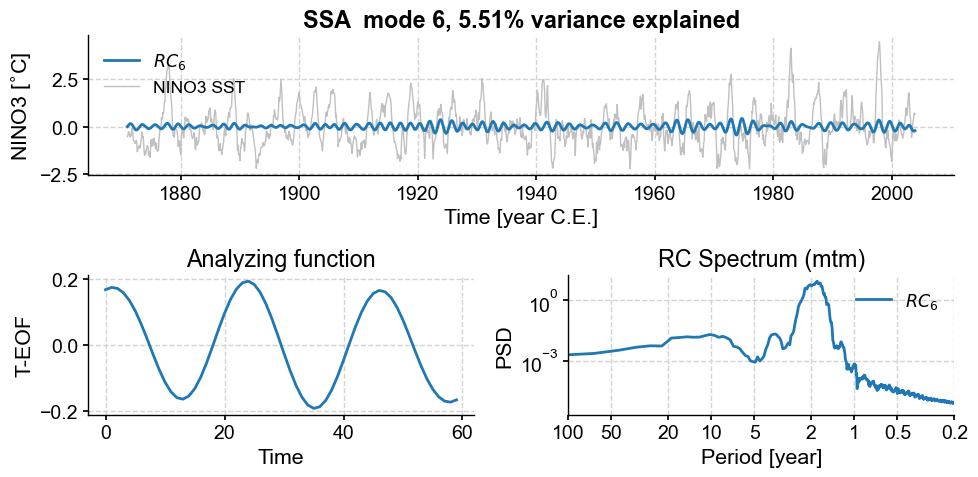
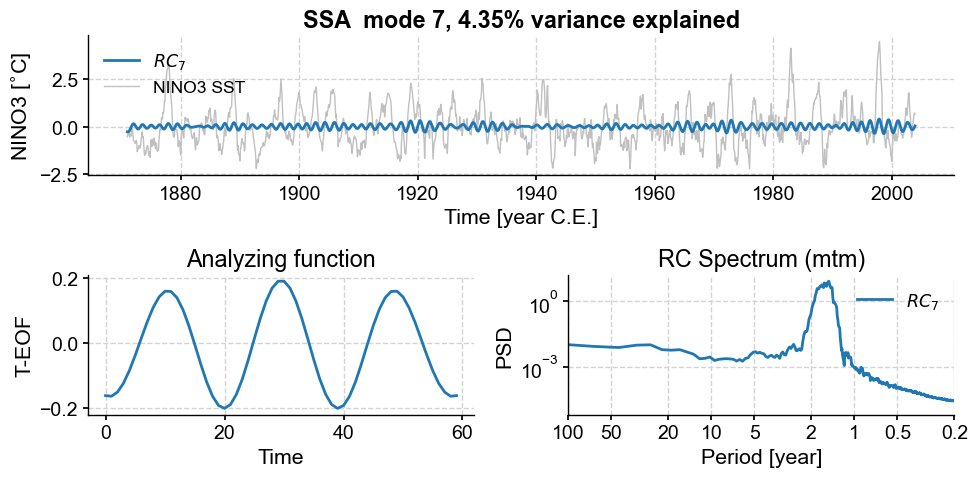
Modes 6 and 7 are associated with oscillations around 2 years, though the peaks are again fairly broad, indicative of low-frequency modulation (as evidenced in the envelope of these ~2y cycles). To refine the spectral estimate for these features, one could:
play with the time-bandwidth product (\(N_W\)) of MTM.
apply other techniques better suited to detecting narrow-band peaks (e.g. Burg’s method).
apply yet other methods suited for nonlinear and non-stationary signals, like the Hilbert-Huang Transform.
Such is not our purpose, so we move instead to prefiltering using the modes identified above.
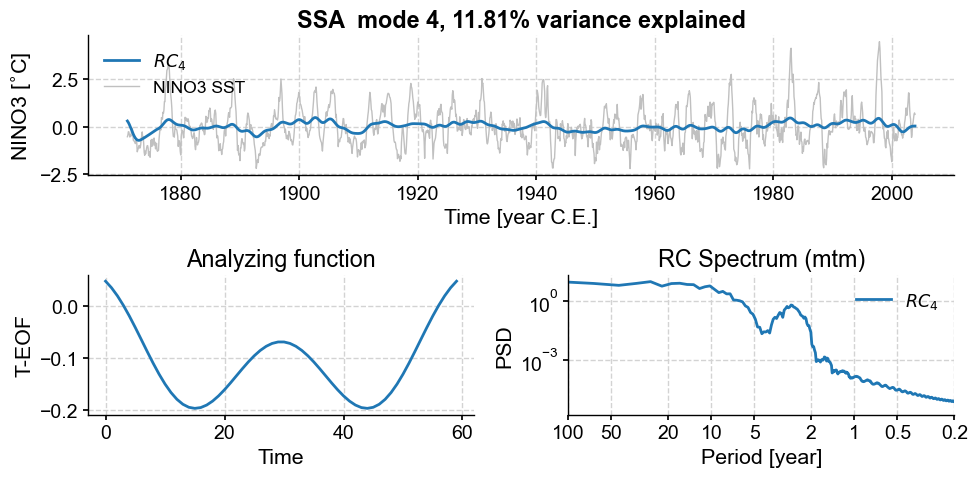
Finally, modes 8 and 9:
nino_mcssa.modeplot(index=7)
nino_mcssa.modeplot(index=8)
(<Figure size 1000x500 with 3 Axes>,
<Axes: title={'center': 'RC Spectrum (mtm)'}, xlabel='Period [year]', ylabel='PSD'>)
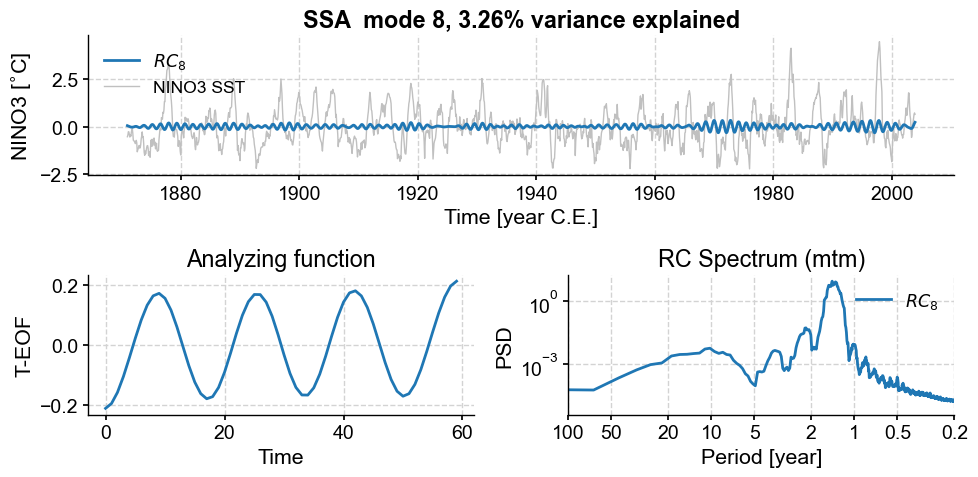
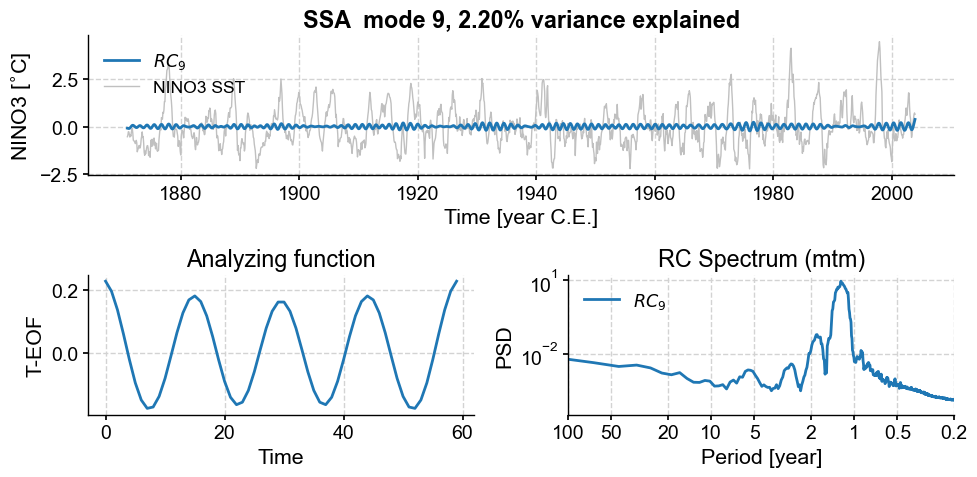
Those also have a nearly harmonic (sinusoidal) structure, with a shorter period between 1 and 2 years. Again, they seem to form a pair. Overall, we see that, as we go up the ranks, the period of oscillation diminishes, as does the variance (by construction). That is again a common property of geophysical timeseries, which tend to be “warm colored” (more spectral energy at lower frequencies).
Now let’s plot the reconstructed series (RCseries), which gathers all the retained modes. It is a Pyleoclim Series, which makes it easy to plot and manipulate:
type(nino_mcssa.RCseries)
pyleoclim.core.series.Series
fig, ax = ts_n.plot(title='MC-SSA reconstruction') # we mute the first call to only get the plot with 2 lines
nino_mcssa.RCseries.plot(label='MC-SSA modes '+str(nino_mcssa.mode_idx+1),color='orange',ax=ax)
ax.legend()
<matplotlib.legend.Legend at 0x175815ba0>
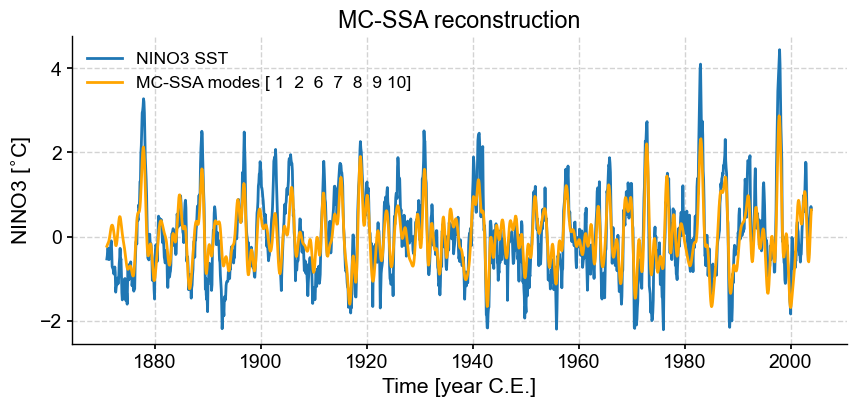
What was in the modes excluded by MC-SSA, you ask? Let’s have a look.
nino_mcssa.modeplot(index=1)
nino_mcssa.modeplot(index=2)
nino_mcssa.modeplot(index=3)
(<Figure size 1000x500 with 3 Axes>,
<Axes: title={'center': 'RC Spectrum (mtm)'}, xlabel='Period [year]', ylabel='PSD'>)
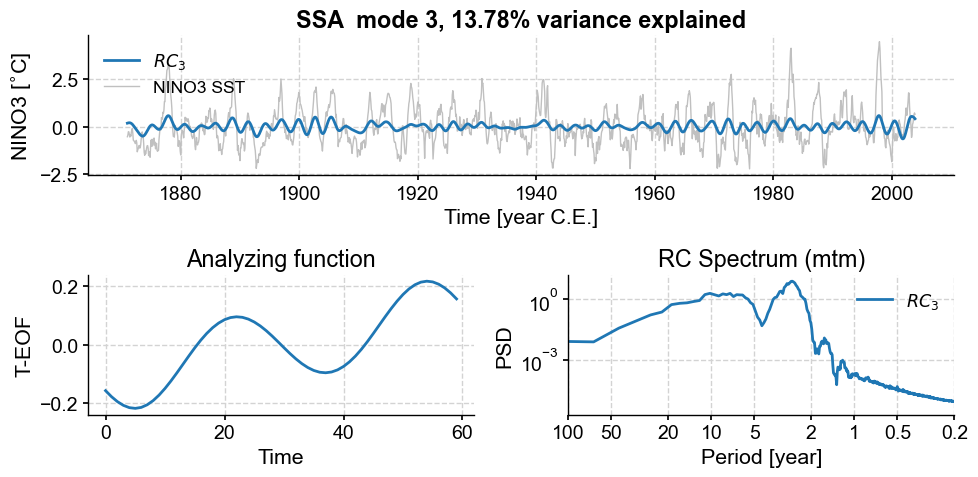
Those modes contained a lot of low-frequency signals (compare their spectra to those of the other modes), some associated with trends in variance. However, MC-SSA found that these signals do not stand out compared to red noise, so it left them out. Note that with different choices of embedding dimension (\(M\)), different modes will capture different features.
However, it is generally true over a broad range of choices that the MC-SSA modes capture most of the features of interest, including the various ENSO events. Let us now perform spectral analysis on a version of the timeseries that includes only those modes:
psd_mtm = nino_mcssa.RCseries.interp().spectral(method='mtm', settings={'NW': 2}) # apply MTM spectral analysis
fig, ax = psd_mtm.plot(label='SSA-filtered NINO3', color='orange') # plot it
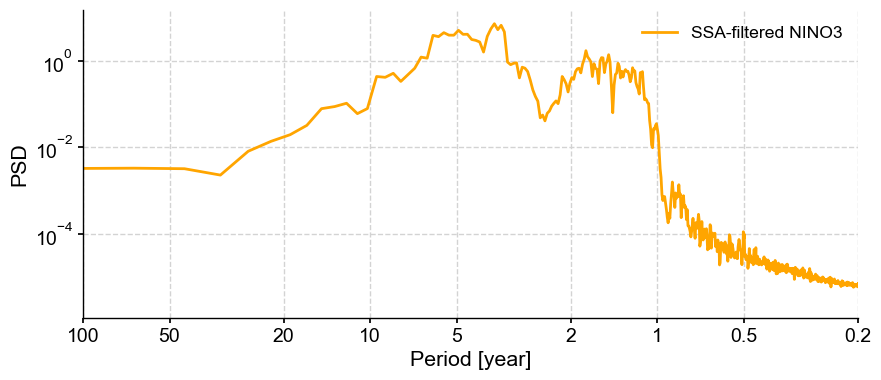
We see indeed the variance concentrated in the interannual range, 1 to 8 years. The signal is overall much cleaner than before, illustrating the beneficial effects of SSA to filter signals of interest prior to applying spectral analysis.
SSA with missing values#
A useful feature of the pyleoclim implementation of SSA is the ability to deal with missing values, which is particularly critical in the paleosciences, where data are seldom sampled at regular time intervals.
It turns out that SSA can also be applied on timeseries that contain a reasonable amount of missing data, thanks to the work of Schoellhamer (2001). To illustrate this, we simply dig some holes in the NINO3 series, apply SSA, and compare the results for various fractions of missing values.
t = ts_n.time
n = len(t)
fm = 0.1 #fraction of missing values
missing = np.random.choice(n,np.floor(fm*n).astype('int'),replace=False)
fig, ax = ts_n.plot(title='NINO3 SST Anomalies',label='original')
ax.plot(t[missing],ts_n.value[missing],'rx',label='deleted')
ax.legend()
<matplotlib.legend.Legend at 0x177f49c90>
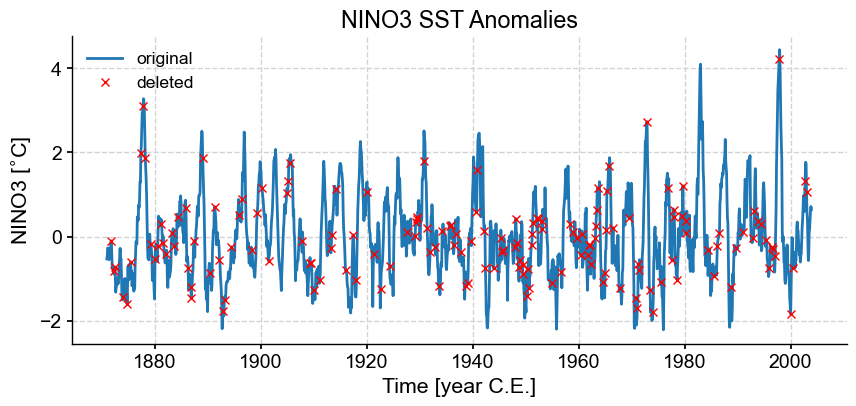
Now let’s apply SSA to the incomplete data (blue minus red)
nino_miss = np.copy(ts_n.value)
nino_miss[missing] = np.nan # put NaNs at the randomly chosen locations
ts_miss = pyleo.Series(time=t,value=nino_miss, dropna=False)
miss_ssa = ts_miss.ssa(M = 60, trunc='var',var_thresh=95)
Time axis values sorted in ascending order
RCmiss = miss_ssa.RCmat[:,:9].sum(axis=1)
RCmiss_series = pyleo.Series(t,RCmiss)
fig, ax = ts_nino.plot(title='NINO3 index') # we mute the first call to only get the plot with 2 lines
RCmiss_series.plot(ax=ax,label=f'gappy SSA reconstruction, $k=10$',color='orange')
Time axis values sorted in ascending order
<Axes: title={'center': 'NINO3 index'}, xlabel='Time [years CE]', ylabel='value'>
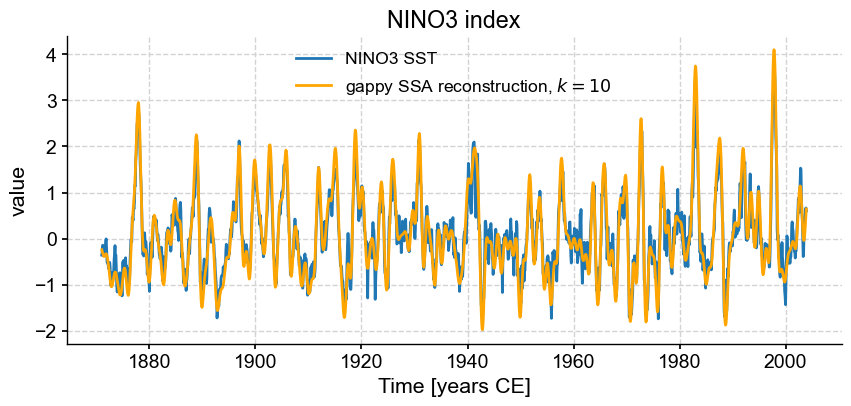
We see that, despite missing 10% of the values, a low-order (20 mode) SSA synthesis is able to successfully capture the behavior of the original timeseries, much as it did before. Two questions: what happens if we use more or fewer modes? And what would happen with larger fractions of missing values? Let’s find out.
First, we truncate the SSA expansion so it includes only modes that include 95% of the variance. This is set with trunc='var',var_thresh=95 above, and the result is:
fig, ax = ts_nino.plot(title='NINO3 index') # we mute the first call to only get the plot with 2 lines
miss_ssa.RCseries.plot(ax=ax,label=r'gappy SSA reconstruction, 95% variance',color='orange')
<Axes: title={'center': 'NINO3 index'}, xlabel='Time [years CE]', ylabel='value'>
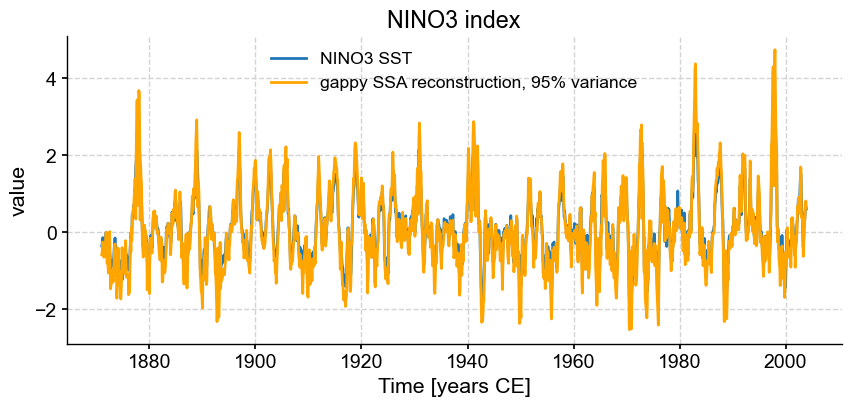
The series is quite noisy, which is a sign that we might have retained too many modes. Let’s instead use another method (see below), that finds the “knee” of the scree plot:
knee_ssa = ts_miss.ssa(M = 60, trunc='knee')
fig, ax = ts_nino.plot(title='NINO3 index')
knee_ssa.RCseries.plot(ax=ax,label=r'gappy SSA reconstruction, knee-finding method',color='orange')
<Axes: title={'center': 'NINO3 index'}, xlabel='Time [years CE]', ylabel='value'>
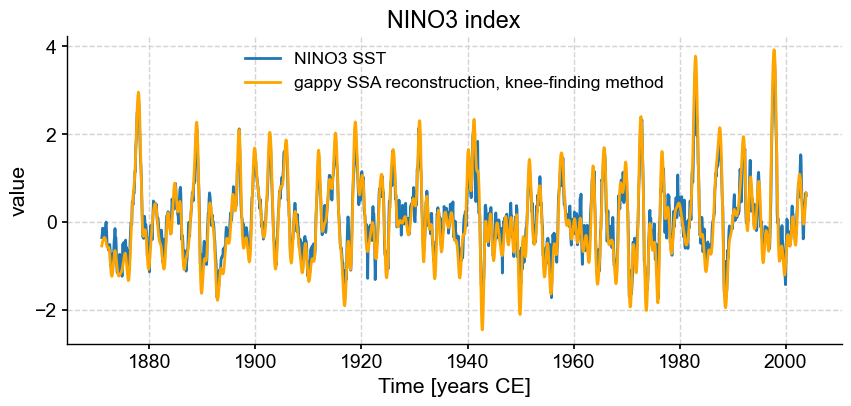
This is OK, but as we apply this to increasingly sparse versions of the series, it may still retain too much information. Let’s use a conservartive approach that retains only 60% of the total variance:
fmiss = [.2, .3, .4, .5, .6]
for fm in fmiss:
missing = np.random.choice(n,np.floor(fm*n).astype('int'),replace=False)
nino_miss = np.copy(ts_n.value)
nino_miss[missing] = np.nan
ts_miss = pyleo.Series(time=t,value=nino_miss, dropna=False, verbose=False)
miss_ssa = ts_miss.ssa(M = 60, trunc='var',var_thresh=60)
fig, ax = ts_nino.plot(title=r'SSA reconstruction with '+ str(fm*100) +'% missing values',label='target')
miss_ssa.RCseries.plot(ax=ax,label='SSA recon, 60% var',color='orange', linewidth=1)
ax.legend()
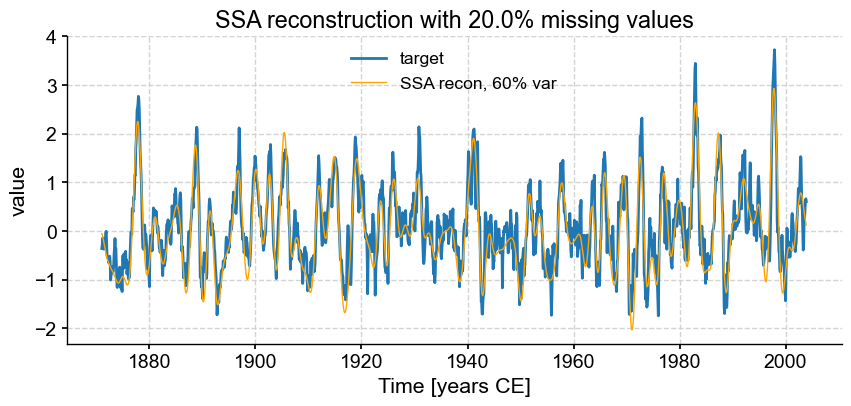
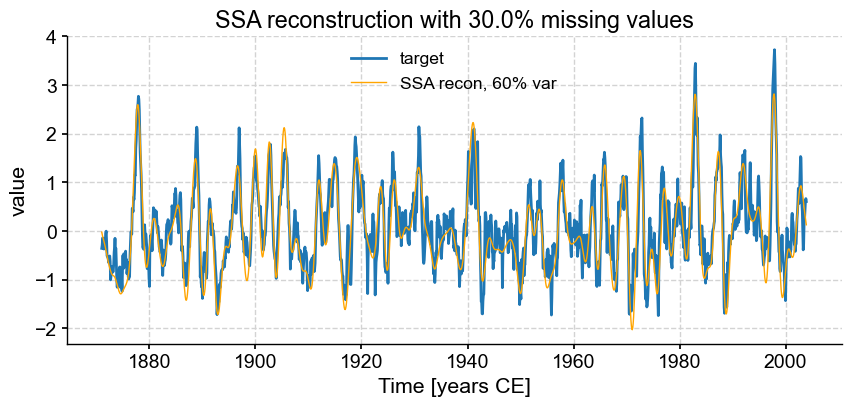
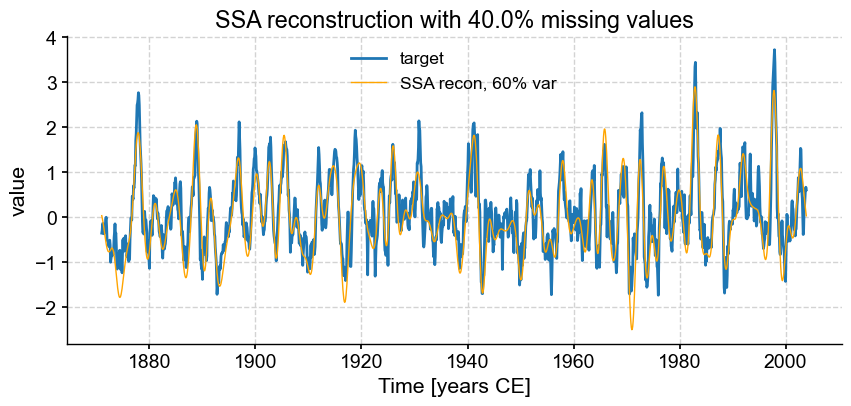
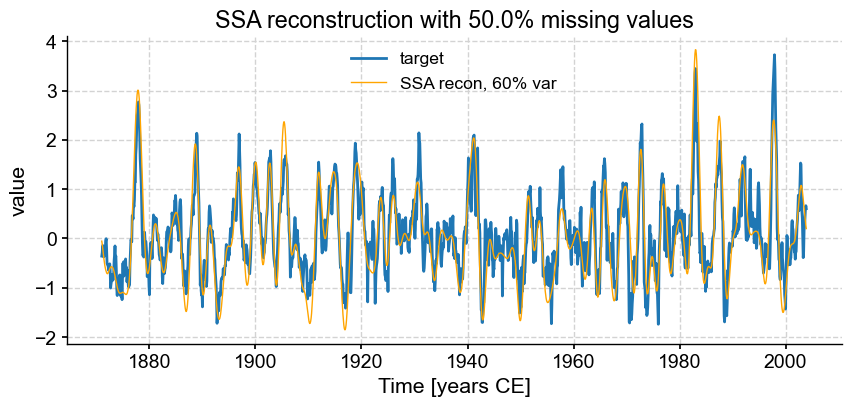
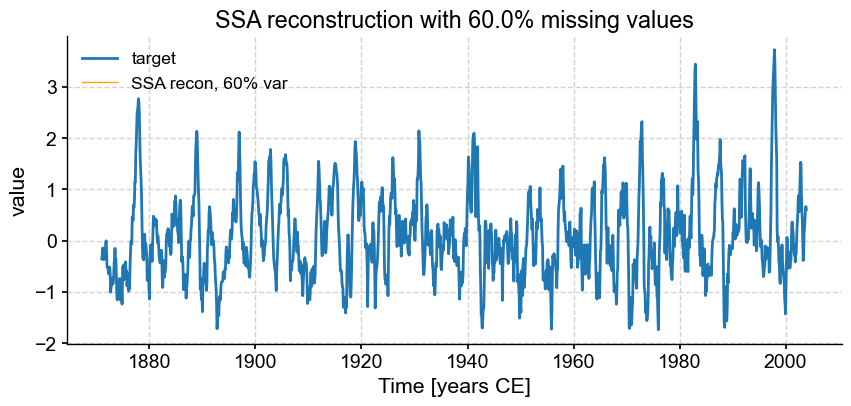
We see that SSA still does a respectable job with only half the points (\(f = .50\)), however the reconstruction breaks down for \(f = 0.6\). Using different truncation methods might mitigate this, but we can’t expect miracles: trying to reconstruct such a complex signal based on fewer samples than that is asking for trouble. In fact, it’s already rather impressive that SSA can extract so much information from so little data. That is a testimony to the idea that most communication is redundant, which is the basis of compression, used so ubiquitously in the digital world (think mp3 audio files, jpeg photographs, etc). You may in fact think of this SSA reconstruction as a form of data compression.
Now, this data compression is a lot easier when the data are missing at random, as was the case here. If we were to take out a contiguous chunk of the data , things would go sour very fast. Let’s see that by taking out the second quarter of the series:
missing = np.arange(np.floor(n/4),np.floor(n/2),dtype='int')
nino_miss = np.copy(ts_n.value)
nino_miss[missing] = np.nan
ts_miss = pyleo.Series(time=t,value=nino_miss,dropna=False,verbose=False)
miss_ssa = ts_miss.ssa(M = 60, trunc='knee')
fig, ax = ts_nino.plot(title=r'SSA reconstruction with missing second quarter',label='monthly NINO3')
miss_ssa.RCseries.plot(ax=ax,label='SSA recon, knee',color='orange', linewidth=1)
ax.legend()
<matplotlib.legend.Legend at 0x1c96cace0>
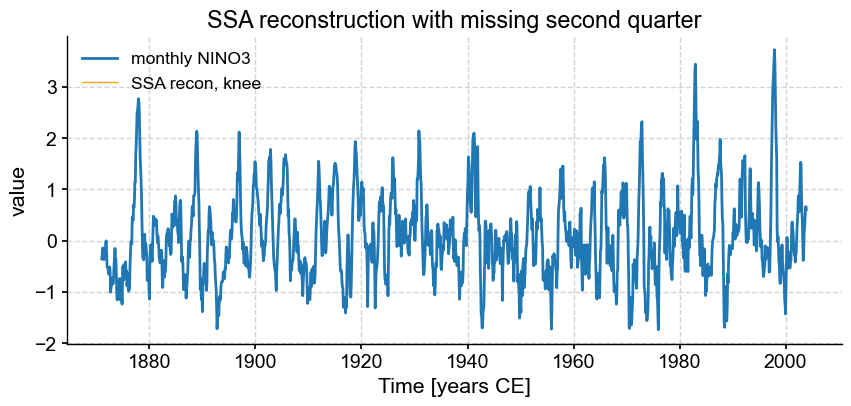
miss_ssa.RCseries
{'label': 'SSA reconstruction (knee)'}
None
Time [years CE]
1871.000000 NaN
1871.083333 NaN
1871.166667 NaN
1871.250000 NaN
1871.333333 NaN
..
2003.583333 NaN
2003.666667 NaN
2003.750000 NaN
2003.833333 NaN
2003.916667 NaN
Name: value, Length: 1596, dtype: float64
Here, the missing 25% could not be inferred, so SSA simply it left it out, and the reconstructed series is full of NaNs.
In summary, SSA may be used for interpolation (that is, the imputation of missing values): instead of traditional methods like polynomial interpolation, it provides an alternative that leverages the underlying oscillatory components of the timeseries. However, the method cannot perform miracles, and works best when data are missing in non-contiguous blocks. At present, it does not provide error estimates around interpolated values, though one could imagine generalizations that do. Methods such as these might be helpful.
SSA approximation#
Like all decomposition methods, SSA may be used to obtain approximations to the original data, often with the idea of filtering out noise. We’ve already seen how Monte Carlo SSA can be used for selecting modes that stand out against an AR(1) null. Pyleoclim also implements three simpler (and computationally lighter) options: the Kaiser rule, a criterion on retained variance (which we used just above; the amount of variance retained is dictated by the parameter var_thresh), and a knee finding method. The Kaiser rule (sometimes called Kaiser-Guttman rule) asserts that the modes that matter are those whose eigenvalue is above the mean (or median) of the eigenvalues. The knee finding method asserts that modes above the “knee” in the screeplot are significant. Let us compare these three criteria:
kaiser = ts_n.ssa(M = 60, trunc = 'kaiser')
mc_ssa = ts_n.ssa(M = 60, trunc = 'mcssa',nMC=400)
var = ts_n.ssa(M = 60, trunc = 'var', var_thresh=95)
knee = ts_n.ssa(M = 60, trunc = 'knee')
The reconstructed series is stashed away into the RCseries variable; let us look at the retained modes and what that yields for us in the RCseries with each of these truncation methods:
Kaiser method#
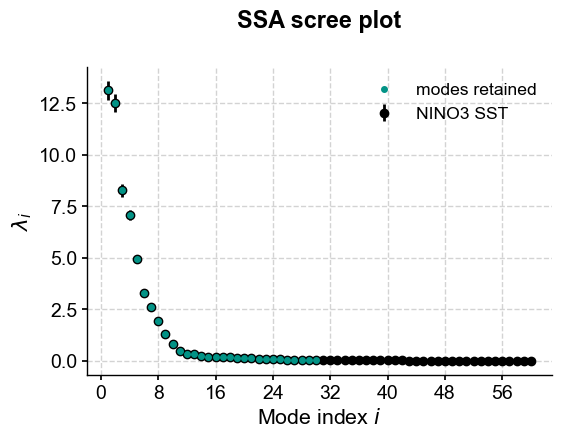
Kaiser’s criterion retains 50% of the modes, regardless of their importance:
kaiser.screeplot()
(<Figure size 600x400 with 1 Axes>,
<Axes: title={'center': 'SSA scree plot'}, xlabel='Mode index $i$', ylabel='$\\lambda_i$'>)
We’ll look at a slice of the NINO record in order to get a sense as to what this means for our reconstructed series.
fig,ax=ts_n.slice((1900,1920)).plot(figsize=(16,8),label='Original')
kaiser.RCseries.slice((1900,1920)).plot(ax=ax,label='SSA, Kaiser truncation')
ax.set_title('SSA reconstruction using Kaiser truncation method')
Text(0.5, 1.0, 'SSA reconstruction using Kaiser truncation method')
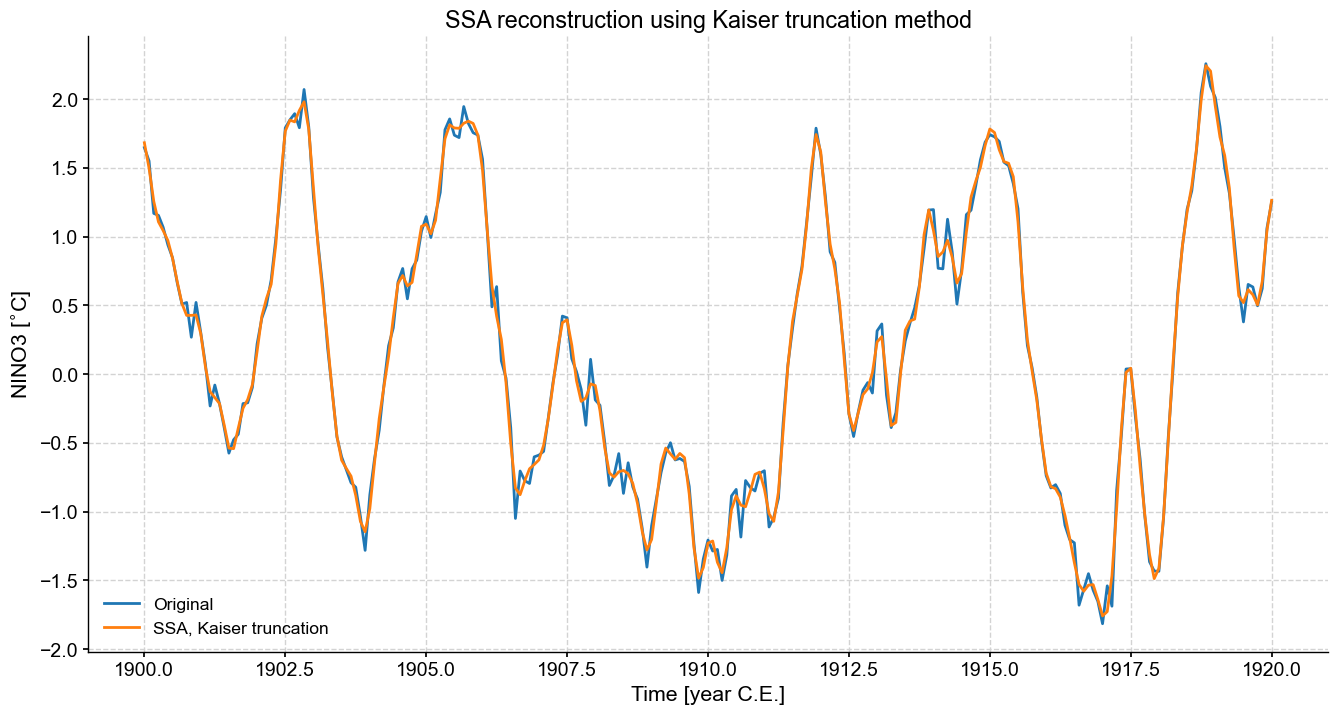
We can see the effect of retaining too many modes, we’ve essentially just returned the original series. Some smoothing has occurred, but a fair amount of high frequency, low variance behavior is retained. Sometimes this is desirable, sometimes not.
Variance thresholding method#
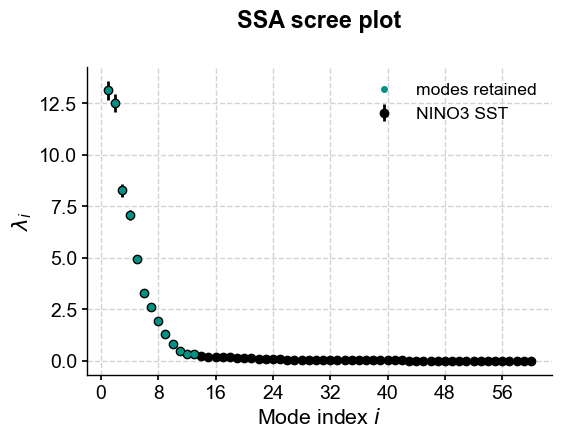
As seen before, this method retains the first \(k\) modes that account for a specified fraction of variance (here, 95%, adjustable through the var_thresh parameter).
var.screeplot()
(<Figure size 600x400 with 1 Axes>,
<Axes: title={'center': 'SSA scree plot'}, xlabel='Mode index $i$', ylabel='$\\lambda_i$'>)
If we want to hone in on a “reasonable” number of modes, we’ll need to use trial and error. We’ll humour the var method defaults here.
fig,ax=ts_n.slice((1900,1920)).plot(figsize=(16,8),label='Original')
var.RCseries.slice((1900,1920)).plot(ax=ax,label='SSA, var thresh = 95%')
ax.set_title('SSA reconstruction using variance threshold truncation method')
Text(0.5, 1.0, 'SSA reconstruction using variance threshold truncation method')
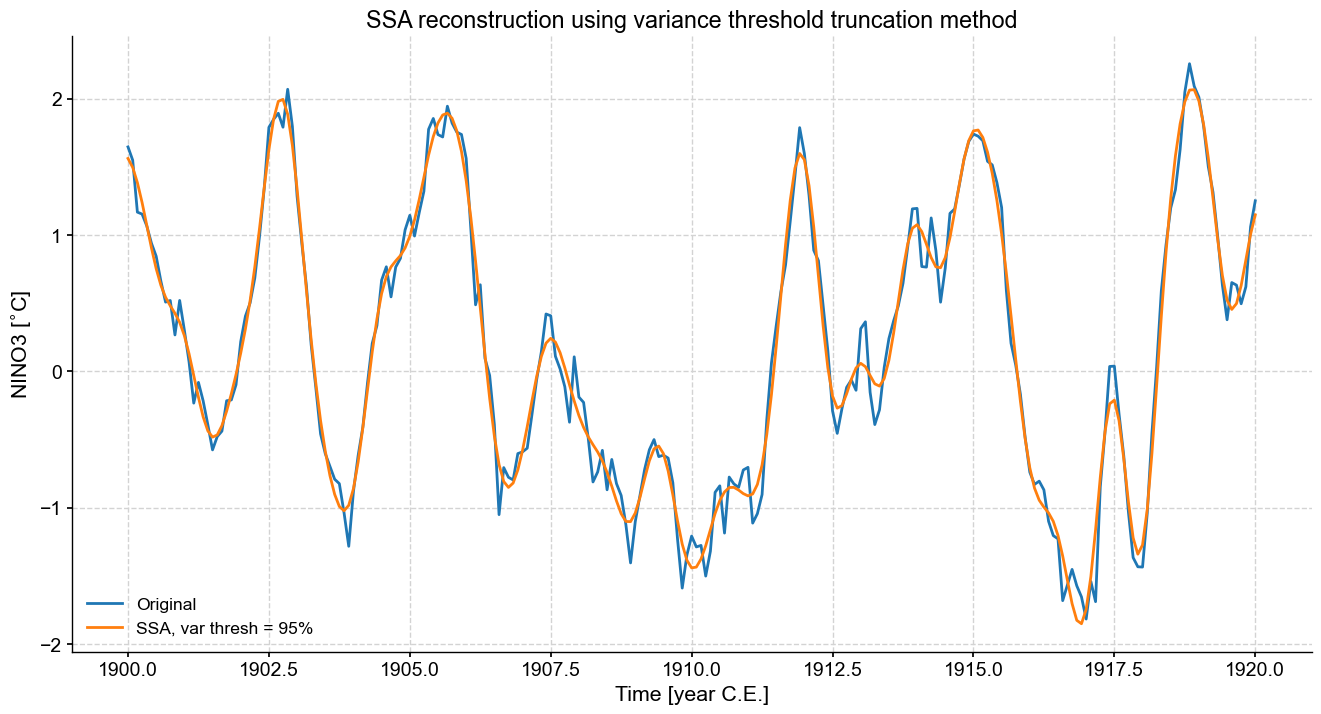
This is a bit smoother than Kaiser, because we retained quite a bit fewer modes.
Knee finding method#
As mentioned above, one can also pick the knee of the scree plot:
knee.screeplot()
(<Figure size 600x400 with 1 Axes>,
<Axes: title={'center': 'SSA scree plot'}, xlabel='Mode index $i$', ylabel='$\\lambda_i$'>)
Of the three methods described above, this is certainly the closest we’ve gotten to identifying what we might consider to be significant SSA modes on the first run around. Let’s see what the series looks like.
fig,ax=ts_n.slice((1900,1920)).plot(figsize=(16,8),label='Original')
knee.RCseries.slice((1900,1920)).plot(ax=ax,label='SSA, knee')
ax.set_title('SSA reconstruction using knee finding truncation method')
Text(0.5, 1.0, 'SSA reconstruction using knee finding truncation method')
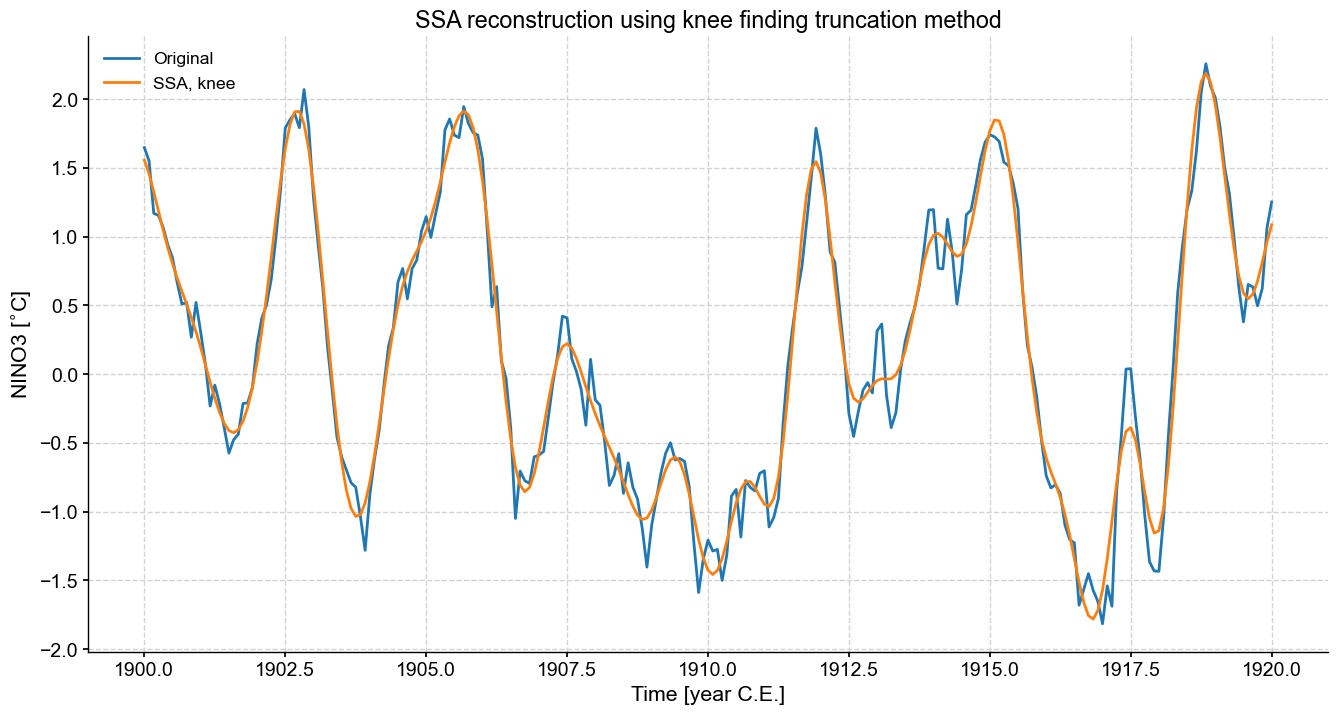
This is a nice result. It straddles the boundary between the Kaiser method’s adherence to the original record and the variance thresholding method’s smoothing of the original time series. If the goal is to enhance the S/N ratio and reconstruct a smooth version of the attractor’s skeleton, then the knee-finding method is a good compromise between objectivity and efficiency.
Let’s compare those three truncation criteria on the same plot, together with MC-SSA:
fig, ax = ts_nino.plot(title=r'SSA approximations',label='original',figsize=(16,8))
alp=.5
kaiser.RCseries.plot(ax=ax,label='Kaiser rule',alpha=alp,linewidth=1)
mc_ssa.RCseries.plot(ax=ax,label='MC SSA',alpha=alp,linewidth=1)
var.RCseries.plot(ax=ax,label='95% variance',alpha=alp,linewidth=1)
knee.RCseries.plot(ax=ax,label='Knee finding',alpha=alp,linewidth=1)
ax.legend()
<matplotlib.legend.Legend at 0x1c8ee6c80>
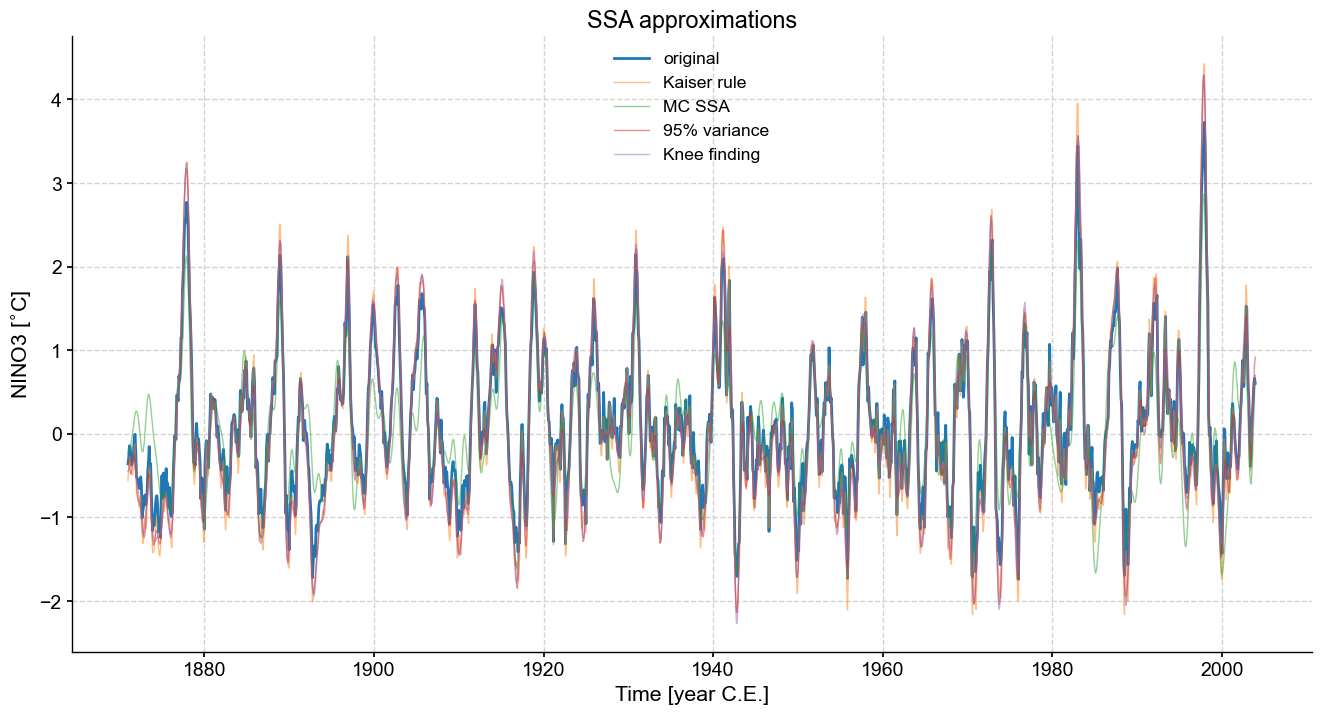
One can see that the various methods come out with comparable approximations to the original series, all tending to smooth out high-frequency oscillations. One caveat is that such approximations do not preserve variance, so this should be kept in mind in case variance matters to your analysis. The variance threshold is arbitrary, making it hard to justify, and the Kaiser-Guttman rule is not rooted in much theory, though it can work reasonably well in practice. The knee-finding method seems to be the most robust so far, though it also has little theory backing it up. However, if we were to impose a default truncation method, it would likely be this one.
There would be other truncation criteria, like Equation 26 in Nadakuditi & Edelman (2008), which have yet to be implemented. Lastly, if you wanted to be quantitative about those differences, you could evaluate RMS residuals:
for method in ['kaiser','mc_ssa','var','knee']:
res_norm = np.linalg.norm(eval(method).RCseries.value-ts_nino.value)
print(f'the residual between {method} and NINO3 is {res_norm:3.2f}')
the residual between kaiser and NINO3 is 8.53
the residual between mc_ssa and NINO3 is 16.82
the residual between var and NINO3 is 10.22
the residual between knee and NINO3 is 10.67
Summary#
SSA can do a lot for you. Give it a try!
%watermark -n -u -v -iv -w
Last updated: Mon Mar 04 2024
Python implementation: CPython
Python version : 3.11.7
IPython version : 8.20.0
matplotlib: 3.8.2
pandas : 2.1.4
numpy : 1.26.3
pyleoclim : 0.13.1b0
Watermark: 2.4.3